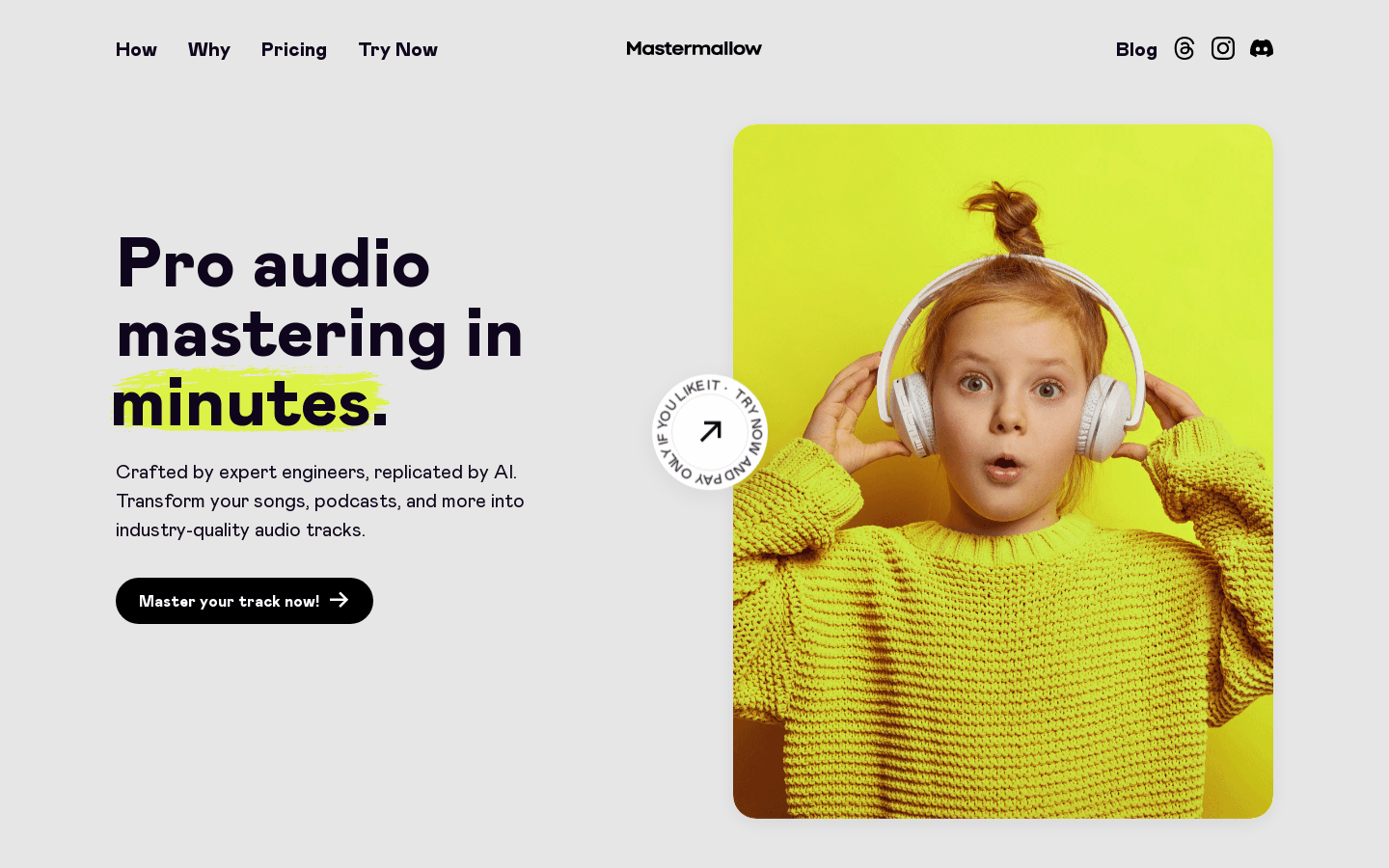
tulu-3-sft-olmo-2-mixture简介概述
allenai/tulu-3-sft-olmo-2-mixture是一个大规模的多语言数据集,包含了用于训练和微调语言模型的多样化文本样本。该数据集的重要性在于它为研究人员和开发者提供了丰富的语言资源,以改进和优化多语言AI模型的性能。产品背景信息包括其由多个来源的数据混合而成,适用于教育和研究领域,且遵循特定的许可协议。
需求人群:
"目标受众为自然语言处理领域的研究人员、开发者和教育工作者。他们可以利用这个数据集来训练和测试多语言AI模型,改进模型在不同语言和文化背景下的表现和准确性。"
使用场景示例:
研究人员使用该数据集训练一个能够理解和生成多种语言文本的AI模型。
开发者利用数据集中的样本来优化他们的聊天机器人,使其能够更好地服务于多语言用户。
教育机构使用该数据集作为教材,教授学生如何使用和分析大规模语言数据。
产品特色:
包含939,344个样本,覆盖多种语言和任务。
数据集来源于多个不同的数据集,如CoCoNot、FLAN v2、No Robots等。
适用于训练和微调语言模型,特别是在多语言环境下。
数据集结构包含id、messages、source等标准指令调整数据点。
支持研究和教育用途,符合Ai2的负责任使用指南。
包含输出数据,这些数据由第三方模型生成,受其单独的条款管辖。
数据集在Hugging Face平台上可被直接访问和使用。
使用教程:
1. 访问Hugging Face平台并搜索allenai/tulu-3-sft-olmo-2-mixture数据集。
2. 阅读数据集的描述和使用许可,确保符合研究或教育目的。
3. 下载数据集,根据需要选择全部或部分数据。
4. 使用数据集训练或微调语言模型,观察模型在不同语言任务上的表现。
5. 分析模型输出,根据结果调整模型参数以优化性能。
6. 在教育或研究中应用模型,解决实际问题或提出新的研究假设。
7. 根据Ai2的负责任使用指南,合理使用和引用数据集。
-
 PK
