首页 >Adobe Podcast和ElevenLabs GenFM对比
Adobe Podcast和ElevenLabs GenFM哪个好用,Adobe Podcast和ElevenLabs GenFM详细对比
Adobe Podcast:Adobe Podcast是一款基于人工智能技术的音频录制和编辑工具。它提供清晰、高质量的音频录制和编辑功能,支持自动转录、剪辑和分享。无论您是专业的播客主持人还是想要创作自己的播客节目,Adobe Podcast都可以满足您的需求。它还提供多种音频效果和工具,帮助您创建独特而专业的音频内容。Ado
ElevenLabs GenFM:ElevenReader 是一款利用人工智能技术将PDF、文章、电子书等文本内容转化为播客的应用。它通过AI技术生成智能播客,让用户在任何时间、任何地点都能聆听内容。产品背景信息显示,ElevenLabs致力于通过高质量的AI音频技术,帮助用户以全新的方式消费和体验内容。GenFM on Eleve
Adobe Podcast和ElevenLabs GenFM均是AI软件、AI工具中的一种,在功能设计、应用场景、用户体验上存在一些区别,以下是卓商AI整理出来的一些对比选项,仅供您参考。
官网地址
https://podcast.adobe.com
功能简介
Adobe Podcast是一款基于人工智能技术的音频录制和编辑工具。它提供清晰、高质量的音频录制和编辑功能,支持自动转录、剪辑和分享。无论您是专业的播客主持人还是想要创作自己的播客节目,Adobe Podcast都可以满足您的需求。它还提供多种音频效果和工具,帮助您创建独特而专业的音频内容。Adobe Podcast定价灵活,适用于个人和团队使用。
ElevenReader 是一款利用人工智能技术将PDF、文章、电子书等文本内容转化为播客的应用。它通过AI技术生成智能播客,让用户在任何时间、任何地点都能聆听内容。产品背景信息显示,ElevenLabs致力于通过高质量的AI音频技术,帮助用户以全新的方式消费和体验内容。GenFM on ElevenReader支持多种语言,满足全球用户的需求。
排名榜单 🔥
可平替产品
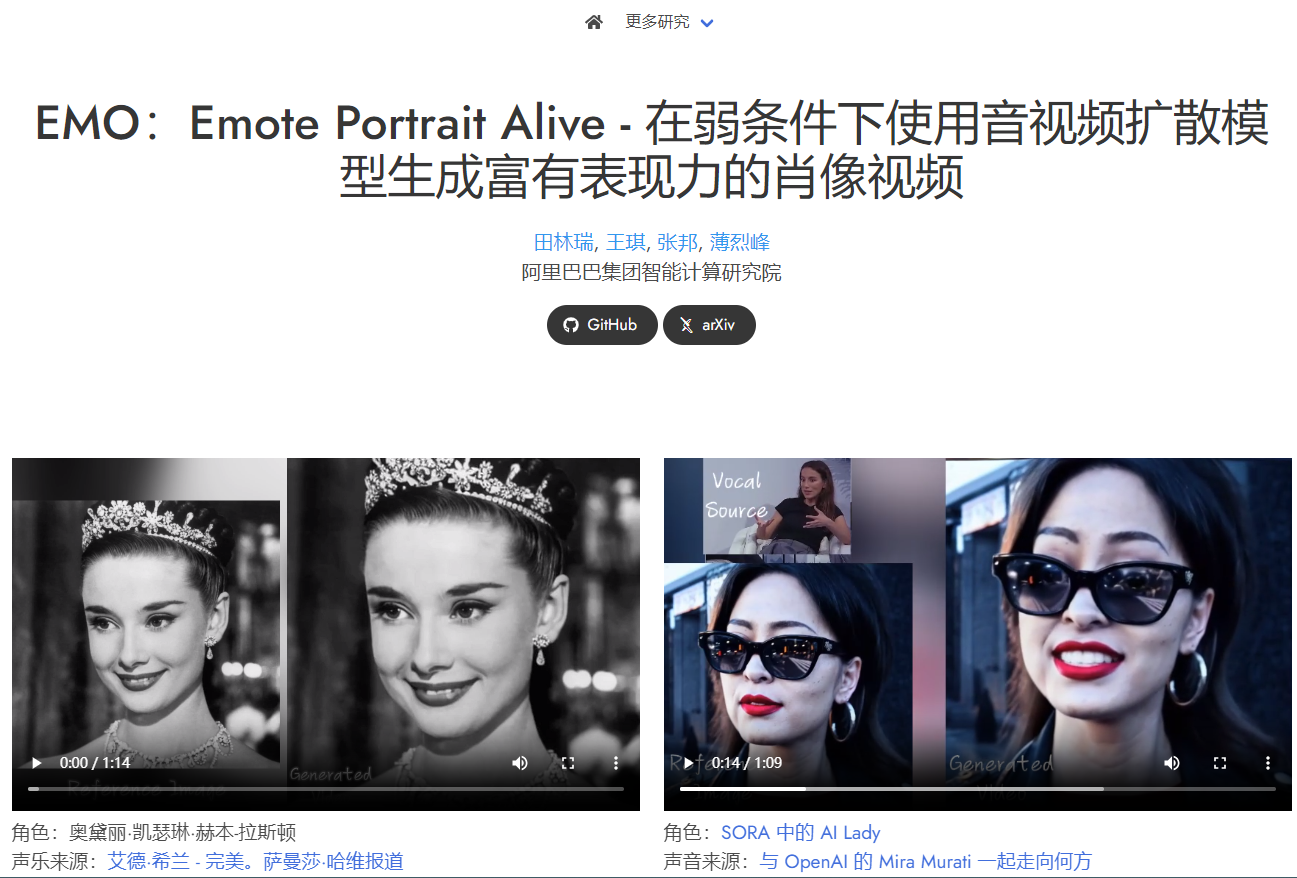
EMO
阿里巴巴的EMO: 是一款生成具有表情丰富的面部表情视频的工具,可以根据输入的角色图像和声音音频生成各种头部姿势和表情的声音头像视频。支持多语言歌曲和各种肖像风格,能够根据音频节奏生成动态、表现丰富
SFX Engine
SFX Engine是一个AI声音效果生成器,专为音频制作人、视频编辑和游戏开发者设计。它提供了一个平台,用户可以通过AI技术生成定制的声音效果,用于电影、游戏、音乐制作等项目。该技术的主要优点是能够
Whisper-Input
Whisper Input 是一个基于 Python 开发的桌面工具,能够实现快速语音转文字功能。它支持通过按键控制录制语音,并调用 Groq Whisper Large V3 Turbo 或 Fun
