Florence-2-large
Florence-2-large官网入口
Florence-2-large登录网址
视觉模型
多任务学习
图像描述
目标检测
AI办公应用
生产力工具
Florence-2-large是什么,是做什么的AI工具软件?
Florence-2-large是由微软开发的先进视觉基础模型,采用基于提示的方法处理广泛的视觉和视觉-语言任务。该模型能够解释简单的文本提示来执行如图像描述、目标检测和分割等任务。它利用包含54亿注释的5.4亿图像的FLD-5B数据集,精通多任务学习。其序列到序列的架构使其在零样本和微调设置中均表现出色,证明是一个有竞争力的视觉基础模型。
需求人群:
"Florence-2-large模型适合需要进行图像分析和理解的开发者和研究人员。无论是在学术研究中探索视觉识别的前沿,还是在商业应用中实现图像内容的自动标注和描述,该模型都能提供强大的支持。"
使用场景示例:
在社交媒体上自动为图片生成描述性文字。
为电子商务网站提供商品图片的目标检测和分类服务。
在自动驾驶领域中,用于道路和交通标志的识别。
产品特色:
图像描述:根据图像内容生成描述性文本。
目标检测:识别图像中的物体并标注其位置。
分割:区分图像中的不同区域,如物体和背景。
密集区域描述:为图像中的密集区域生成详细描述。
区域提议:提出图像中可能包含物体的区域。
OCR:从图像中识别和提取文本。
OCR与区域:结合区域信息进行文本识别。
使用教程:
导入必要的库,如requests、PIL、Image和transformers。
使用AutoModelForCausalLM和AutoProcessor从预训练模型中加载Florence-2-large模型。
定义需要执行的任务提示,例如图像描述或目标检测。
加载或获取需要处理的图像数据。
通过模型和处理器将文本提示和图像数据转换为模型可接受的输入格式。
调用模型的generate方法生成结果。
使用处理器的batch_decode方法将生成的ID转换为文本。
根据任务类型,使用后处理方法解析生成的文本,获取最终结果。
-
 PK
PK Florence-2-large VS 腾讯元宝
Florence-2-large VS 腾讯元宝Florence-2-large:Florence-2-large是由微软开发的先进视觉基础模型,采用基于提示的方法处理广泛的视觉和视觉-语言任务。该模型能够解释简单的文本提示来执行如图像描述、目标检测和分割等任务。它利用包含54亿注释的5.4亿图像的FLD-5B数据集,精通多任务学习。其序列到序列的架构使其在零样本和微调设置中均表现出色,证明是一个有竞争力的视觉基础模型。 ...
腾讯元宝:腾讯元宝是一款集成了多种实用工具和服务的生产力工具,旨在提高用户工作效率和生活品质。其背景信息是由腾讯公司推出,定位为全面满足用户工作和生活需求的综合性工具。腾讯元宝提供了丰富的功能和服务,包括日程管理、文件存储、社交聊天、视频会议等,用户可以在一个平台上完成各种任务。 ...
-
PK
 Florence-2-large VS AR2R
Florence-2-large VS AR2RFlorence-2-large:Florence-2-large是由微软开发的先进视觉基础模型,采用基于提示的方法处理广泛的视觉和视觉-语言任务。该模型能够解释简单的文本提示来执行如图像描述、目标检测和分割等任务。它利用包含54亿注释的5.4亿图像的FLD-5B数据集,精通多任务学习。其序列到序列的架构使其在零样本和微调设置中均表现出色,证明是一个有竞争力的视觉基础模型。 ...
AR2R:AR2R是一款旨在解放人类从日常琐事中,通过人工智能技术提高生产力和创造力的AI助手。它通过自然语言用户界面、定制训练的AI协调器以及一系列专业AI代理,为用户提供日程管理、决策支持、在线活动组织、任务提醒、详细跟进和流程自动化等功能。由拥有超过50,000名专家信赖的AI平台团队开发,AR2R致力于帮助用户专注于他们热爱的事情,而不是工作。 ...
