首页 >PlayNote和Moonshine Web对比
PlayNote和Moonshine Web哪个好用,PlayNote和Moonshine Web详细对比
PlayNote:PlayNote是一款利用尖端AI语音合成技术,将各种文件和数据转换成音频创作的产品。它支持多种文件格式,包括PDF、CSV、TXT等文档,以及PNG、JPEG等图片格式,还有MP4、MOV等视频格式,以及WAV、MP3等音频格式。用户可以上传文件,PlayNote会将文件内容转化为音频,方便用户在
Moonshine Web:Moonshine Web是一个基于React和Vite构建的简单应用,它运行了Moonshine Base,这是一个针对快速准确自动语音识别(ASR)优化的强大语音识别模型,适用于资源受限的设备。该应用在浏览器端本地运行,使用Transformers.js和WebGPU加速(或WASM作为备选)。
PlayNote和Moonshine Web均是AI软件、AI工具中的一种,在功能设计、应用场景、用户体验上存在一些区别,以下是卓商AI整理出来的一些对比选项,仅供您参考。
官网地址
https://github.com/huggingface/transformers.js-examples/tree/main/moonshine-web
功能简介
PlayNote是一款利用尖端AI语音合成技术,将各种文件和数据转换成音频创作的产品。它支持多种文件格式,包括PDF、CSV、TXT等文档,以及PNG、JPEG等图片格式,还有MP4、MOV等视频格式,以及WAV、MP3等音频格式。用户可以上传文件,PlayNote会将文件内容转化为音频,方便用户在各种场合下收听。这项技术的重要性在于它能够提高信息的可访问性,特别是对于视觉障碍人士或者在无法阅读的情况下需要获取信息的用户。PlayNote的背景信息显示,它是由PlayAI提供的,旨在通过技术创新提升工作效率和生活质量。关于价格,用户可以访问Pricing页面了解更多详情。
Moonshine Web是一个基于React和Vite构建的简单应用,它运行了Moonshine Base,这是一个针对快速准确自动语音识别(ASR)优化的强大语音识别模型,适用于资源受限的设备。该应用在浏览器端本地运行,使用Transformers.js和WebGPU加速(或WASM作为备选)。它的重要性在于能够为用户提供一个无需服务器即可在本地进行语音识别的解决方案,这对于需要快速处理语音数据的应用场景尤为重要。
排名榜单 🔥
可平替产品
百宝音
百宝音是一个在线免费文字转语音的配音合成软件,提供近百种配音模板,主打影视解说配音、专题片配音、广告配音等,具有高度定制化的优势,可根据用户需求定制各种音色风格。
speech-to-speech
speech-to-speech 是一个开源的模块化GPT4-o项目,通过语音活动检测、语音转文本、语言模型和文本转语音等连续部分实现语音到语音的转换。它利用了Transformers库和Huggin
Coqui
