上一篇
MUMU是什么?一文让你看懂MUMU的技术原理、主要功能、应用场景LLaVA-OneVision是什么?一文让你看懂LLaVA-OneVision的技术原理、主要功能、应用场景
来源:卓商AI
发布时间:2025-04-05
LLaVA-OneVision概述简介
LLaVA-OneVision是字节跳动推出开源的多模态AI大模型,LLaVA-OneVision通过整合数据、模型和视觉表示的见解,能同时处理单图像、多图像和视频场景下的计算机视觉任务。LLaVA-OneVision支持跨模态/场景的迁移学习,特别在图像到视频的任务转移中表现出色,具有强大的视频理解和跨场景能力。
LLaVA-OneVision的功能特色
多模态理解:能理解和处理单图像、多图像和视频内容,提供深入的视觉分析。
任务迁移:支持不同视觉任务之间的迁移学习,尤其是图像到视频的任务迁移,展现出视频理解能力。
跨场景能力:在不同的视觉场景中展现出强大的适应性和性能,包括但不限于图像分类、识别和描述生成。
开源贡献:模型的开源性质为社区提供了代码库、预训练权重和多模态指令数据,促进了研究和应用开发。
高性能:在多个基准测试中超越了现有模型,显示出卓越的性能和泛化能力。
LLaVA-OneVision的技术原理
多模态架构:模型采用多模态架构,将视觉信息和语言信息融合,以理解和处理不同类型的数据。
语言大模型集成:选用了Qwen-2作为语言大模型,模型具备强大的语言理解和生成能力,能准确理解用户输入并生成高质量文本。
视觉编码器:使用Siglip作为视觉编码器,在图像和视频特征提取方面表现出色,能捕捉关键信息。
特征映射:通过多层感知机(MLP)将视觉特征映射到语言嵌入空间,形成视觉标记,为多模态融合提供桥梁。
任务迁移学习:允许在不同模态或场景之间进行任务迁移,通过这种迁移学习,模型能发展出新的能力和应用。
LLaVA-OneVision项目介绍
GitHub仓库:https://llava-vl.github.io/blog/2024-08-05-llava-onevision/
arXiv技术论文:https://arxiv.org/pdf/2408.03326
如何使用LLaVA-OneVision
环境准备:确保有合适的计算环境,包括硬件资源和必要的软件依赖。
获取模型:访问LLaVA-OneVision的Github仓库,下载或克隆模型的代码库和预训练权重。
安装依赖:根据项目文档安装所需的依赖库,如深度学习框架(例如PyTorch或TensorFlow)和其他相关库。
数据准备:准备或获取想要模型处理的数据,可能包括图像、视频或多模态数据,并按照模型要求格式化数据。
模型配置:根据具体应用场景配置模型参数,涉及到调整模型的输入输出格式、学习率等超参数。
LLaVA-OneVision能做什么?
图像和视频分析:对图像和视频内容进行深入分析,包括物体识别、场景理解、图像描述生成等。
内容创作辅助:为艺术家和创作者提供灵感和素材,帮助创作图像、视频等多媒体内容。
聊天机器人:作为聊天机器人,与用户进行自然流畅的对话,提供信息查询、娱乐交流等服务。
教育和培训:在教育领域,辅助教学过程,提供视觉辅助材料,增强学习体验。
安全监控:在安全领域,分析监控视频,识别异常行为或事件,提高安全监控的效率。
© 版权声明:本站所有原创文章版权均归卓商AI工具集及原创作者所有,未经允许任何个人、媒体、网站不得转载或以其他方式抄袭本站任何文章。
相关文章
-
 TimeSuite是什么?一文让你看懂TimeSuite的技术原理、主要功能、应用场景2025-04-05
TimeSuite是什么?一文让你看懂TimeSuite的技术原理、主要功能、应用场景2025-04-05 -
YT Navigator是什么?一文让你看懂YT Navigator的技术原理、主要功能、应用场景2025-04-05
-
TÜLU 3是什么?一文让你看懂TÜLU 3的技术原理、主要功能、应用场景2025-04-05
-
AgiBot Digital World是什么?一文让你看懂AgiBot Digital World的技术原理、主要功能、应用场景2025-04-05
-
REEF是什么?一文让你看懂REEF的技术原理、主要功能、应用场景2025-04-05
-
NPOA是什么?一文让你看懂NPOA的技术原理、主要功能、应用场景2025-04-05

卓商AI
AI爱好者的一站式人工智能AI工具箱,累计收录全球10,000⁺好用的AI工具软件和网站,方便您更便捷的探索前沿的AI技术。本站持续更新好的AI应用,力争做全球排名前三的AI网址导航网站,欢迎您成为我们的一员。
最新发布
1
2
3
4
5
6
7
8
9
10
猜你喜欢
Truresume Builder
TruResume是一款免费的简历生成器工具,帮助您构建专业简历。您可以在几分钟内在线创建专业简历,无需担心简历的外观问题。我们提供多种模板和设计选项...
Pagerly AI
Pagerly AI是一款用于快速调试和文档编写的工具。它能够帮助您更快速地解决问题,并提供自动化的文档生成功能。Pagerly AI还能与各种服务集...
OpenAI Realtime Embedded SDK
openai-realtime-embedded-sdk是一个专为微控制器设计的SDK,允许开发者在如ESP32这样的微控制器上实现实时API功能。这...