讯飞A.I.智能客服解决方案
A.I.智能客服解决方案是科大讯飞基于其先进的语音技术,为企业提供的一套完整的客户服务系统。该系统通过电话、Web、APP、小程序、自助终端等多种渠道,实现智能外呼、智能接听、语音导航、在线文字客服、
Transcribro
Transcribro是一款运行在Android平台上的私有、设备端语音识别键盘和文字服务应用,它使用whisper.cpp来运行OpenAI Whisper系列模型,并结合Silero VAD进行语
Recall.ai Output Media
Recall.ai Output Media是一个创新的AI技术,它允许用户将任何基于Web的AI应用实时集成到视频会议中。这项技术通过渲染超低延迟的音频和视频,并通过机器人将其流式传输到视频会议中,

Decoherence
Decoherence是一个AI音乐视频生成工具,通过生成式AI技术,将您的想法转化为完美的音乐视频。具有音频反应、多种AI风格选择、时间线编辑和起始帧生成等功能。适用于创造独特的音乐视频。
AudiowaveAI
AudiowaveAI是一款利用人工智能技术将文本转换成高质量音频的应用程序。它与传统的文本到语音技术不同,提供了更加自然、富有情感的语音输出,让听众在学习和享受内容时获得更好的听觉体验。产品背景信息
Simplify Your Audio Production
Simplify Your Audio Production是一个利用人工智能技术生成独特音效的网站,它允许用户通过文本描述或上传图片来创建个性化的音效。这项技术简化了音频制作流程,节省了从视频等其他

Clone Anyones voice in seconds with AI
克隆我的声音是一个能够在几秒钟内克隆任何人的声音,并将其应用于任何音频内容的产品。即使作为一个英语初学者,您也可以获得一个出色的英语声音和发音。它可以立即提升您的音频内容质量,您可以轻松准确地为演讲、
理想同学
理想同学是由理想汽车依托自研大模型精心打造的一款人工智能应用,旨在为用户提供一个随时在线的智能助手。它具备知识问答能力,能解答汽车、出行、财经、科技等领域的问题,并擅长英文词句翻译、文本生成等,助力用
Syndy
Syndy是一个AI创造播客的平台。它使用先进的人工智能技术,帮助用户创造出他们想要听的播客内容。Syndy提供了丰富的功能,包括语音合成、音频编辑、内容推荐等。用户可以根据自己的喜好和需求,定制出独
Sound Effect Generator
Sound Effect Generator是一个利用AI技术为用户提供个性化音频创作的平台。它结合了专业的声音设计和前沿的AI技术,让用户能够快速将想法转化为高质量的音频。这个平台不仅适合寻找特定声
Emilia
Emilia是一个开源的多语种野外语音数据集,专为大规模语音生成研究设计。它包含超过101,000小时的六种语言高质量语音数据和相应的文本转录,覆盖了各种说话风格和内容类型,如脱口秀、访谈、辩论、体育