Coqui Studio通过生成式人工智能实现了逼真、感性的文本转语音,用户可以克隆现有声音或设计自己的理想声音,还可以调整语速和情感,全面掌控AI声音。通过高级编辑器,用户可以为每个句子、单词或角色

VividTalk
VividTalk是一种一次性音频驱动的头像生成技术,基于3D混合先验。它能够生成具有表情丰富、自然头部姿态和唇同步的逼真说唱视频。该技术采用了两阶段通用框架,支持生成具有上述所有特性的高视觉质量的说
Voice Remaker - Free AI Voice
Voice Remaker是一个完全免费的AI语音生成工具,使用最好的合成音色,为您生成最接近人声的文本转语音(TTS)音频。即时将文本转换为自然流畅的语音,并以MP3音频文件的形式下载。
Cols.ai
Cols.ai 的 AI Phone Calling Platform 是一款旨在实现无缝人类语音通信的AI产品。它能够与电话系统连接,处理呼入电话,并以个性化的上下文进行呼出电话。该平台通过个性化对
Paper-to-Podcast
Paper-to-Podcast是一个将学术论文转换成播客形式的工具,通过模拟三个人的讨论来让听众以更自然和人性化的方式理解论文内容。它不仅使复杂的信息更易于吸收,还提供了宝贵的洞见和批判性思考。该工
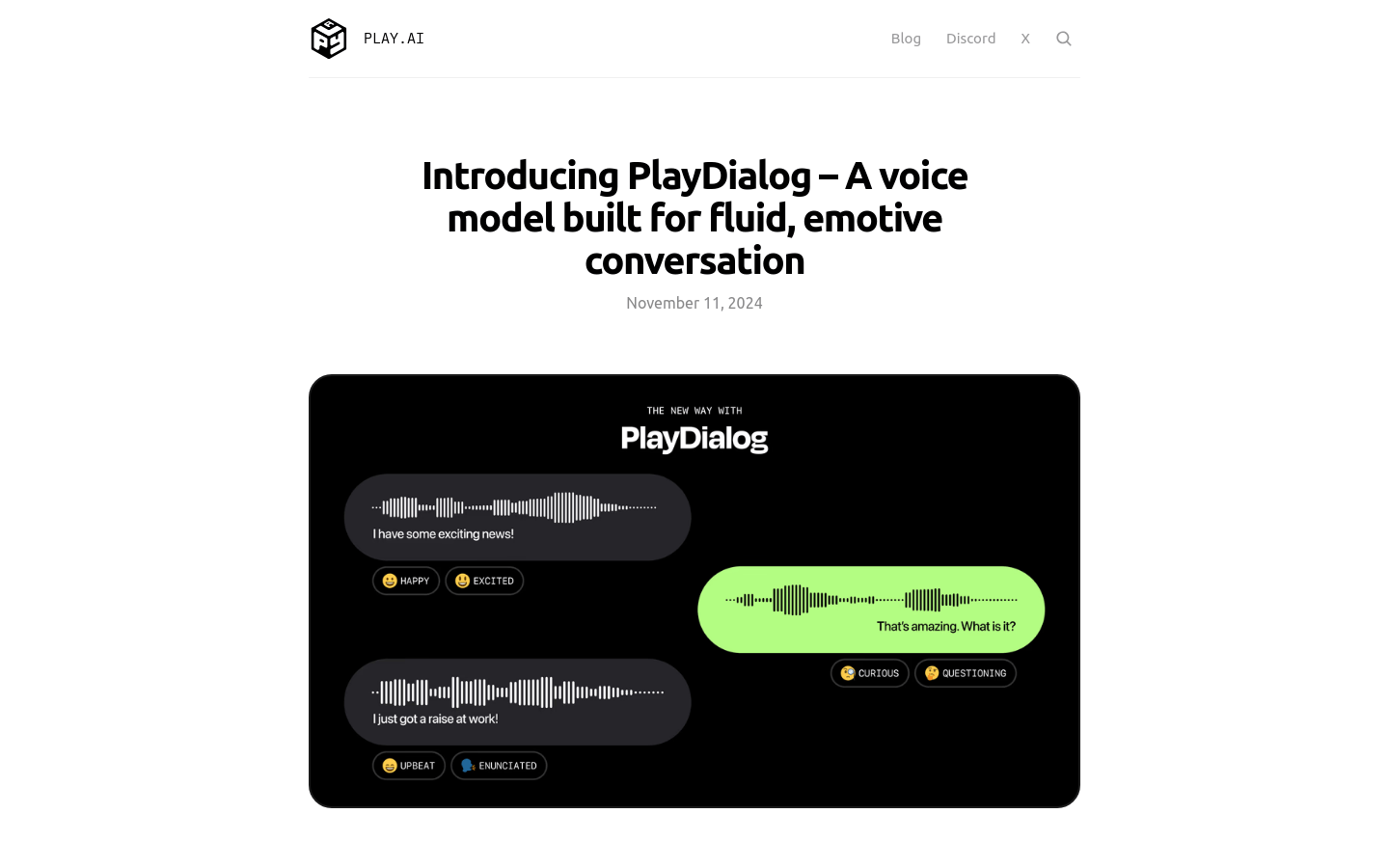
PlayDialog
PlayDialog是Play.ai推出的一款端到端AI语音模型,它利用对话的历史背景来控制韵律、语调、情感和节奏,以提供更自然的声音,为匹配人类在现实生活情境中的说话方式树立了新标准。PlayDia