PK tulu-3-sft-olmo-2-mixture VS VoteGPT
tulu-3-sft-olmo-2-mixture VS VoteGPTtulu-3-sft-olmo-2-mixture:allenai/tulu-3-sft-olmo-2-mixture是一个大规模的多语言数据集,包含了用于训练和微调语言模型的多样化文本样本。该数据集的重要性在于它为研究人员和开发者提供了丰富的语言资源,以改进和优化多语言AI模型的性能。产品背景信息包括其由多个来源的数据混合而成,适用于教育和研究领域,且遵循特定的许可协议。 ...
VoteGPT:VoteGPT是一个选举辅助网站,它通过官方政策和维基百科提供的信息,帮助用户了解不同候选人和政党的立场。该产品的主要优点是提供简单、诚实、无偏见的信息,帮助用户在选举中做出更明智的选择。产品背景信息显示,它由Ethical.net创建,旨在为美国人民提供服务。 ...
-
PK
 tulu-3-sft-olmo-2-mixture VS MacBook Pro
tulu-3-sft-olmo-2-mixture VS MacBook Protulu-3-sft-olmo-2-mixture:allenai/tulu-3-sft-olmo-2-mixture是一个大规模的多语言数据集,包含了用于训练和微调语言模型的多样化文本样本。该数据集的重要性在于它为研究人员和开发者提供了丰富的语言资源,以改进和优化多语言AI模型的性能。产品背景信息包括其由多个来源的数据混合而成,适用于教育和研究领域,且遵循特定的许可协议。 ...
MacBook Pro:全新MacBook Pro是苹果公司推出的高性能笔记本电脑,它搭载了苹果自家设计的M4系列芯片,包括M4、M4 Pro和M4 Max,提供了更快的处理速度和增强的功能。这款笔记本电脑专为Apple Intelligence设计,这是一个个人智能系统,它改变了用户在Mac上工作、沟通和表达自己的方式,同时保护了用户的隐私。MacBook Pro以其卓越的性能、长达24小时的电池寿命以及先进的12MP Center Stage摄像头等特性,成为了专业人士的首选工具。 ...
