首页 >Adobe Podcast和OCTAVE对比
Adobe Podcast和OCTAVE哪个好用,Adobe Podcast和OCTAVE详细对比
Adobe Podcast:Adobe Podcast是一款基于人工智能技术的音频录制和编辑工具。它提供清晰、高质量的音频录制和编辑功能,支持自动转录、剪辑和分享。无论您是专业的播客主持人还是想要创作自己的播客节目,Adobe Podcast都可以满足您的需求。它还提供多种音频效果和工具,帮助您创建独特而专业的音频内容。Ado
OCTAVE:OCTAVE (Omni-Capable Text and Voice Engine)是一个结合了前沿语言模型和语音系统能力的下一代语音语言模型。它能够从简短的描述性提示或录音中生成不仅仅是声音,还有个性(语言、口音、表达、潜在性格等),并且能够实时响应中生成多个交互的AI个性和声音。OCTAVE维
Adobe Podcast和OCTAVE均是AI软件、AI工具中的一种,在功能设计、应用场景、用户体验上存在一些区别,以下是卓商AI整理出来的一些对比选项,仅供您参考。
官网地址
https://podcast.adobe.com
https://www.hume.ai/blog/introducing-octave
功能简介
Adobe Podcast是一款基于人工智能技术的音频录制和编辑工具。它提供清晰、高质量的音频录制和编辑功能,支持自动转录、剪辑和分享。无论您是专业的播客主持人还是想要创作自己的播客节目,Adobe Podcast都可以满足您的需求。它还提供多种音频效果和工具,帮助您创建独特而专业的音频内容。Adobe Podcast定价灵活,适用于个人和团队使用。
OCTAVE (Omni-Capable Text and Voice Engine)是一个结合了前沿语言模型和语音系统能力的下一代语音语言模型。它能够从简短的描述性提示或录音中生成不仅仅是声音,还有个性(语言、口音、表达、潜在性格等),并且能够实时响应中生成多个交互的AI个性和声音。OCTAVE维持了类似大小的前沿大型语言模型(LLM)的能力,非常适合驱动与人类丰富沟通的AI系统,同时遵循详细指令,使用工具或控制界面。
排名榜单 🔥
