首页 >Bangin Audio Recorder和Auralis对比
Bangin Audio Recorder和Auralis哪个好用,Bangin Audio Recorder和Auralis详细对比
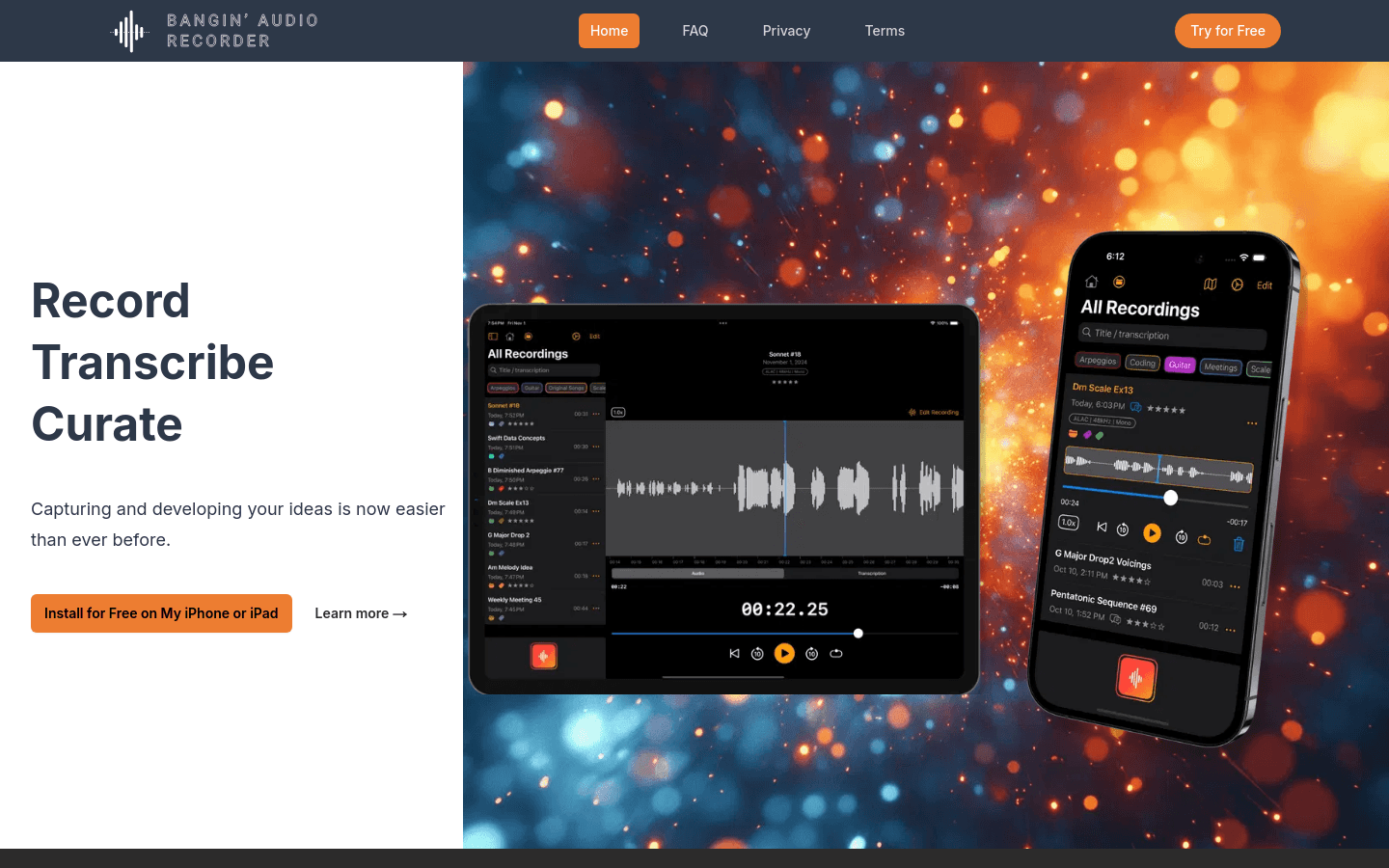
Bangin Audio Recorder:Bangin Audio Recorder是一款专为苹果平台设计的应用程序,旨在简化声音捕捉和想法发展的过程。由音乐作曲家、开发者Alistair Cooper创立,该应用支持高质量单声道或立体声音频录制,具备定制的语音时间戳算法,便于用户扫描和跳过语音录音。它还提供星级评分功能,帮助用户筛选出最佳
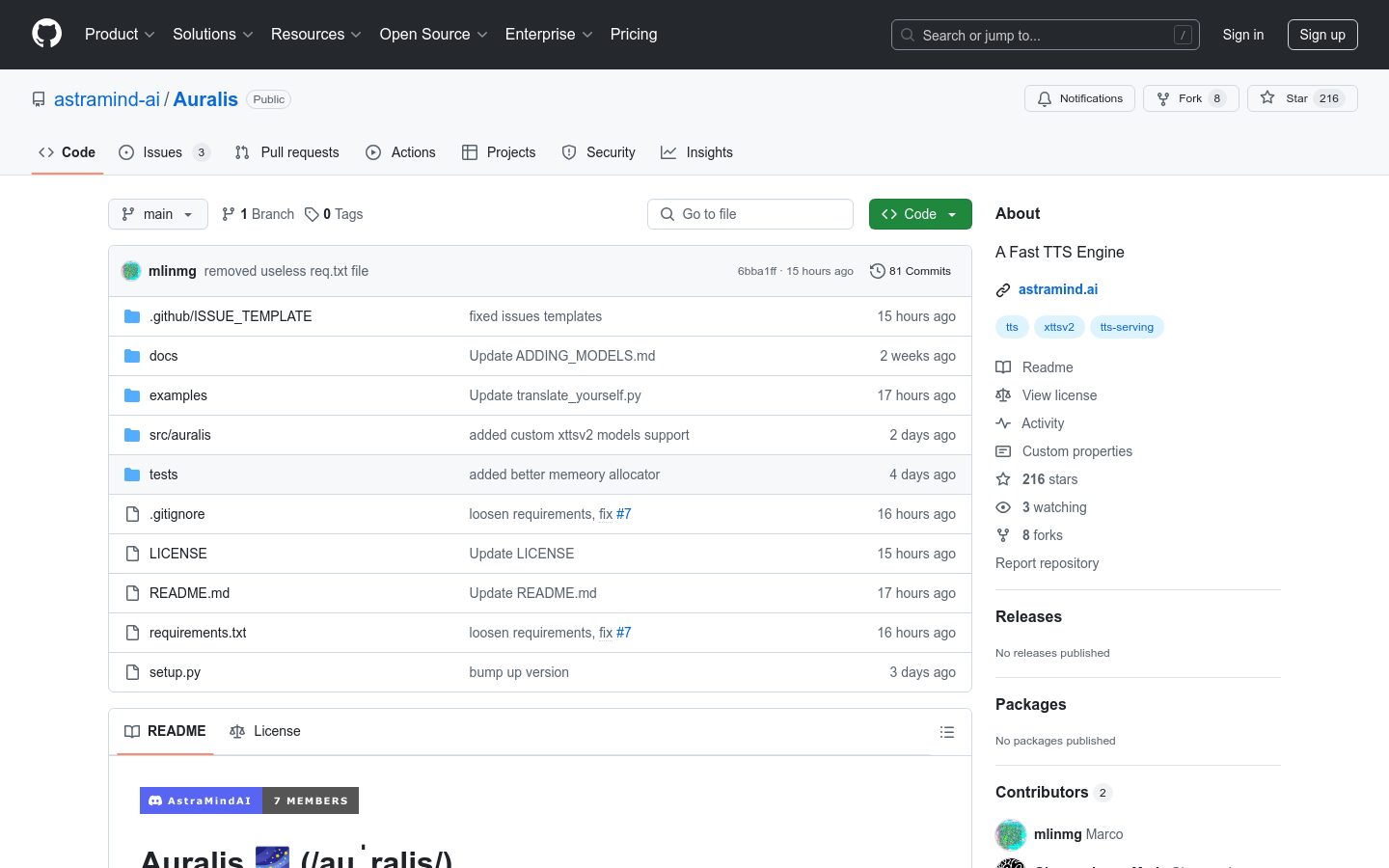
Auralis:Auralis是一个文本到语音(TTS)引擎,能够将文本快速转换为自然语音,支持语音克隆,并且处理速度极快,可以在几分钟内处理完整本小说。该产品以其高速、高效、易集成和高质量的音频输出为主要优点,适用于需要快速文本到语音转换的场景。Auralis基于Python API,支持长文本流式处理、内置音频
Bangin Audio Recorder和Auralis均是AI软件、AI工具中的一种,在功能设计、应用场景、用户体验上存在一些区别,以下是卓商AI整理出来的一些对比选项,仅供您参考。
官网地址
https://www.banginaudiorecorder.com/