-
PK
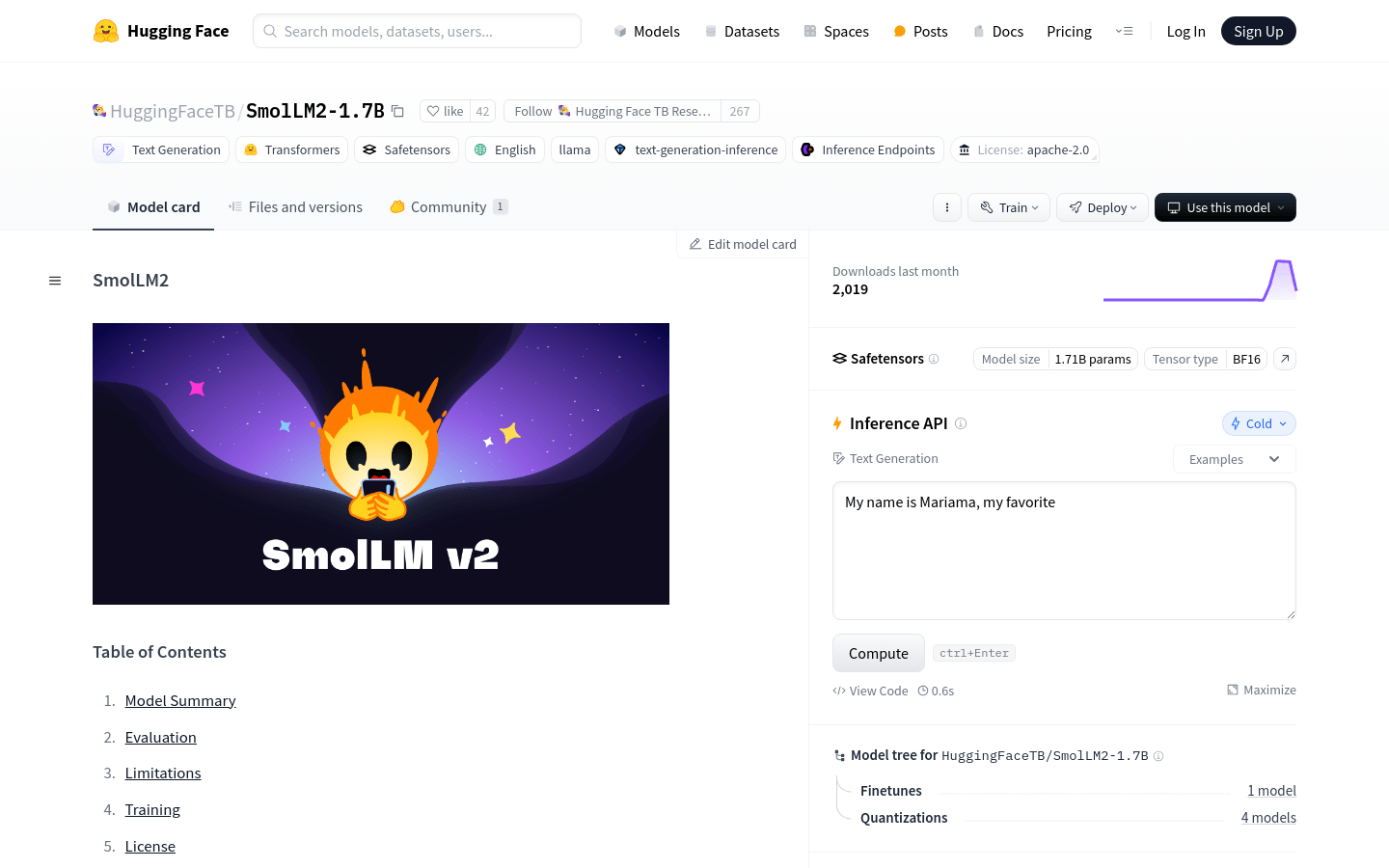 tulu-3-sft-olmo-2-mixture VS SmolLM2-1.7B
tulu-3-sft-olmo-2-mixture VS SmolLM2-1.7Btulu-3-sft-olmo-2-mixture:allenai/tulu-3-sft-olmo-2-mixture是一个大规模的多语言数据集,包含了用于训练和微调语言模型的多样化文本样本。该数据集的重要性在于它为研究人员和开发者提供了丰富的语言资源,以改进和优化多语言AI模型的性能。产品背景信息包括其由多个来源的数据混合而成,适用于教育和研究领域,且遵循特定的许可协议。 ...
SmolLM2-1.7B:SmolLM2是一系列轻量级的语言模型,包含135M、360M和1.7B参数的版本。这些模型能够在保持轻量级的同时解决广泛的任务,特别适合在设备上运行。1.7B版本的模型在指令遵循、知识、推理和数学方面相较于前代SmolLM1-1.7B有显著进步。它使用包括FineWeb-Edu、DCLM、The Stack等多个数据集进行了训练,并且通过使用UltraFeedback进行了直接偏好优化(DPO)。该模型还支持文本重写、总结和功能调用等任务。 ...