-
PK
 Florence-2-large VS AI Notebook
Florence-2-large VS AI NotebookFlorence-2-large:Florence-2-large是由微软开发的先进视觉基础模型,采用基于提示的方法处理广泛的视觉和视觉-语言任务。该模型能够解释简单的文本提示来执行如图像描述、目标检测和分割等任务。它利用包含54亿注释的5.4亿图像的FLD-5B数据集,精通多任务学习。其序列到序列的架构使其在零样本和微调设置中均表现出色,证明是一个有竞争力的视觉基础模型。 ...
AI Notebook:AI Notebook是一款AI驱动的笔记应用,旨在通过智能摘要、灵活捕捉以及各种样式来提升用户的生产力和学习效率。它能够无缝地组织文本、图片甚至音频,提供强大的笔记体验。AI Notebook通过AI助手提升生产力和学习,用户可以通过上传音频、文本、照片和YouTube链接来提问或使用AI进行头脑风暴。它还具备高质量的音频录制和实时转录功能,以及AI生成的摘要和模板,以及自动生成的闪卡和测验,帮助用户高效地创建、组织和复习所学内容。 ...
-
PK
 Florence-2-large VS Mapify
Florence-2-large VS MapifyFlorence-2-large:Florence-2-large是由微软开发的先进视觉基础模型,采用基于提示的方法处理广泛的视觉和视觉-语言任务。该模型能够解释简单的文本提示来执行如图像描述、目标检测和分割等任务。它利用包含54亿注释的5.4亿图像的FLD-5B数据集,精通多任务学习。其序列到序列的架构使其在零样本和微调设置中均表现出色,证明是一个有竞争力的视觉基础模型。 ...
Mapify:Mapify 是一款 AI 驱动的思维导图工具,能够帮助用户从多种文件格式、网页内容或视频等资料中快速提取核心观点,并整理输出为结构化的思维导图。它通过一键做图、缩放导图、内置 AI 模板等功能,极大提升了用户的生产力和创造力。Mapify 还具备与 AI 对话、实时网络访问和图像生成等高级功能,使用户能够更高效地展示和分享思维导图。 ...
-
PK
 Florence-2-large VS anto
Florence-2-large VS antoFlorence-2-large:Florence-2-large是由微软开发的先进视觉基础模型,采用基于提示的方法处理广泛的视觉和视觉-语言任务。该模型能够解释简单的文本提示来执行如图像描述、目标检测和分割等任务。它利用包含54亿注释的5.4亿图像的FLD-5B数据集,精通多任务学习。其序列到序列的架构使其在零样本和微调设置中均表现出色,证明是一个有竞争力的视觉基础模型。 ...
anto:anto 是一款针对 Windows 的字幕文件 (srt) 翻译工具,提供便捷的翻译功能,旨在提高字幕翻译效率。 ...
-
PK
 Florence-2-large VS Riffo
Florence-2-large VS RiffoFlorence-2-large:Florence-2-large是由微软开发的先进视觉基础模型,采用基于提示的方法处理广泛的视觉和视觉-语言任务。该模型能够解释简单的文本提示来执行如图像描述、目标检测和分割等任务。它利用包含54亿注释的5.4亿图像的FLD-5B数据集,精通多任务学习。其序列到序列的架构使其在零样本和微调设置中均表现出色,证明是一个有竞争力的视觉基础模型。 ...
Riffo:Riffo是一款旨在帮助用户简化文件重命名和组织流程的AI助手。它通过智能技术,减少了文件管理中的猜测工作,使得文件组织变得简单快捷。Riffo支持多种文件格式,包括图片、Word文档、PDF等,并通过并行处理技术,能够快速完成大量文件的批量重命名。 ...