https://github.com/astramind-ai/Auralis
功能简介
Bangin Audio Recorder是一款专为苹果平台设计的应用程序,旨在简化声音捕捉和想法发展的过程。由音乐作曲家、开发者Alistair Cooper创立,该应用支持高质量单声道或立体声音频录制,具备定制的语音时间戳算法,便于用户扫描和跳过语音录音。它还提供星级评分功能,帮助用户筛选出最佳创意,并支持标签、项目和搜索功能,以保持用户对重要录音的专注。此外,它还具备iCloud同步功能,确保用户在所有苹果设备上的录音保持最新。
Auralis是一个文本到语音(TTS)引擎,能够将文本快速转换为自然语音,支持语音克隆,并且处理速度极快,可以在几分钟内处理完整本小说。该产品以其高速、高效、易集成和高质量的音频输出为主要优点,适用于需要快速文本到语音转换的场景。Auralis基于Python API,支持长文本流式处理、内置音频增强、自动语言检测等功能。产品背景信息显示,Auralis由AstraMind AI开发,旨在提供一种实用于现实世界应用的文本到语音解决方案。产品价格未在页面上明确标注,但代码库在Apache 2.0许可下发布,可以免费用于项目中。
排名榜单 🔥
可平替产品
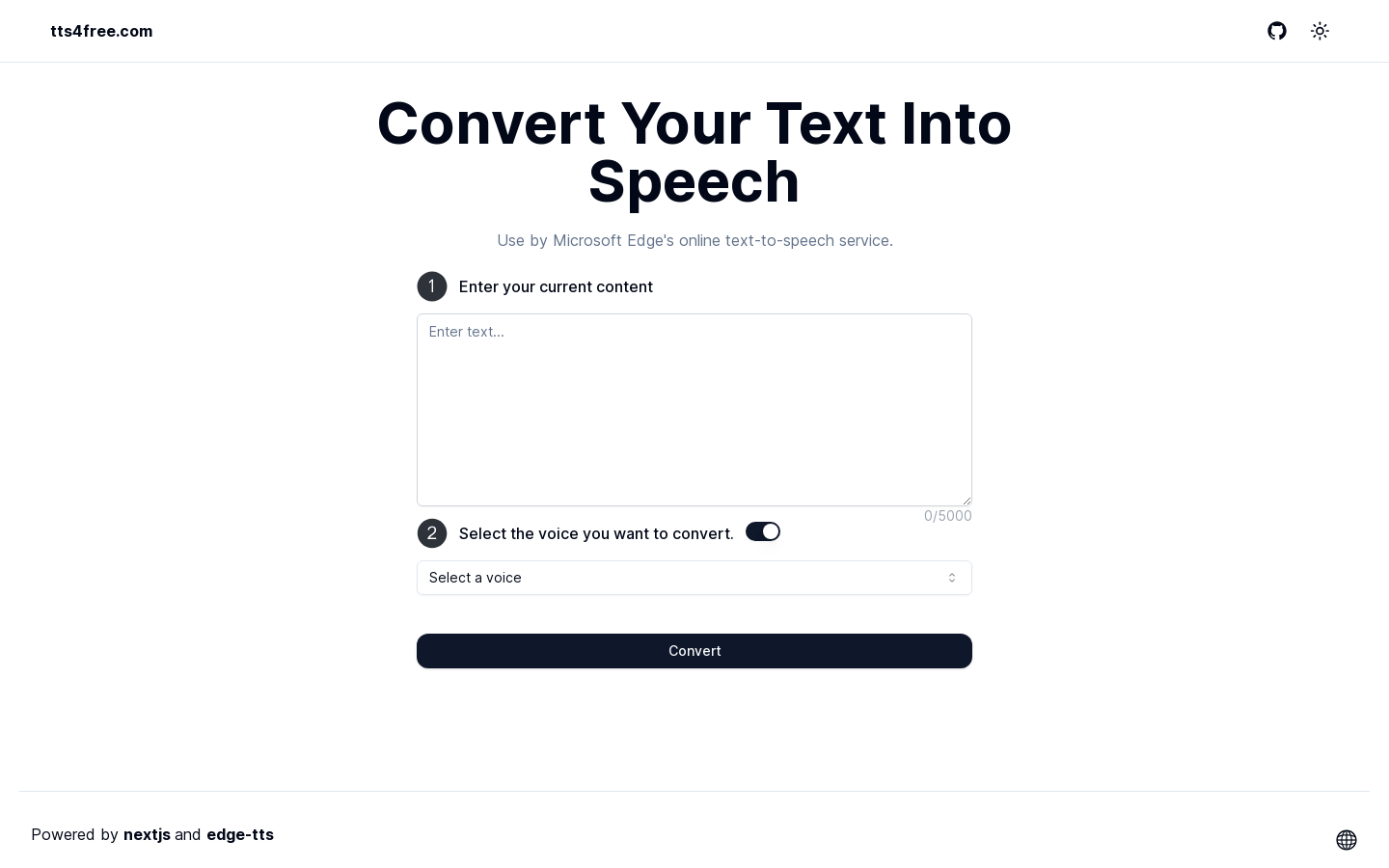
free text Into Speech
Free Text to Speech Online Converter是一个多语言文本转语音的在线平台。它支持超过20种语言,拥有自然的发音,无需注册即可免费使用,转换速度快。