Rocketnotes
Rocketnotes是一个云端笔记应用,提供强大的Markdown编辑器,支持响应式预览和多种编程语言的代码语法高亮。它允许用户从任何设备访问笔记,...

Supermoon
Supermoon是一款用于管理电子商务和客户服务沟通的软件。它能帮助您提供优质的客户支持,建立持久的客户关系,并节省时间。Supermoon提供协作...
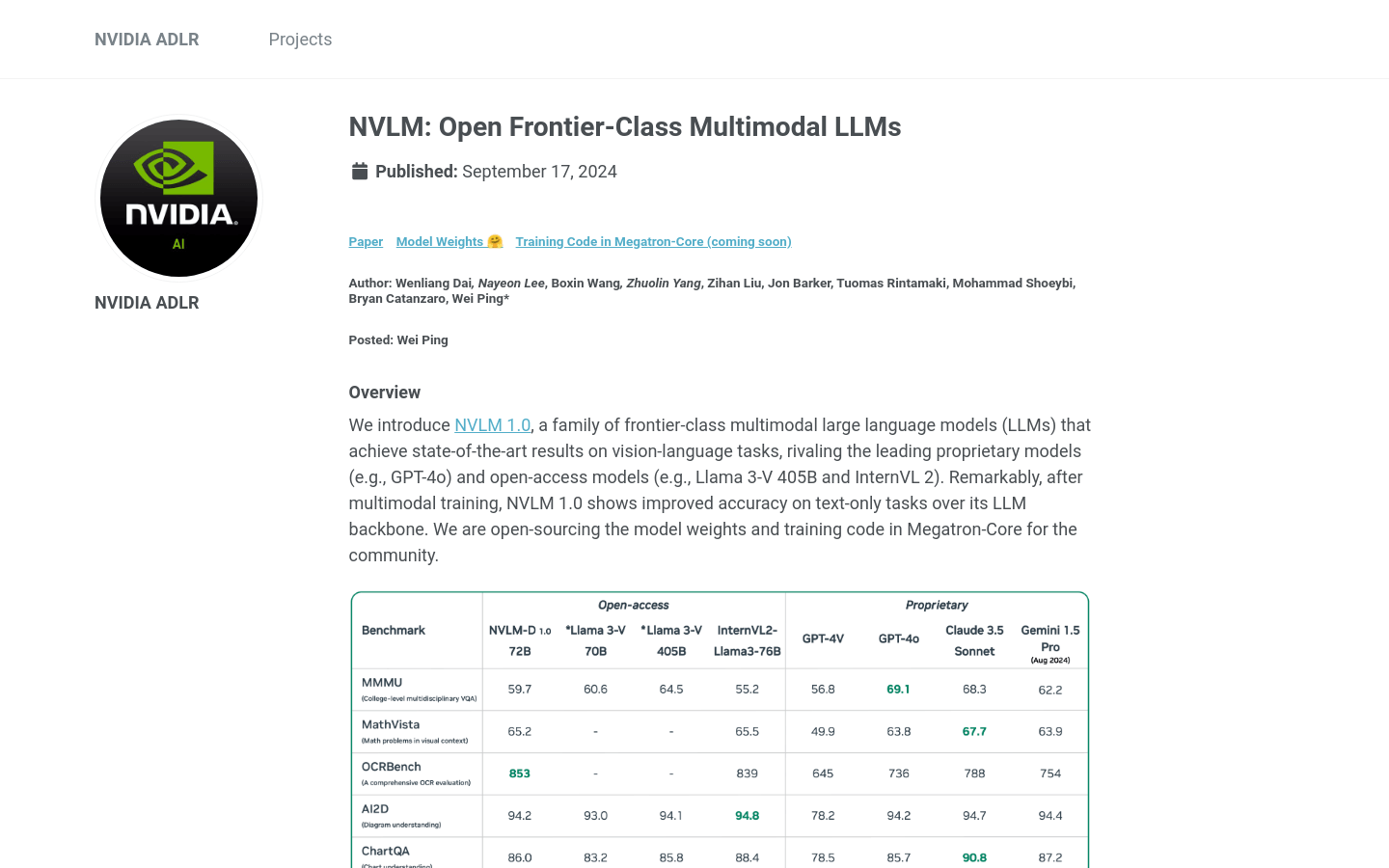
NVLM 1.0
NVLM 1.0是NVIDIA ADLR推出的前沿级多模态大型语言模型系列,它在视觉-语言任务上达到了业界领先水平,与顶级专有模型和开放访问模型相媲美...
Shred
Shred是一款提供个性化数字健身训练的应用程序,旨在帮助用户根据个人目标定制训练计划。它通过AI技术为用户提供个性化的健身指导,包括训练程序、视频课...
Applio
Applio是一个开源生态系统,主要提供先进的AI语音克隆技术。它的主要优点是创新性、开放源代码和先进的AI语音克隆技术。Applio的背景信息是作为...
AI爱好者的一站式人工智能AI工具箱,累计收录全球10,000⁺好用的AI工具软件和网站,方便您更便捷的探索前沿的AI技术。本站持续更新好的AI应用,力争做全球排名前三的AI网址导航网站,欢迎您成为我们的一员。