Vocal Remover and Isolation
vocalremover org是一个在线音轨分离工具,可以将音乐中的人声和伴奏分离出来。它具有简单易用的界面,能够快速高效地分离音轨,并且可以导出分离后的音频文件。vocalremover org支
Pandrator
Pandrator 是一个基于开源软件的工具,能够将文本、PDF、EPUB 和 SRT 文件转换成多种语言的语音音频,包括语音克隆、基于LLM的文本预处理以及将生成的字幕音频直接保存到视频文件中,与视
AI Toolbar
AI Toolbar是一款功能强大高效的智能工具栏,已有近10万次下载,可以帮助你节省时间,处理电子邮件,进行语音控制,多语言翻译,与聊天机器人互动等。它与Chatgpt无缝集成,提供超过300种可组
Jellypod
Jellypod+是一款将您的电子邮件订阅转化为个人播客的应用程序。它以音频为主要形式,为您忙碌的生活方式生成您每日新闻的简明摘要。Jellypod+的目标是打破传统媒体的“一刀切”模式,为您量身定制

StreamVoice
StreamVoice是一种基于语言模型的零唇语音转换模型,可实现实时转换,无需完整的源语音。它采用全因果上下文感知语言模型,结合时间独立的声学预测器,能够在每个时间步骤交替处理语义和声学特征,从而消
Clone Anyones voice in seconds with AI
克隆我的声音是一个能够在几秒钟内克隆任何人的声音,并将其应用于任何音频内容的产品。即使作为一个英语初学者,您也可以获得一个出色的英语声音和发音。它可以立即提升您的音频内容质量,您可以轻松准确地为演讲、
ToucanTTS
ToucanTTS是由德国斯图加特大学自然语言处理研究所开发的多语言且可控的文本到语音合成工具包。它使用纯Python和PyTorch构建,以保持简单、易于上手,同时尽可能强大。该工具包支持教学、训练
botsplash.com
Botsplash是一款能够让您在聊天平台上与客户互动的一站式解决方案。它集成了多个渠道,通过一个基于SaaS的仪表板实现与客户的沟通。Botsplash能够帮助您提高收入、降低成本、生成更多潜在客户

MusicLM
MusicLM是一个模型,可以根据文本描述生成高保真音乐。它可以生成24kHz的音频,音乐风格和文本描述一致,并支持根据旋律进行条件生成。通过使用MusicCaps数据集,模型在音频质量和与文本描述的
SpeechGPT
SpeechGPT是一种多模态语言模型,具有内在的跨模态对话能力。它能够感知并生成多模态内容,遵循多模态人类指令。SpeechGPT-Gen是一种扩展了信息链的语音生成模型。SpeechAgents是
AI爱好者的一站式人工智能AI工具箱,累计收录全球10,000⁺好用的AI工具软件和网站,方便您更便捷的探索前沿的AI技术。本站持续更新好的AI应用,力争做全球排名前三的AI网址导航网站,欢迎您成为我们的一员。