可平替产品
MasteredNow
Magnetic Mastering是一款专为现代音乐人设计的私人母带工具包。它可以在几分钟内使你的音乐达到分发标准,并自动优化在不同平台上的播放效果。通过独特的智能EQ功能,你可以获得个性化的音频调
Syndy
Syndy是一个AI创造播客的平台。它使用先进的人工智能技术,帮助用户创造出他们想要听的播客内容。Syndy提供了丰富的功能,包括语音合成、音频编辑、内容推荐等。用户可以根据自己的喜好和需求,定制出独
Speech to Note
Speech to Note是一个AI驱动的语音识别工具,能够即时将口语转换为文本。它使用先进的语音转文本技术,将您的语音转换成可以编辑或分享的简洁摘要。该产品由GPT-4技术支持,旨在提升生产力并释
AniPortrait
AniPortrait是一个根据音频和图像输入生成会说话、唱歌的动态视频的项目。它能够根据音频和静态人脸图片生成逼真的人脸动画,口型保持一致。支持多种语言和面部重绘、头部姿势控制。功能包括音频驱动的动
Character Calls
Character Calls是Character.AI社区推出的一款应用,旨在通过无缝的双向语音对话功能,让用户与他们喜爱的角色进行互动,就像与朋友通话一样。这项服务完全免费,支持多种语言,包括英语
ElevenLabs Projects
ElevenLabs Projects 是一个专注于长音频内容制作的平台,它允许用户将书籍和脚本转换成有声书和播客。该产品支持多种文件格式,拥有广泛的语音库,并提供情感范围和上下文适应的AI语音技术。

雷鸟RayNeo AI
RayNeo AI是雷鸟自主研发的人工智能语音助手,集成了自然语言处理、语音识别、语音合成等核心技术,可实现自然语言交互、语音控制等功能。该产品已在雷鸟XR系列产品中进行内测,支持行程规划、天气查询、
Audio Transcription
Audio Transcription是一款利用AI技术将音频内容转换为文本的在线工具。它能够帮助用户快速准确地将播客、音频文件或网址中的音频内容转写成文本形式,并提供智能摘要,极大地提高了工作效率。
Syft