-
PK
 tulu-3-sft-olmo-2-mixture VS Learn About
tulu-3-sft-olmo-2-mixture VS Learn Abouttulu-3-sft-olmo-2-mixture:allenai/tulu-3-sft-olmo-2-mixture是一个大规模的多语言数据集,包含了用于训练和微调语言模型的多样化文本样本。该数据集的重要性在于它为研究人员和开发者提供了丰富的语言资源,以改进和优化多语言AI模型的性能。产品背景信息包括其由多个来源的数据混合而成,适用于教育和研究领域,且遵循特定的许可协议。 ...
Learn About:Learn About 是一个教育实验平台,旨在通过提供不同学科的知识点,帮助用户探索和学习新的话题。它涵盖了历史、生物学、物理学、经济学等多个领域,通过互动式学习,让用户能够更深入地了解各个学科的奥秘。产品背景信息显示,Learn About 致力于通过教育技术,激发用户的好奇心和学习热情,提升知识水平。 ...
-
PK
 tulu-3-sft-olmo-2-mixture VS Font Guesser
tulu-3-sft-olmo-2-mixture VS Font Guessertulu-3-sft-olmo-2-mixture:allenai/tulu-3-sft-olmo-2-mixture是一个大规模的多语言数据集,包含了用于训练和微调语言模型的多样化文本样本。该数据集的重要性在于它为研究人员和开发者提供了丰富的语言资源,以改进和优化多语言AI模型的性能。产品背景信息包括其由多个来源的数据混合而成,适用于教育和研究领域,且遵循特定的许可协议。 ...
Font Guesser:Font Guesser是一个在线互动游戏,旨在通过趣味的方式测试和提升用户对不同字体的识别能力。用户需要根据展示的字体样本猜测其类型,包括Display、Serif、Sans-Serif、Monospace、Handwriting和Decorative等。这个游戏不仅增加了用户对字体的认识,还能提升设计感和审美能力。产品背景信息显示,该游戏由Nitin设计并制作,旨在以趣味的方式教育用户识别和了解不同的字体。目前该游戏是免费的,适合所有对字体设计感兴趣的用户。 ...
-
PK
 tulu-3-sft-olmo-2-mixture VS Wikiwand
tulu-3-sft-olmo-2-mixture VS Wikiwandtulu-3-sft-olmo-2-mixture:allenai/tulu-3-sft-olmo-2-mixture是一个大规模的多语言数据集,包含了用于训练和微调语言模型的多样化文本样本。该数据集的重要性在于它为研究人员和开发者提供了丰富的语言资源,以改进和优化多语言AI模型的性能。产品背景信息包括其由多个来源的数据混合而成,适用于教育和研究领域,且遵循特定的许可协议。 ...
Wikiwand:Wikiwand是一个基于AI技术的维基百科增强平台,它通过智能搜索、时间线、Map、词典、热门问题等功能,为用户提供更快速、更深入的学习和探索体验。产品背景信息显示,Wikiwand致力于通过AI技术提升用户对维基百科内容的访问和理解效率,同时支持Wikimedia基金会,促进知识共享。产品提供多种定价方案,满足不同用户的需求。 ...
-
PK
 tulu-3-sft-olmo-2-mixture VS Magic Notepad
tulu-3-sft-olmo-2-mixture VS Magic Notepadtulu-3-sft-olmo-2-mixture:allenai/tulu-3-sft-olmo-2-mixture是一个大规模的多语言数据集,包含了用于训练和微调语言模型的多样化文本样本。该数据集的重要性在于它为研究人员和开发者提供了丰富的语言资源,以改进和优化多语言AI模型的性能。产品背景信息包括其由多个来源的数据混合而成,适用于教育和研究领域,且遵循特定的许可协议。 ...
Magic Notepad:Magic Notepad 是一款人工智能记事本,它通过AI技术将会议笔记整理成结构化的洞察,提供美观的格式和下一步行动建议。它允许用户在会议中记录重要的事项,然后由AI接手,自动整理笔记,让用户能够更专注于会议内容本身。产品背景信息显示,Magic Notepad 旨在通过AI技术提升会议效率,减少会后整理笔记的时间,帮助用户更好地追踪行动项,并为每次会议做好准备。产品定位为免费试用,旨在吸引用户通过实际体验来感受AI技术带来的便利。 ...