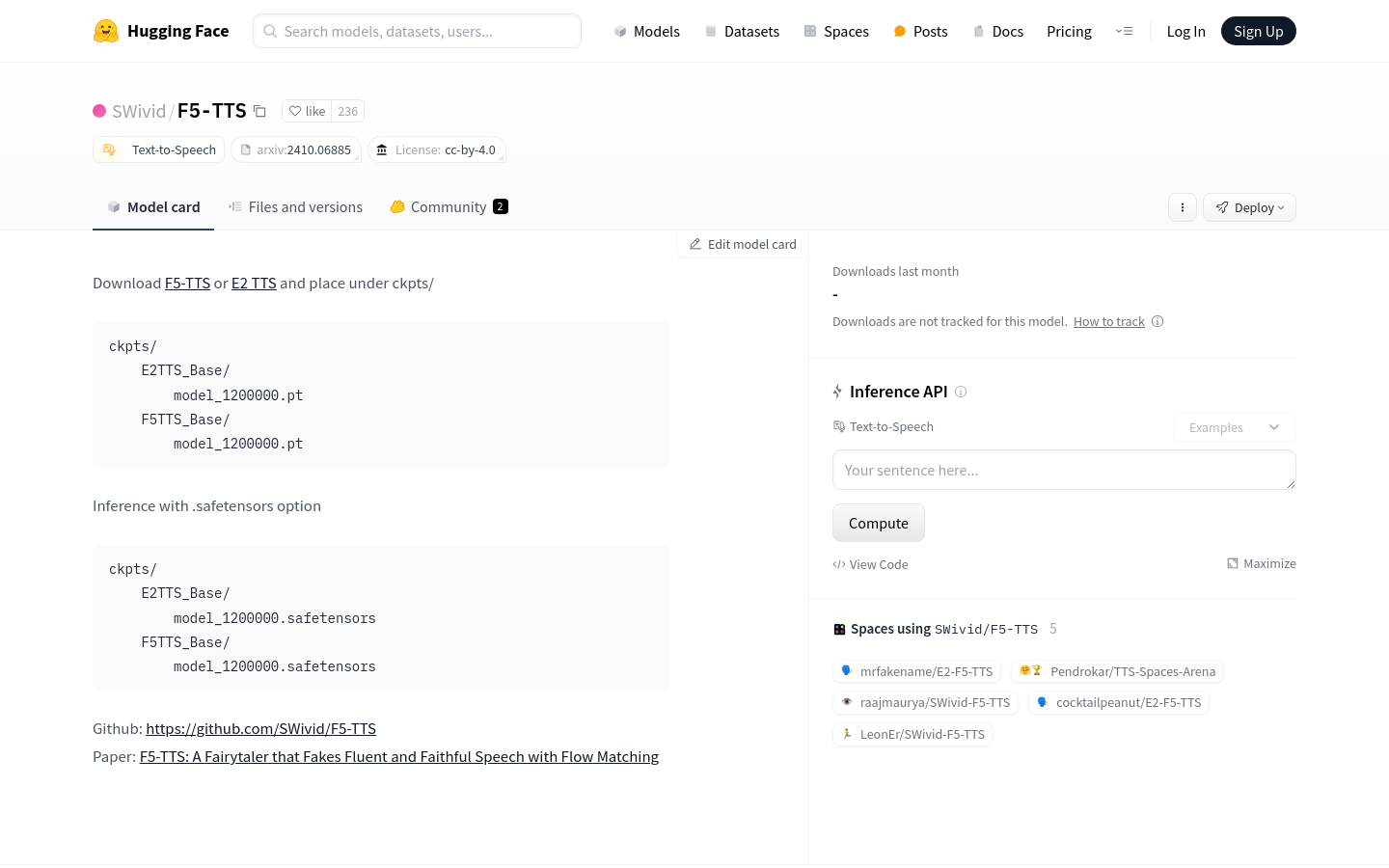
F5-TTS
F5-TTS是由SWivid团队开发的一个文本到语音合成(TTS)模型,它利用深度学习技术将文本转换为自然流畅、忠实于原文的语音输出。该模型在生成语音时,不仅追求高自然度,还注重语音的清晰度和准确性,
Ibis
Ibiskey是一款可以打破语言障碍,让您无论与朋友、家人还是团队交流,都能自由地使用自己的语言进行打字、语音、阅读和听力的产品。我们提供实时聊天翻译、语音翻译、网站自动翻译等功能,支持130多种语言

Music ControlNet
Music ControlNet 是一种基于扩散的音乐生成模型,可以提供多个精确的、时变的音乐控制。它可以根据旋律、动态和节奏控制生成音频,并且可以部分指定时间上的控制。与其他音乐生成模型相比,Mus
必剪
必剪是B站官方出品的视频剪辑工具,专为UP主和视频创作者设计,提供海量素材、语音字幕、一键三连、B站投稿等功能,旨在简化视频制作流程,提高创作效率。产品背景依托于B站强大的视频社区,拥有丰富的素材库和
MeloTTS
MeloTTS是由MyShell.ai开发的多语言文本转语音库,支持英语、西班牙语、法语、中文、日语和韩语。它能够实现实时CPU推理,适用于多种场景,并且对开源社区开放,欢迎贡献。
Llasa-3B
Llasa-3B 是一个强大的文本到语音(TTS)模型,基于 LLaMA 架构开发,专注于中英文语音合成。该模型通过结合 XCodec2 的语音编码技术,能够将文本高效地转换为自然流畅的语音。其主要优