-
PK
 Florence-2-large VS Park Here
Florence-2-large VS Park HereFlorence-2-large:Florence-2-large是由微软开发的先进视觉基础模型,采用基于提示的方法处理广泛的视觉和视觉-语言任务。该模型能够解释简单的文本提示来执行如图像描述、目标检测和分割等任务。它利用包含54亿注释的5.4亿图像的FLD-5B数据集,精通多任务学习。其序列到序列的架构使其在零样本和微调设置中均表现出色,证明是一个有竞争力的视觉基础模型。 ...
Park Here:Park Here 是一款旨在简化停车过程的移动应用程序。它通过让用户拍照停车标志,利用图像识别技术来提供用户当前位置的停车选项。该应用程序的背景是解决城市停车难题,帮助用户节省寻找停车位的时间,提高停车效率。 ...
-
PK
 Florence-2-large VS Kerlig
Florence-2-large VS KerligFlorence-2-large:Florence-2-large是由微软开发的先进视觉基础模型,采用基于提示的方法处理广泛的视觉和视觉-语言任务。该模型能够解释简单的文本提示来执行如图像描述、目标检测和分割等任务。它利用包含54亿注释的5.4亿图像的FLD-5B数据集,精通多任务学习。其序列到序列的架构使其在零样本和微调设置中均表现出色,证明是一个有竞争力的视觉基础模型。 ...
Kerlig:Kerlig是一款为macOS设计的AI写作助手,它通过集成AI技术,帮助用户在各种应用程序中快速生成文本、修正语法、改变语调、回答问题等,显著提高写作效率和质量。产品背景信息显示,Kerlig由Jarek开发,支持OpenAI、Anthropic和Gemma等AI模型,提供快捷键操作,无需切换上下文即可使用。产品定位为提高生产力,价格为27美元起。 ...
-
PK
 Florence-2-large VS 豆包桌面 AI 助手
Florence-2-large VS 豆包桌面 AI 助手Florence-2-large:Florence-2-large是由微软开发的先进视觉基础模型,采用基于提示的方法处理广泛的视觉和视觉-语言任务。该模型能够解释简单的文本提示来执行如图像描述、目标检测和分割等任务。它利用包含54亿注释的5.4亿图像的FLD-5B数据集,精通多任务学习。其序列到序列的架构使其在零样本和微调设置中均表现出色,证明是一个有竞争力的视觉基础模型。 ...
豆包桌面 AI 助手:豆包桌面 AI 助手是一款集成了多种 AI 功能的桌面应用程序,豆包电脑版客户端旨在提升用户的工作和学习效率。它通过 AI 划词翻译、搜索、AI 伴读 PDF 等功能,帮助用户快速获取信息,节省时间,提高生产力。产品由北京春田知韵科技有限公司开发,拥有简洁的界面和强大的功能,是现代办公和学习的得力助手。 ...
-
PK
 Florence-2-large VS MailMaestro
Florence-2-large VS MailMaestroFlorence-2-large:Florence-2-large是由微软开发的先进视觉基础模型,采用基于提示的方法处理广泛的视觉和视觉-语言任务。该模型能够解释简单的文本提示来执行如图像描述、目标检测和分割等任务。它利用包含54亿注释的5.4亿图像的FLD-5B数据集,精通多任务学习。其序列到序列的架构使其在零样本和微调设置中均表现出色,证明是一个有竞争力的视觉基础模型。 ...
MailMaestro:MailMaestro是一款AI电子邮件助手,专为Outlook和Gmail设计,旨在帮助用户更快、更高质量地撰写电子邮件。它通过自动化和个性化功能,帮助用户节省时间,提高工作效率,同时确保邮件内容的安全性。 ...
卓商AI整理了一些与 Florence-2-large 功能相似或可平替的站点应用,您可点击列表中的标题即可对比查看详细介绍。
上一个
智能编码助手通义灵码下一个
Florence-2-base
相关AI工具集
-
 Formula GeneratorFormulaGenerator是一个基于AI技术的Excel公式生成工具。它可以帮助用户快速生成复杂的Excel公式、VBA自动化脚本和SQL查询,...