Syft是一款AI音频剪辑工具,通过智能算法快速生成剪辑片段。它提供简单易用的界面和丰富的功能,可以帮助用户快速剪辑和编辑音频文件。无论是制作音频广告、播客剪辑还是个人音频作品,Syft都能满足你的需
AudioSeal
AudioSeal 是一种用于AI生成语音音频的本地化水印技术,具有最先进的鲁棒性和极快的检测速度。它通过联合训练一个嵌入水印的生成器和一个检测器,即使在音频编辑的情况下,也能在较长的音频中检测到水印
AIVocal
AIVocal是一款基于人工智能技术的在线人声消除工具,它能够在短时间内从任何歌曲中去除人声,创建伴奏带、分离乐器音轨,并提升音乐制作效率。该产品以其高效率、高精度和易用性,满足了音乐制作人、内容创作
AI Music Generator
AI音乐生成器(AMG)是一款通过简单描述即可生成音频片段的AI工具。它由Meta的AudioCraft技术提供支持。每秒0.008美元,试用版可生成60秒。

MimicTalk
MimicTalk是一种基于神经辐射场(NeRF)的个性化三维说话面部生成技术,它能够在几分钟内模仿特定身份的静态外观和动态说话风格。这项技术的主要优点包括高效率、高质量的视频生成以及对目标人物说话风

Voice Engine
Voice Engine是一种先进的语音合成模型,它仅需15秒的语音样本,便能生成与原始说话人极为相似的自然语音。该模型广泛应用于教育、娱乐、医疗等领域,可为非读写人群提供朗读辅助、为视频和播客内容翻
Qlient
Qlient AI 是为寻求高效客户管理的企业设计的创新解决方案。我们的 24/7 AI 语音助手自动化客户接待、简化沟通,并增强客户参与度。

Vocapia
Vocapia Research开发的语音识别软件提供先进的语音处理技术,支持多语种识别,并能应用于广播监控、讲座和研讨会转录、视频字幕、电话会议转录和语音分析等领域。我们的产品具有大词汇量连续语音识
ElevenLabs Scribe
Scribe 是由 ElevenLabs 开发的高精度语音转文字模型,旨在处理真实世界音频的不可预测性。它支持99种语言,提供单词级时间戳、说话人分离和音频事件标记等功能。Scribe 在 FLEUR
OmniAudio-2.6B
