首页 >VideoChat和Vibe Coder对比
VideoChat和Vibe Coder哪个好用,VideoChat和Vibe Coder详细对比
VideoChat:VideoChat是一个实时语音交互数字人项目,支持端到端语音方案(GLM-4-Voice - THG)和级联方案(ASR-LLM-TTS-THG)。用户可以自定义数字人的形象和音色,支持音色克隆,无需训练,首包延迟低至3秒。该项目利用了最新的人工智能技术,包括自动语音识别(ASR)、大型语言模型(
Vibe Coder:Vibe Coder 是由 Deepgram 开发的一款开源 VS Code 扩展,旨在探索语音驱动编程的可能性。它利用语音识别技术,让用户通过语音指令与 AI 编程助手进行交互,快速将想法转化为代码原型。这种创新的编程方式被称为‘vibe coding’,旨在提高编程效率并改变未来软件开发的方式。
VideoChat和Vibe Coder均是AI软件、AI工具中的一种,在功能设计、应用场景、用户体验上存在一些区别,以下是卓商AI整理出来的一些对比选项,仅供您参考。
官网地址
https://github.com/Henry-23/VideoChat
https://deepgram.com/learn/introducing-vibe-coder-voice-driven-coding
功能简介
VideoChat是一个实时语音交互数字人项目,支持端到端语音方案(GLM-4-Voice - THG)和级联方案(ASR-LLM-TTS-THG)。用户可以自定义数字人的形象和音色,支持音色克隆,无需训练,首包延迟低至3秒。该项目利用了最新的人工智能技术,包括自动语音识别(ASR)、大型语言模型(LLM)、端到端多模态大型语言模型(MLLM)、文本到语音(TTS)和说话头生成(THG),为用户提供了一个高度定制化和低延迟的交互体验。
Vibe Coder 是由 Deepgram 开发的一款开源 VS Code 扩展,旨在探索语音驱动编程的可能性。它利用语音识别技术,让用户通过语音指令与 AI 编程助手进行交互,快速将想法转化为代码原型。这种创新的编程方式被称为‘vibe coding’,旨在提高编程效率并改变未来软件开发的方式。Vibe Coder 目前处于实验阶段,Deepgram 希望通过社区反馈不断完善该工具。
排名榜单 🔥
可平替产品
Castmagic
Castmagic是一个可以将长音频转化为各种可用的内容资产的工具。它可以自动清洗、转录、时间戳和摘要音频,生成完整的内容文稿、笔记、摘要、亮点、引用、社交媒体帖子等,帮助用户快速产出高质量的内容。C

PODSHORTY
PODSHORTY是一款AI摘要工具,通过先进的Transformer AI技术,将长视频压缩为精简的音频摘要,同时保持原始演讲者的声音和风格。除了摘要,您还可以获取精简过的文字转录,方便您随时查看,
TranscribeMe
TranscribeMe是一款将Whatsapp和Telegram语音消息转化为文字的智能工具。它可以帮助用户免费将语音转换为文本,支持在Whatsapp和Telegram中直接使用。该工具注重用户隐
Peech App
Peech是一款文本转语音工具,可将任何网络文章、电子书或其他文本转换为引人入胜的有声读物。无论您是有阅读障碍、注意力不集中、视觉障碍,还是只想听而不想读,都可以使用Peech将文本转换为音频。同时,
Audio to Photoreal Embodiment
Audio to Photoreal Embodiment是一个生成全身照片级人形化身的框架。它根据对话动态生成面部、身体和手部的多种姿势动作。其方法的关键在于通过将向量量化的样本多样性与扩散所获得的
必剪
必剪是B站官方出品的视频剪辑工具,专为UP主和视频创作者设计,提供海量素材、语音字幕、一键三连、B站投稿等功能,旨在简化视频制作流程,提高创作效率。产品背景依托于B站强大的视频社区,拥有丰富的素材库和