Formula GeneratorFormulaGenerator是一个基于AI技术的Excel公式生成工具。它可以帮助用户快速生成复杂的Excel公式、VBA自动化脚本和SQL查询,... -
 AutoJobsAutoJobs是一款AI驱动的网页扩展程序,旨在通过自动化工作申请流程来帮助用户节省时间并提高求职效率。它使用最新的人工智能技术从用户的简历和个人资...
AutoJobsAutoJobs是一款AI驱动的网页扩展程序,旨在通过自动化工作申请流程来帮助用户节省时间并提高求职效率。它使用最新的人工智能技术从用户的简历和个人资... -
 jamiejamie是一款AI驱动的会议记录助手,能够自动生成摘要、转录和行动项。它支持15种以上语言,并且注重隐私保护。jamie帮助用户节省时间,提高效率,...
jamiejamie是一款AI驱动的会议记录助手,能够自动生成摘要、转录和行动项。它支持15种以上语言,并且注重隐私保护。jamie帮助用户节省时间,提高效率,... -
 GPT FormulaGPT Formula是一款AI工具,可以为您生成Excel和Google Sheet公式。它能够根据您提供的简短描述自动生成复杂的公式,并提供公式的...
GPT FormulaGPT Formula是一款AI工具,可以为您生成Excel和Google Sheet公式。它能够根据您提供的简短描述自动生成复杂的公式,并提供公式的... -
 Mail HelperMail Helper是一款AI电子邮件撰写工具,针对经常需要给外国人写邮件的用户。用户只需告诉它想要表达的内容,它将生成地道生动的当地语言邮件,而不...
Mail HelperMail Helper是一款AI电子邮件撰写工具,针对经常需要给外国人写邮件的用户。用户只需告诉它想要表达的内容,它将生成地道生动的当地语言邮件,而不... -
 Alice.techAlice 是一款基于 OpenAI 技术开发的智能学习平台,旨在通过 AI 驱动的学习工具帮助学生更高效地备考。它能够将用户上传的学习材料转化为个性...
Alice.techAlice 是一款基于 OpenAI 技术开发的智能学习平台,旨在通过 AI 驱动的学习工具帮助学生更高效地备考。它能够将用户上传的学习材料转化为个性... -
 TaskekTaskek是一款基于人工智能的任务管理工具,旨在帮助团队高效推进工作。它通过智能算法优化任务分配和协作流程,提升团队生产力。产品主要面向需要高效协作...
TaskekTaskek是一款基于人工智能的任务管理工具,旨在帮助团队高效推进工作。它通过智能算法优化任务分配和协作流程,提升团队生产力。产品主要面向需要高效协作... -
 Florence-2-base-ftFlorence-2是由微软开发的高级视觉基础模型,采用基于提示的方法处理广泛的视觉和视觉-语言任务。该模型能够解释简单的文本提示,执行诸如图像描述、...
Florence-2-base-ftFlorence-2是由微软开发的高级视觉基础模型,采用基于提示的方法处理广泛的视觉和视觉-语言任务。该模型能够解释简单的文本提示,执行诸如图像描述、... -
 AIFINDYAIFINDY是一个每日更新的免费人工智能工具数据库,为用户提供广泛的AI应用,涵盖社交媒体、艺术创作、文本处理、音乐制作、视频编辑等多个领域。它为个...
AIFINDYAIFINDY是一个每日更新的免费人工智能工具数据库,为用户提供广泛的AI应用,涵盖社交媒体、艺术创作、文本处理、音乐制作、视频编辑等多个领域。它为个... -
 iBriefiBrief是一个利用人工智能技术提供文章摘要服务的在线平台。它能够在短时间内为用户提供准确、简洁的文章摘要,帮助用户节省时间,快速了解文章内容。产品...
iBriefiBrief是一个利用人工智能技术提供文章摘要服务的在线平台。它能够在短时间内为用户提供准确、简洁的文章摘要,帮助用户节省时间,快速了解文章内容。产品... -
 TabTacTabTac浏览器是一款基于AI技术的新一代浏览器,它通过集成ChatGPT等工具,提供搜索增强、网页浏览增强和办公辅助增强功能。该浏览器采用去中心化...