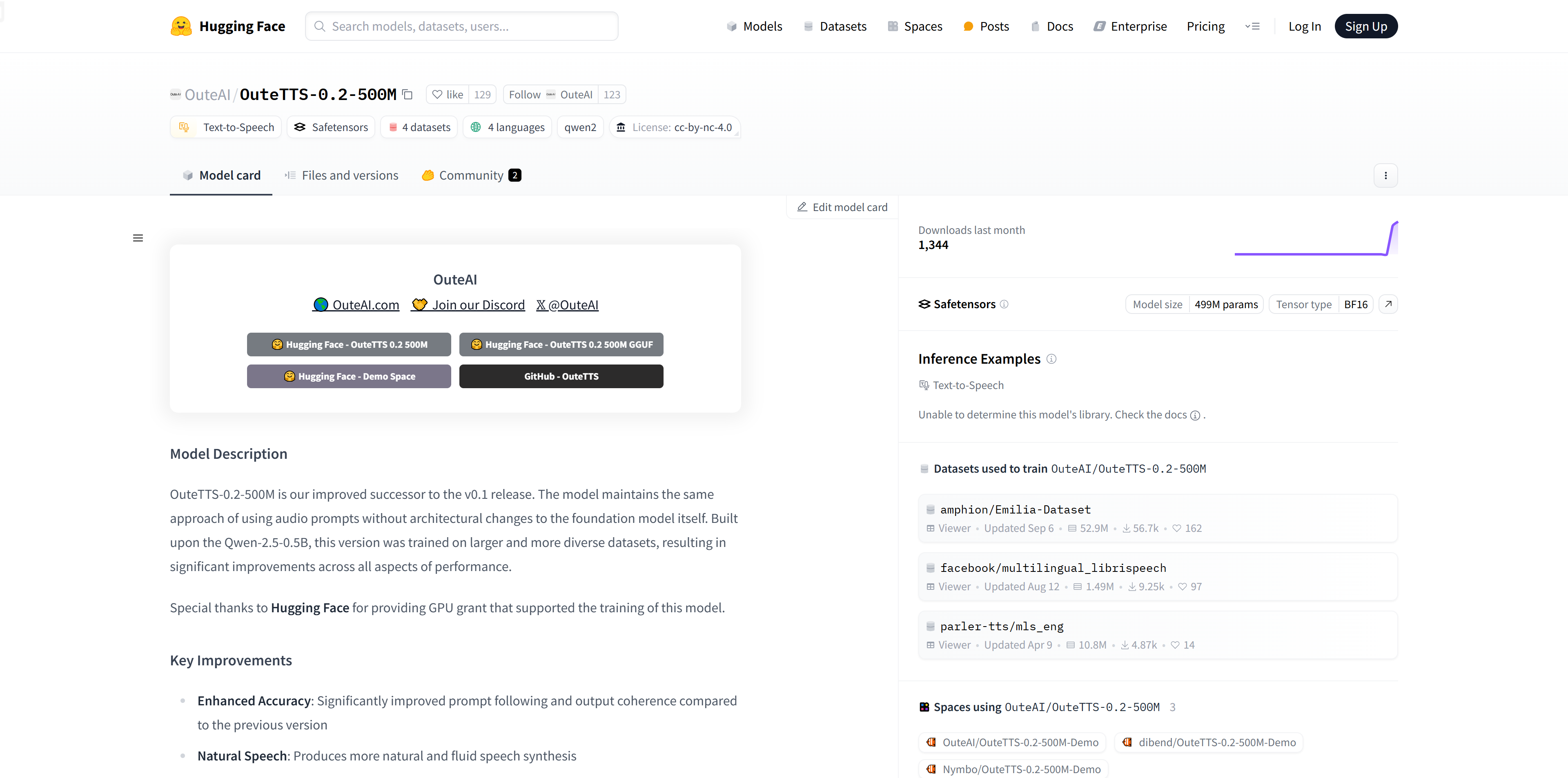
OuteTTS-0.2-500M
OuteTTS-0.2-500M是基于Qwen-2.5-0.5B构建的文本到语音合成模型,它在更大的数据集上进行了训练,实现了在准确性、自然度、词汇量、声音克隆能力以及多语言支持方面的显著提升。该模型
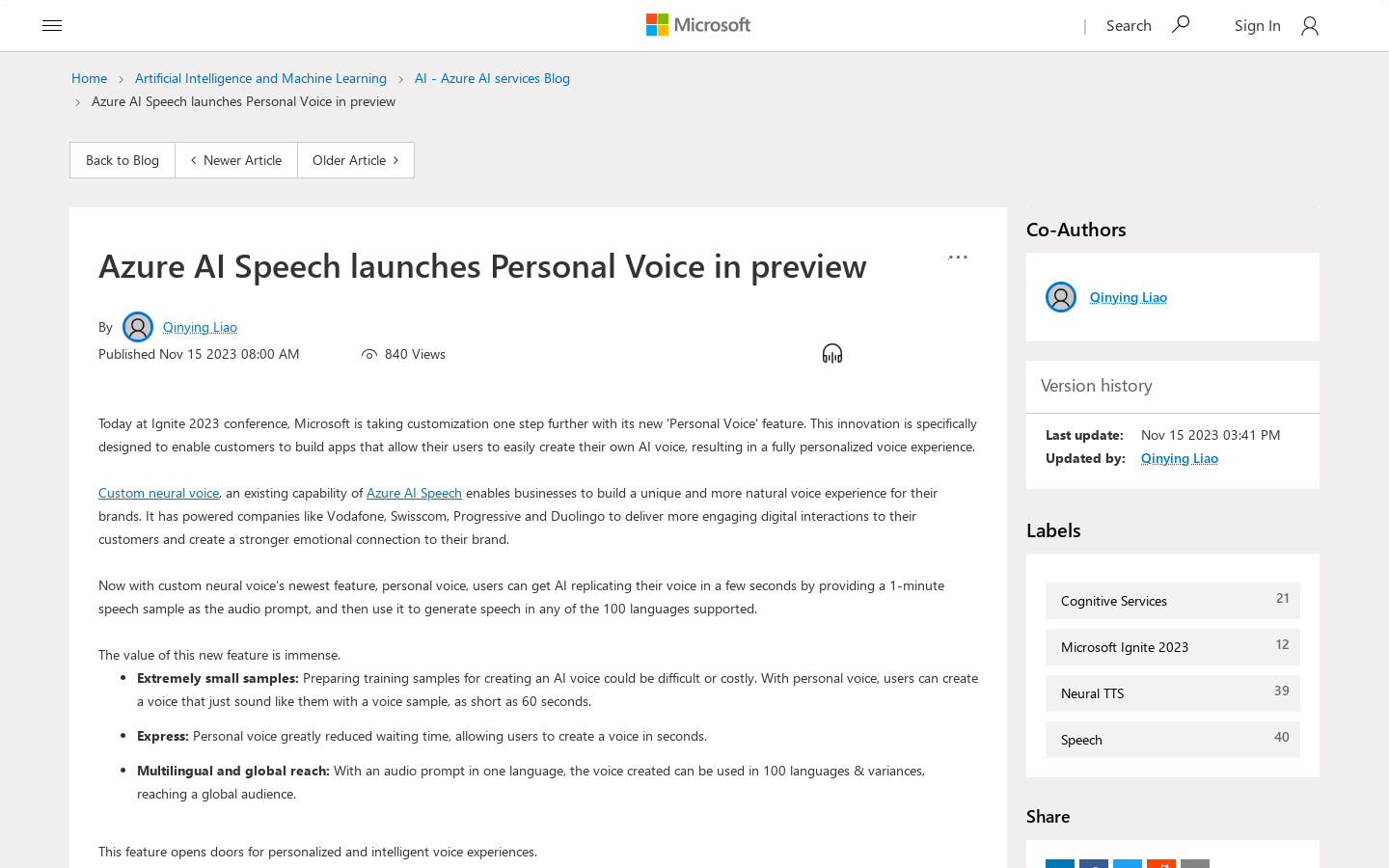
Personal Voice
Personal Voice 是一款定制个人化语音体验的工具。它允许用户通过提供一个 1 分钟的语音样本来复制自己的声音,并生成支持 100 种语言的语音输出。用户可以在语音助手、游戏、媒体娱乐等场景
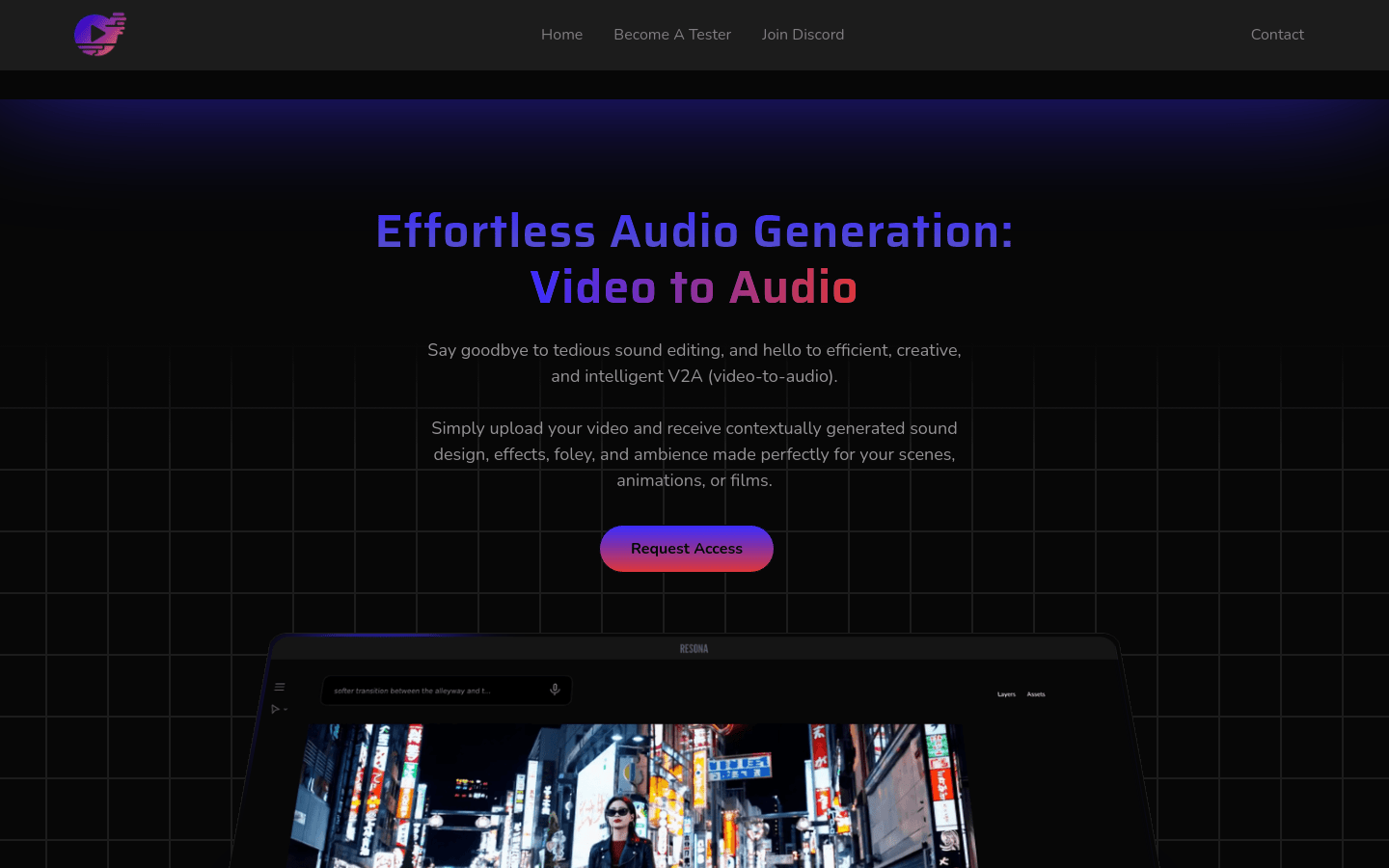
Resona V2A
Resona V2A是一款AI驱动的视频到音频生成技术产品,它能够仅通过视频数据自动生成与场景、动画或电影完美匹配的声音设计、效果、拟音和环境音。该技术通过自动化音频创作过程,节省了大约90%的时间和
AudioLM
AudioLM是由Google Research开发的一个框架,用于高质量音频生成,具有长期一致性。它将输入音频映射到离散标记序列,并将音频生成视为这一表示空间中的语言建模任务。AudioLM通过在大
AudiowaveAI
AudiowaveAI是一款利用人工智能技术将文本转换成高质量音频的应用程序。它与传统的文本到语音技术不同,提供了更加自然、富有情感的语音输出,让听众在学习和享受内容时获得更好的听觉体验。产品背景信息