OmniAudio-2.6B是一个2.6B参数的多模态模型,能够无缝处理文本和音频输入。该模型结合了Gemma-2B、Whisper turbo和一个自定义投影模块,与传统的将ASR和LLM模型串联的
Gan.AI
Gan.AI是一个专注于对话式人工智能研究和产品的公司,致力于通过其先进的AI技术,为全球知名品牌提供个性化的视频和音频通信解决方案。该公司的产品和技术在个性化营销、粉丝参与、以及提升用户体验方面展现
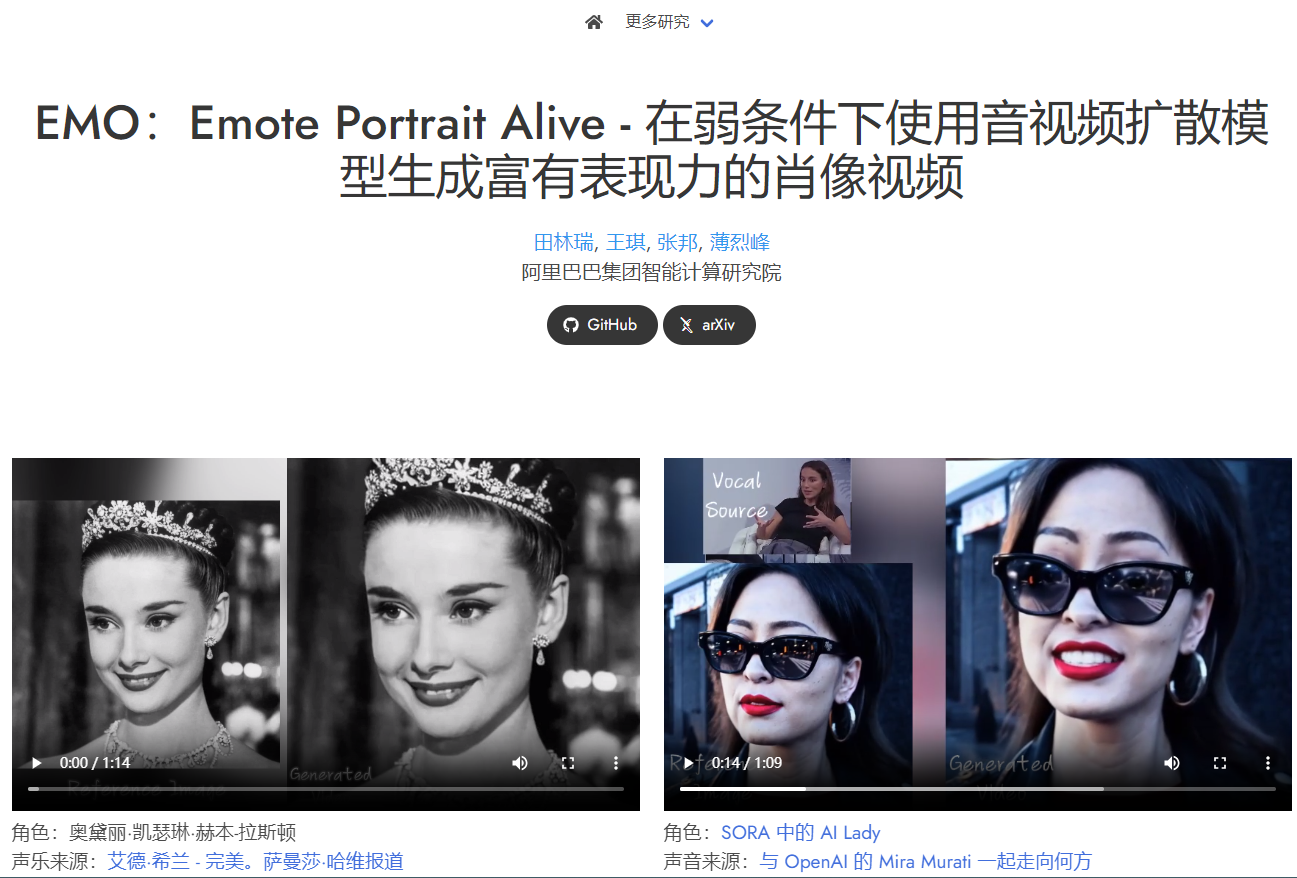
EMO
阿里巴巴的EMO: 是一款生成具有表情丰富的面部表情视频的工具,可以根据输入的角色图像和声音音频生成各种头部姿势和表情的声音头像视频。支持多语言歌曲和各种肖像风格,能够根据音频节奏生成动态、表现丰富
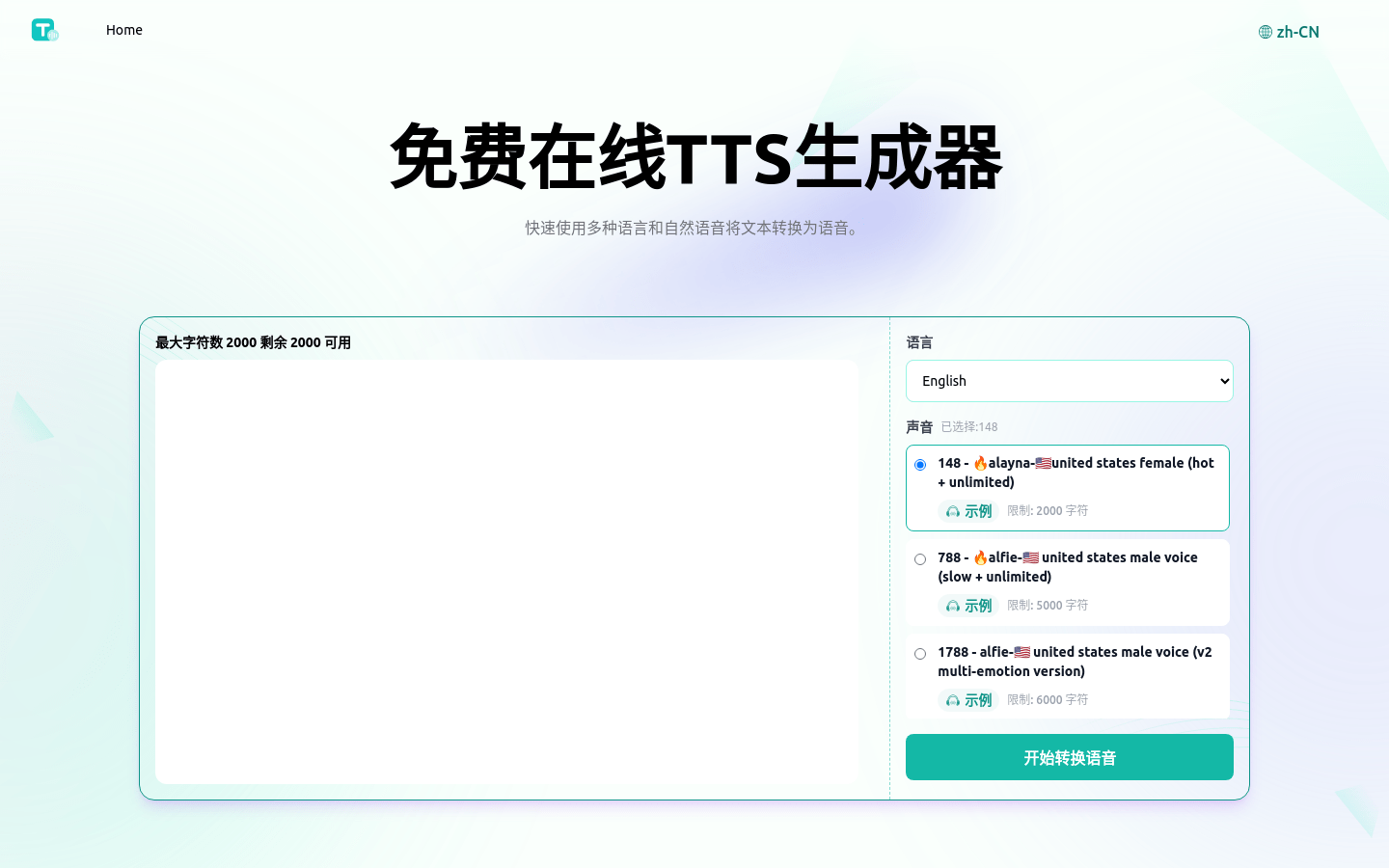
TTSynth.com
TTSynth.com是一个免费的在线文本转语音(TTS)生成器,它使用先进的AI技术将书面文本转换为自然发音的语音。该服务支持多种语言和口音,适用于全球用户。它提供了高质量的音频输出,并且用户可以轻
OCTAVE
OCTAVE (Omni-Capable Text and Voice Engine)是一个结合了前沿语言模型和语音系统能力的下一代语音语言模型。它能够从简短的描述性提示或录音中生成不仅仅是声音,还有
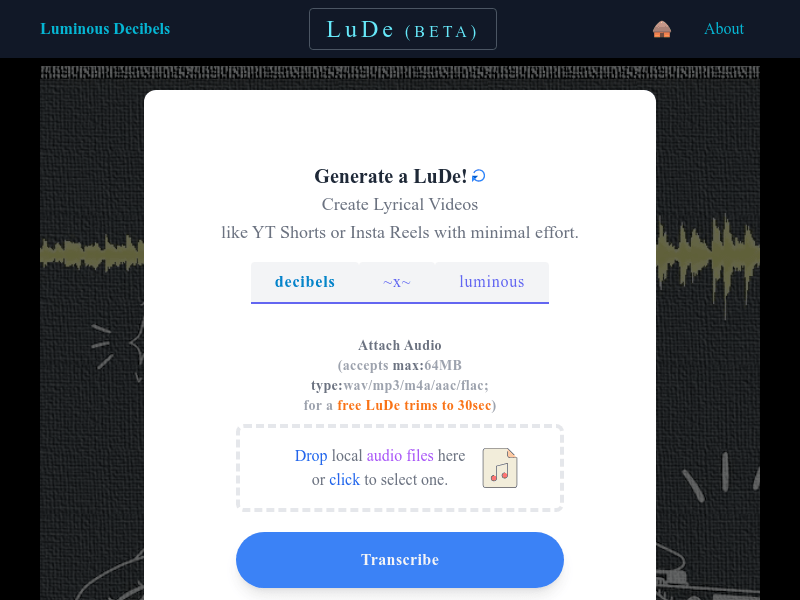
LuDe
LuDe是一款基于人工智能的音视频生成工具,可以通过提供的音频或文本内容快速创建视频。它具有智能转写、视频背景更换和视频生成等功能。LuDe可以帮助用户轻松创建各种类型的视频,如YT Shorts和I
Azure 认知服务语音
Azure 认知服务语音是微软推出的一款语音识别与合成服务,支持超过100种语言和方言的语音转文本和文本转语音功能。它通过创建可处理特定术语、背景噪音和重音的自定义语音模型,提高听录的准确度。此外,该
AI爱好者的一站式人工智能AI工具箱,累计收录全球10,000⁺好用的AI工具软件和网站,方便您更便捷的探索前沿的AI技术。本站持续更新好的AI应用,力争做全球排名前三的AI网址导航网站,欢迎您成为我们的一员。