TabTacTabTac浏览器是一款基于AI技术的新一代浏览器,它通过集成ChatGPT等工具,提供搜索增强、网页浏览增强和办公辅助增强功能。该浏览器采用去中心化... -
 4M4M是一个用于训练多模态和多任务模型的框架,能够处理多种视觉任务,并且能够进行多模态条件生成。该模型通过实验分析展示了其在视觉任务上的通用性和可扩展性...
4M4M是一个用于训练多模态和多任务模型的框架,能够处理多种视觉任务,并且能够进行多模态条件生成。该模型通过实验分析展示了其在视觉任务上的通用性和可扩展性...

卓商AI
AI爱好者的一站式人工智能AI工具箱,累计收录全球10,000⁺好用的AI工具软件和网站,方便您更便捷的探索前沿的AI技术。本站持续更新好的AI应用,力争做全球排名前三的AI网址导航网站,欢迎您成为我们的一员。
最新收录
Spoke
Spoke是一款AI插件,为产品经理提供强大的、注重隐私的AI功能,能够在几秒钟内为用户提供上下文信息。它可以帮助全球快速增长的团队节省时间,创造上下...
LastMile AI
LastMile AI是一个AI开发平台,专为工程师而设计,可以用于原型开发和生成式AI应用的生产。它提供了一站式的多模态AI模型访问,包括语言模型(...
Dokkio
Dokkio是一款利用人工智能技术提供云文件协作的工具。它能帮助用户管理多个活动、搜索文档和文件、整理研究材料、组织内容库,并将所有文件和内容集中在一...

Engage Sphere AI
Engage Sphere是一个基于AI的员工参与度分析平台。它可以深入分析公司各个部门、团队和岗位的参与度,帮助管理者明确团队互动症结所在,并采取行...
Pikzels
Pikzels连接顶级人才和有远见的客户。我们促进协作,释放创意卓越。加入我们,获取来自各个领域的优秀专业人才。体验协作的力量,释放你的创意潜能。Pi...