Lemonfox.ai Text-to-Speech API
Lemonfox.ai Text-to-Speech API 是一款专注于文本转语音(TTS)的API服务。它利用先进的AI技术,能够快速将文本转换为自然流畅的语音,支持多种语言和口音,适用于多种场景
HitPaw Voice Changer
HitPaw Voice Changer是一款智能辅助工具,可以在任何场景中智能辅助您变成任何声音。它是实现实时变声的最佳语音变声器。
DaVinci Resolve 19
DaVinci Resolve 19是一款专业的剪辑、调色、特效和音频后期制作软件,它提供一站式的后期制作解决方案,适用于从新手到好莱坞专业人士的广泛用户群体。该软件以其强大的功能、易用性以及支持多种
Read
Read是一个新闻音频生成平台。它可以自动搜集用户感兴趣的内容,生成个性化的每日音频新闻简报,帮助用户高效获取所需信息。该产品拥有人工智能生成的自然语音功能,支持邮件订阅,提供个性化推荐,功能强大。适
Coval
Coval是一个专注于AI代理测试和评估的平台,旨在通过模拟和评估来提高AI代理的可靠性和效率。该平台由自主测试领域的专家构建,支持语音和聊天代理的测试,并提供全面的评估报告,帮助用户优化AI代理的性

EMOVA
EMOVA(EMotionally Omni-present Voice Assistant)是一个多模态语言模型,它能够进行端到端的语音处理,同时保持领先的视觉-语言性能。该模型通过语义-声学解耦的