Text2Multimedia
Text2Multimedia是一款使用开源AI模型将文本转换为图像或语音的工具。该工具提供了文本转图像和文本转语音的功能,用户可以通过描述文本来生成对应的视觉或声音表达。生成的图像和音频质量取决于算

ApolloAI
ApolloAI是一款人工智能平台,提供AI图像、视频、音乐、语音合成等功能。用户可以通过文本或图片输入生成多种类型的内容,具备商业使用权。定价灵活,提供订阅和一次性购买两种模式。
Nonoisy
Nonoisy是一款智能音频后期处理工具,通过智能算法和人工智能,用户可以轻松上传音频文件,进行后期制作。去除背景噪音、音频处理、音量平衡等工作都由Nonoisy来完成,让用户专注于创作内容。产品定位
VoiceReplace
VoiceReplace是一个AI语音替换工具,可以用AI替换您的声音,创造广告或社交媒体上的新内容。自动同步功能确保AI在适当的时间说出正确的内容。加入早期访问计划,获得终身特别折扣。
VoiceDrop.ai
VoiceDrop.Ai是一款声音复制技术产品,可实现声音克隆并批量应用。它能够让您录制您的声音,并为每个接收者提供独特的声音消息,为您创造与众不同的体验。VoiceDrop.Ai的优势包括技术进步、
Smallest AI
Smallest AI 是一家专注于提供实时 AI 服务的公司,旗下 Waves 和 Atoms 产品分别专注于生成高质量的 AI 语音和提供实时 AI 客服代理。Waves 能够实时生成任何口音、语