-
PK
 tulu-3-sft-olmo-2-mixture VS 图怪兽
tulu-3-sft-olmo-2-mixture VS 图怪兽tulu-3-sft-olmo-2-mixture:allenai/tulu-3-sft-olmo-2-mixture是一个大规模的多语言数据集,包含了用于训练和微调语言模型的多样化文本样本。该数据集的重要性在于它为研究人员和开发者提供了丰富的语言资源,以改进和优化多语言AI模型的性能。产品背景信息包括其由多个来源的数据混合而成,适用于教育和研究领域,且遵循特定的许可协议。 ...
图怪兽:图怪兽-AI智能生成海报是一个在线设计工具,它利用人工智能技术帮助用户快速创建各种海报。这个工具的主要优点在于它的便捷性和高效性,用户只需提供一句话描述,AI就能帮助生成海报。产品背景信息显示,它适用于多种场合,如万圣节、双十一等节日促销,以及人才招聘、教育培训等商业活动。价格方面,用户可以免费试用部分功能,但高级功能可能需要付费。 ...
-
PK
 tulu-3-sft-olmo-2-mixture VS Dashworks Answer API
tulu-3-sft-olmo-2-mixture VS Dashworks Answer APItulu-3-sft-olmo-2-mixture:allenai/tulu-3-sft-olmo-2-mixture是一个大规模的多语言数据集,包含了用于训练和微调语言模型的多样化文本样本。该数据集的重要性在于它为研究人员和开发者提供了丰富的语言资源,以改进和优化多语言AI模型的性能。产品背景信息包括其由多个来源的数据混合而成,适用于教育和研究领域,且遵循特定的许可协议。 ...
Dashworks Answer API:Dashworks是一个企业级的知识管理和AI问答平台,它通过API使企业能够将Dashworks的智能问答能力集成到现有的工作流程和内部工具中。Dashworks通过AI技术,帮助企业快速获取和分享知识,提高工作效率,减少重复性工作。产品背景信息显示Dashworks致力于通过智能化手段,优化企业内部信息的流通和利用。价格和定位方面,Dashworks提供早期访问API,并接受用户申请以获取访问权限,具体价格未在页面中提及。 ...
-
PK
 tulu-3-sft-olmo-2-mixture VS Anthropics educational courses
tulu-3-sft-olmo-2-mixture VS Anthropics educational coursestulu-3-sft-olmo-2-mixture:allenai/tulu-3-sft-olmo-2-mixture是一个大规模的多语言数据集,包含了用于训练和微调语言模型的多样化文本样本。该数据集的重要性在于它为研究人员和开发者提供了丰富的语言资源,以改进和优化多语言AI模型的性能。产品背景信息包括其由多个来源的数据混合而成,适用于教育和研究领域,且遵循特定的许可协议。 ...
Anthropics educational courses:Anthropics educational courses是一个在线教育平台,提供关于如何使用Anthropic的API和提示工程技术的课程。这些课程旨在教育用户如何有效地与AI模型交互,提高工作效率和学习新技术。产品背景信息显示,这些课程适合希望深入了解AI技术和API使用的专业人士和学生,课程内容覆盖从基础到高级的多个层面。 ...
卓商AI整理了一些与 tulu-3-sft-olmo-2-mixture 功能相似或可平替的站点应用,您可点击列表中的标题即可对比查看详细介绍。
上一个
AISmartCube
-
 ToVideoToVideo 是一款专注于将图片转换为视频的在线工具。它利用 AI 技术,为用户提供快速、便捷的图片转视频解决方案。用户可以通过简单的操作,将静态图...
ToVideoToVideo 是一款专注于将图片转换为视频的在线工具。它利用 AI 技术,为用户提供快速、便捷的图片转视频解决方案。用户可以通过简单的操作,将静态图... -
 Basic MemoryBasic Memory是一款知识管理系统,借助与LLM的自然对话构建持久知识,并保存于本地Markdown文件。它解决了多数LLM互动短暂、知识难留...
Basic MemoryBasic Memory是一款知识管理系统,借助与LLM的自然对话构建持久知识,并保存于本地Markdown文件。它解决了多数LLM互动短暂、知识难留... -
 AudiowaveAIAudiowaveAI是一款利用人工智能技术将文本转换成高质量音频的应用程序。它与传统的文本到语音技术不同,提供了更加自然、富有情感的语音输出,让听众...