Zoho Cliq
Zoho Cliq是一款专为提高企业工作效率而设计的在线即时通讯和协作平台。它将团队成员、对话和工作流集中在一个地方,实现无缝连接。主要功能包括:组织...
猜你喜欢
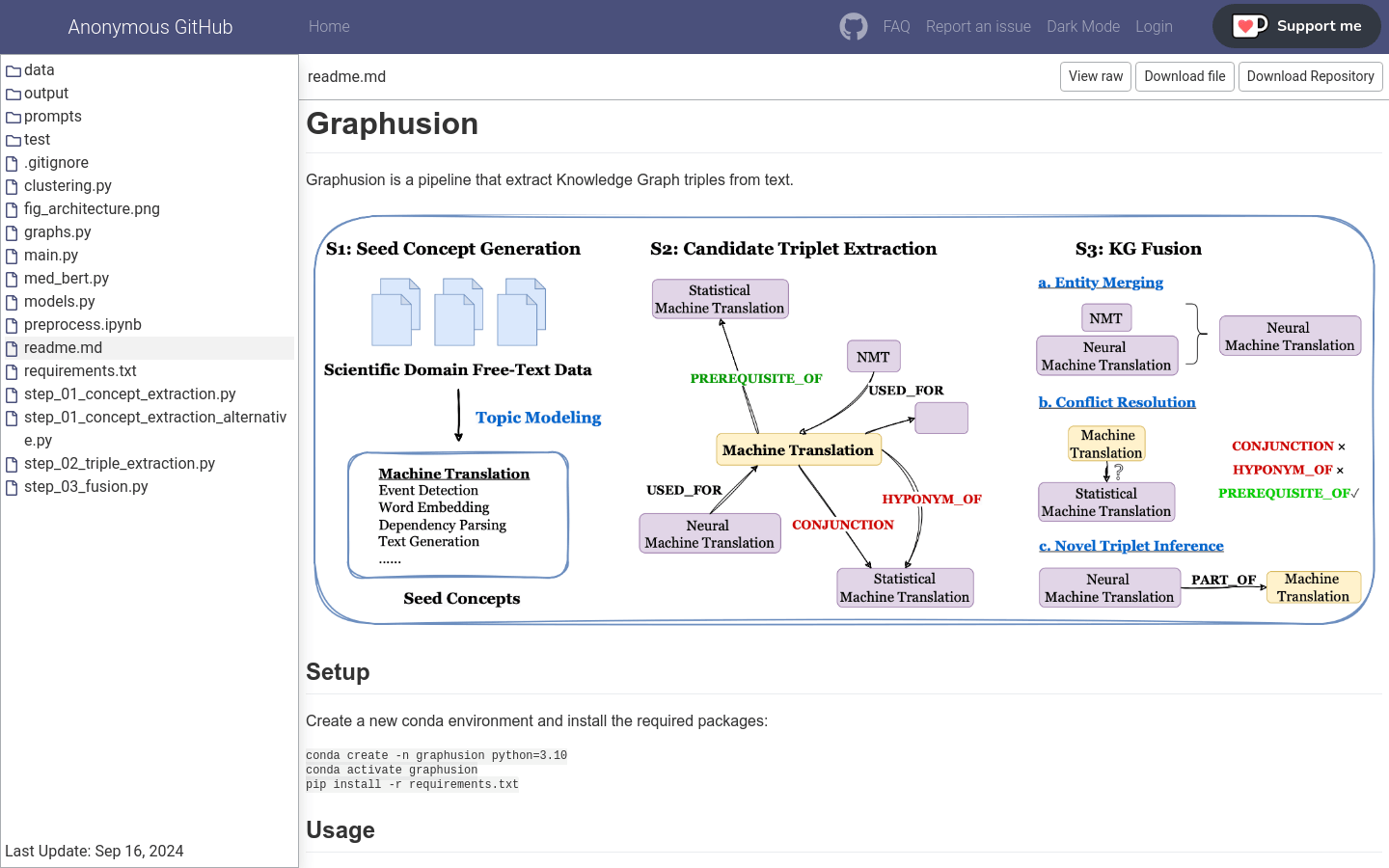
Graphusion
Graphusion是一个用于从文本中提取知识图谱三元组的管道工具。它通过一系列步骤,包括概念提取、候选三元组提取和三元组融合,来构建知识图谱。这个工...
Maroofy
Maroofy是一个音乐搜索引擎,可以搜索歌曲并获取类似音乐的推荐。用户可以连接Apple Music获取个性化推荐、保存播放列表等功能。该产品旨在帮...
AIMusicGen.AI
AIMusicGen.AI 是一款基于人工智能的在线音乐生成平台,通过先进的深度学习技术,能够将用户的文字描述或歌词快速转化为高质量的音乐作品。其主要...
Alerts.boo
Alerts.bookey是一个用于获取在线事件提醒的服务。它可以通过电子邮件、Telegram或Webhook发送提醒,适用于市场营销机构和个人开发...
whisper-diarization
whisper-diarization是一个结合了Whisper自动语音识别(ASR)能力、声音活动检测(VAD)和说话人嵌入技术的开源项目。它通过提...
Cellm
Cellm 是一款创新的 Excel 扩展工具,它将大型语言模型(LLMs)的强大功能引入 Excel,使用户能够在单元格公式中直接调用 AI 模型来...
最新文章
1
2
3
4
5
6
7
8
9
10
AI爱好者的一站式人工智能AI工具箱,累计收录全球10,000⁺好用的AI工具软件和网站,方便您更便捷的探索前沿的AI技术。本站持续更新好的AI应用,力争做全球排名前三的AI网址导航网站,欢迎您成为我们的一员。