汉王语音王
汉王语音王App是汉王科技基于自研多模态天地大模型,自主研发的智能语音旗舰应用。它集AI语音记录、智能翻译与同声传译于一体,支持AI精准转写、拍录同步、话稿整理、智能总结及不间断实时翻译等功能。依托全
必剪
必剪是B站官方出品的视频剪辑工具,专为UP主和视频创作者设计,提供海量素材、语音字幕、一键三连、B站投稿等功能,旨在简化视频制作流程,提高创作效率。产品背景依托于B站强大的视频社区,拥有丰富的素材库和
麦耳会记
麦耳会记是一款集实时语音转写、实时翻译和 AI 辅助写作功能为一体的 AI 办公助手。它可以用于办公会议、学生网课、客户访谈录音等场景。软件支持边录音、边转写,录音结束后,音频、文本实时同步至 PC
Zaplingo Talk
Zaplingo Talk是一款AI聊天语伴应用,专为语言学习而设计。通过先进的AI技术,提供高效的语言学习方式。无需担心被评判,Zaplingo Talk提供一个安全和支持性的学习环境。具备Call
Mini-Omni
Mini-Omni是一个开源的多模态大型语言模型,能够实现实时的语音输入和流式音频输出的对话能力。它具备实时语音到语音的对话功能,无需额外的ASR或TTS模型。此外,它还可以在思考的同时进行语音输出,
AI爱好者的一站式人工智能AI工具箱,累计收录全球10,000⁺好用的AI工具软件和网站,方便您更便捷的探索前沿的AI技术。本站持续更新好的AI应用,力争做全球排名前三的AI网址导航网站,欢迎您成为我们的一员。