AudiowaveAIAudiowaveAI是一款利用人工智能技术将文本转换成高质量音频的应用程序。它与传统的文本到语音技术不同,提供了更加自然、富有情感的语音输出,让听众... -
 LookieLookie是一个旨在帮助用户快速吸收和总结YouTube视频内容的工具。它通过AI技术,让用户能够一键提取视频的关键信息,节省时间,提高学习效率。L...
LookieLookie是一个旨在帮助用户快速吸收和总结YouTube视频内容的工具。它通过AI技术,让用户能够一键提取视频的关键信息,节省时间,提高学习效率。L... -
 Minduck.comMinduck是一个创新的AI平台,通过视觉思维工具引导AI生成过程,使用户能够以清晰、有组织的步骤将想法变为现实。它旨在帮助那些在技术面前感到挣扎的...
Minduck.comMinduck是一个创新的AI平台,通过视觉思维工具引导AI生成过程,使用户能够以清晰、有组织的步骤将想法变为现实。它旨在帮助那些在技术面前感到挣扎的... -
 Video_note_generatorVideo_note_generator是一个能够将视频内容快速转换为小红书笔记的工具。它通过自动化技术优化内容和配图,帮助内容创作者、知识管理者和社...
Video_note_generatorVideo_note_generator是一个能够将视频内容快速转换为小红书笔记的工具。它通过自动化技术优化内容和配图,帮助内容创作者、知识管理者和社... -
 GraphitiGraphiti 是一个专注于构建动态时序知识图谱的技术模型,旨在处理不断变化的信息和复杂的关系演变。它通过结合语义搜索和图算法,支持从非结构化文本和...
GraphitiGraphiti 是一个专注于构建动态时序知识图谱的技术模型,旨在处理不断变化的信息和复杂的关系演变。它通过结合语义搜索和图算法,支持从非结构化文本和... -
 PackmindPackmind是一个旨在通过人工智能技术提升团队学习速度和工程性能的平台。它通过将最佳编码实践和标准直接集成到开发工具和AI编码助手中,帮助加速团队...
PackmindPackmind是一个旨在通过人工智能技术提升团队学习速度和工程性能的平台。它通过将最佳编码实践和标准直接集成到开发工具和AI编码助手中,帮助加速团队... -
 fairytailaiFairytailai是希望使就寝时间更神奇的父母的专家解决方案。使用AI技术,Fairytailai个性化的睡前故事是根据您孩子的偏好量身定制的,甚...
fairytailaiFairytailai是希望使就寝时间更神奇的父母的专家解决方案。使用AI技术,Fairytailai个性化的睡前故事是根据您孩子的偏好量身定制的,甚... -
 Google Gemini AI 提示库Google Gemini AI 提示库是一个集成在Google AI Studio中的资源库,它为开发者提供了一系列的AI功能提示和代码示例。这些提...
Google Gemini AI 提示库Google Gemini AI 提示库是一个集成在Google AI Studio中的资源库,它为开发者提供了一系列的AI功能提示和代码示例。这些提... -
 echodocs.aiechodocs.ai 是一款AI驱动的文档工具,旨在帮助用户通过上传音频或文本文件,自动转换成文档,从而简化文档化、知识管理和共享的过程。它通过高度...
echodocs.aiechodocs.ai 是一款AI驱动的文档工具,旨在帮助用户通过上传音频或文本文件,自动转换成文档,从而简化文档化、知识管理和共享的过程。它通过高度... -
 EducUp StudyEducUp Study是一个致力于使学习变得简单和有趣的教育技术初创公司。它使用人工智能技术将任何想法、视频、网站、PDF或文本转化为定制化的、游戏...
EducUp StudyEducUp Study是一个致力于使学习变得简单和有趣的教育技术初创公司。它使用人工智能技术将任何想法、视频、网站、PDF或文本转化为定制化的、游戏...

AI爱好者的一站式人工智能AI工具箱,累计收录全球10,000⁺好用的AI工具软件和网站,方便您更便捷的探索前沿的AI技术。本站持续更新好的AI应用,力争做全球排名前三的AI网址导航网站,欢迎您成为我们的一员。