Whisper large-v3-turbo
Whisper large-v3-turbo是OpenAI提出的一种先进的自动语音识别(ASR)和语音翻译模型。它在超过500万小时的标记数据上进行训练,能够在零样本设置中泛化到许多数据集和领域。该模

EngineerDraft
BeMyEars 是一款实时字幕生成工具,利用本地设备完成语音识别,为听障人士和需要字幕的用户提供极致体验。其主要优点包括多语言支持、多源输入、隐私保护等。
Voscribe
Voscribe 是一款免费转录工具,可以将音频文件转换为文本。它支持将 MP3 转换为文本、MP4 转换为文本等多种格式,并能在 2 分钟内以 95% 的准确度提供可编辑的转录文本。
NVAS3d
NVAS3d是一个用于估计包含多个未知声源的场景中任何位置的声音的项目,通过使用多个麦克风的音频录音和场景的3D几何和材料,实现了新视角声学合成。
Whisper Speech
Whisper Speech是一款完全开源的文本转语音模型,由Collabora和Lion在Juwels超级计算机上训练。它支持多种语言和多种形式的输入,包括Node.js、Python、Elixir
audio2photoreal
audio2photoreal是一个从音频生成照片级逼真avatar的开源项目。它包含了一个pytorch实现,可以从音频中合成交谈中的人类形象。该项目提供了训练代码、测试代码、预训练的运动模型以及数
Transcriptmate.com