speechify voice cloning
通过语音克隆来提升您的声音。 Speechify AI技术使您可以在几秒钟内创建高质量的人类声音克隆,而无需使用特殊设备。非常适合个性化的消息传递和配音。
ImageBind
ImageBind是一种新的AI模型,能够同时绑定六种感官模态的数据,无需显式监督。通过识别这些模态之间的关系(图像和视频、音频、文本、深度、热成像和惯性测量单元(IMUs)),这一突破有助于推动AI
SenseVoice
SenseVoice是一个包含自动语音识别(ASR)、语音语言识别(LID)、语音情感识别(SER)和音频事件检测(AED)等多语音理解能力的语音基础模型。它专注于高精度多语种语音识别、语音情感识别和
Audiogen
Audiogen利用AI的力量,为您提供强大而直观的解决方案,让您即时生成各种音频,包括样本、乐器、音效或纹理。生成的声音具有高品质,可以变化无穷,免版税,可生成不同长度,实时生成,还可以扩展已有的声
voice-swap.ai
Voice-Swap是一款使用人工智能技术的音频转换工具,可以将您的声音转换成顶尖歌手的风格,适用于制作演示或找到最适合您曲目的完美声音。我们提供免费试用和订阅计划,支持远程协作和演示制作。

AI Voice Generator Bot
AI语音生成器是一个简单易用的产品,它使用人工智能技术将文本转换为音频。它提供了多达25种不同的声音,完美演绎英语。您只需在Telegram上输入文本,我们即可回复相应的音频,无需等待。立即试用,快速
ElevenLabs Voice Design
ElevenLabs Voice Design是一个在线平台,允许用户通过简单的文本提示来设计和生成定制的声音。这项技术的重要性在于它能够快速创建出符合特定描述的声音,如年龄、口音、语气或角色,甚至包
Mini-Omni
Mini-Omni是一个开源的多模态大型语言模型,能够实现实时的语音输入和流式音频输出的对话能力。它具备实时语音到语音的对话功能,无需额外的ASR或TTS模型。此外,它还可以在思考的同时进行语音输出,
Fish Agent V0.1 3B
Fish Agent V0.1 3B是一个开创性的语音转语音模型,能够以前所未有的精确度捕捉和生成环境音频信息。该模型采用了无语义标记架构,消除了传统语义编码器/解码器的需求。此外,它还是一个尖端的文
Google Gemini App
Google Gemini是一款由Google开发的AI助手应用,旨在通过人工智能技术帮助用户提高创造力和生产力。它允许用户通过语音与应用交互,进行头脑风暴、简化复杂话题、为重要时刻排练等。Gemin
卡卡字幕助手
卡卡字幕助手(VideoCaptioner)是一款功能强大的视频字幕配制软件,利用大语言模型进行字幕智能断句、校正、优化、翻译,实现字幕视频全流程一键处理。产品无需高配置,操作简单,内置基础LLM模型
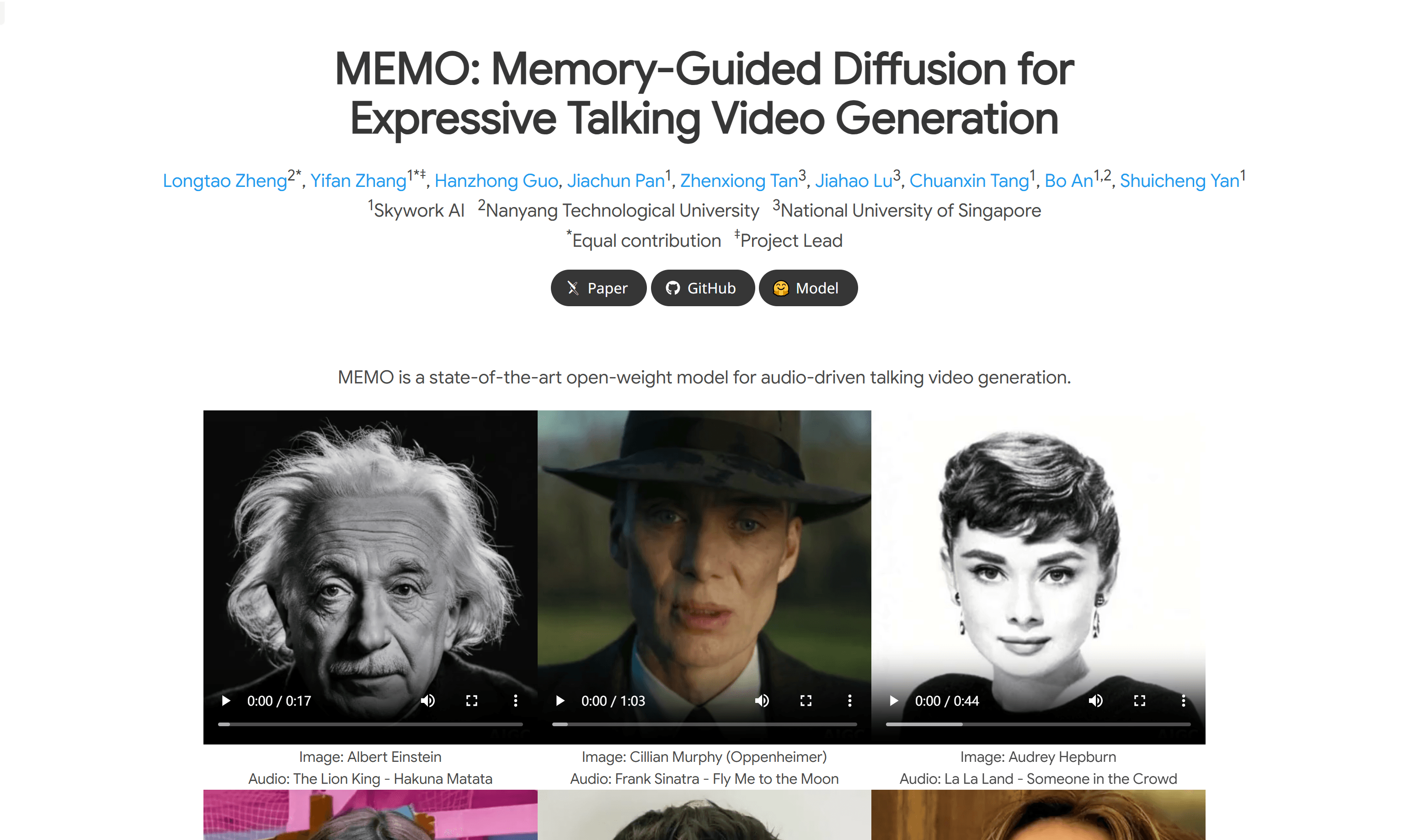
MEMO
MEMO是一个先进的开放权重模型,用于音频驱动的说话视频生成。该模型通过记忆引导的时间模块和情感感知的音频模块,增强了长期身份一致性和运动平滑性,同时通过检测音频中的情感来细化面部表情,生成身份一致且
Chat2Invest
Chat2Invest是Slack上的一个机器人,可以阅读和总结任何网页、包括电子书在内的文档,甚至来自YouTube的视频。它可以通过语音与您交流,还可以作为您的个人导师,支持中文、英文、德文和日文

Dub AI
Dub AI是一款AI驱动的语音克隆和翻译工具,可以帮助您轻松为视频添加翻译和配音,扩大全球观众。
ListenRobo
ListenRobo是一个语音转文本的工具,能够将英语音频转换为文本,提供免费下载不带水印的txt、srt和vtt格式字幕。它快速准确,支持92种语言,可以生成英语翻译,还提供文本摘要和智能翻译功能。
Browser AI Kit
Browser AI Kit是一个集成了多种AI工具的平台,用户可以在浏览器中直接使用这些工具,无需安装或设置。它提供了音频转文本、去除背景、文本转语音等多种功能,并且完全免费。这个工具箱基于Tran
PlayNote
PlayNote是一款利用尖端AI语音合成技术,将各种文件和数据转换成音频创作的产品。它支持多种文件格式,包括PDF、CSV、TXT等文档,以及PNG、JPEG等图片格式,还有MP4、MOV等视频格式

hertz-dev
hertz-dev是Standard Intelligence开源的全双工、仅音频的变换器基础模型,拥有85亿参数。该模型代表了可扩展的跨模态学习技术,能够将单声道16kHz语音转换为8Hz潜在表示,
AI爱好者的一站式人工智能AI工具箱,累计收录全球10,000⁺好用的AI工具软件和网站,方便您更便捷的探索前沿的AI技术。本站持续更新好的AI应用,力争做全球排名前三的AI网址导航网站,欢迎您成为我们的一员。