Transcriptmate是一个在线音频转文本的服务。它可以将长达3小时的录音文件转换成文本文件,并在2小时内通过电子邮件发送给您。转换结果可以以csv、srt、txt等多种格式保存。Transcr
Azure 认知服务语音
Azure 认知服务语音是微软推出的一款语音识别与合成服务,支持超过100种语言和方言的语音转文本和文本转语音功能。它通过创建可处理特定术语、背景噪音和重音的自定义语音模型,提高听录的准确度。此外,该
Media.io
Media.io 是一个在线平台,提供一系列便携式的 AI 工具,用于视频、音频和图像编辑。它提供了视频卡通化、AI 头像生成器、图像增强器和水印去除器等功能。Media.io 还提供了其他视频和音频
DaVinci Resolve 19
DaVinci Resolve 19是一款专业的剪辑、调色、特效和音频后期制作软件,它提供一站式的后期制作解决方案,适用于从新手到好莱坞专业人士的广泛用户群体。该软件以其强大的功能、易用性以及支持多种
Universal-2
Universal-2是AssemblyAI推出的最新语音识别模型,它在准确度和精确度上超越了前一代Universal-1,能够更好地捕捉人类语言的复杂性,为用户提供无需二次检查的音频数据。这一技术的
AI爱好者的一站式人工智能AI工具箱,累计收录全球10,000⁺好用的AI工具软件和网站,方便您更便捷的探索前沿的AI技术。本站持续更新好的AI应用,力争做全球排名前三的AI网址导航网站,欢迎您成为我们的一员。
