首页 >TranscribeMe和讯飞虚拟人对比
TranscribeMe和讯飞虚拟人哪个好用,TranscribeMe和讯飞虚拟人详细对比
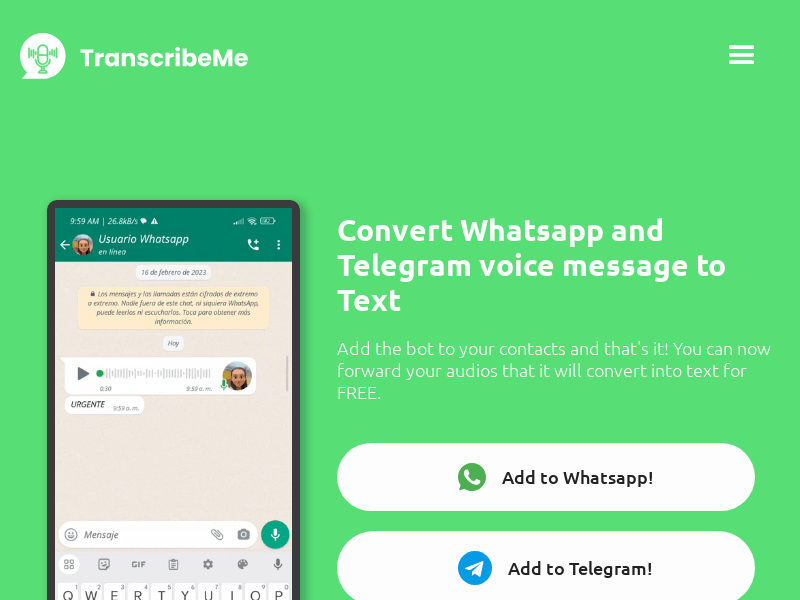
TranscribeMe:TranscribeMe是一款将Whatsapp和Telegram语音消息转化为文字的智能工具。它可以帮助用户免费将语音转换为文本,支持在Whatsapp和Telegram中直接使用。该工具注重用户隐私,不会保存或存储任何音频文件。同时,它还具备实时翻译和语言选择功能,帮助用户打破语言障碍。Tran
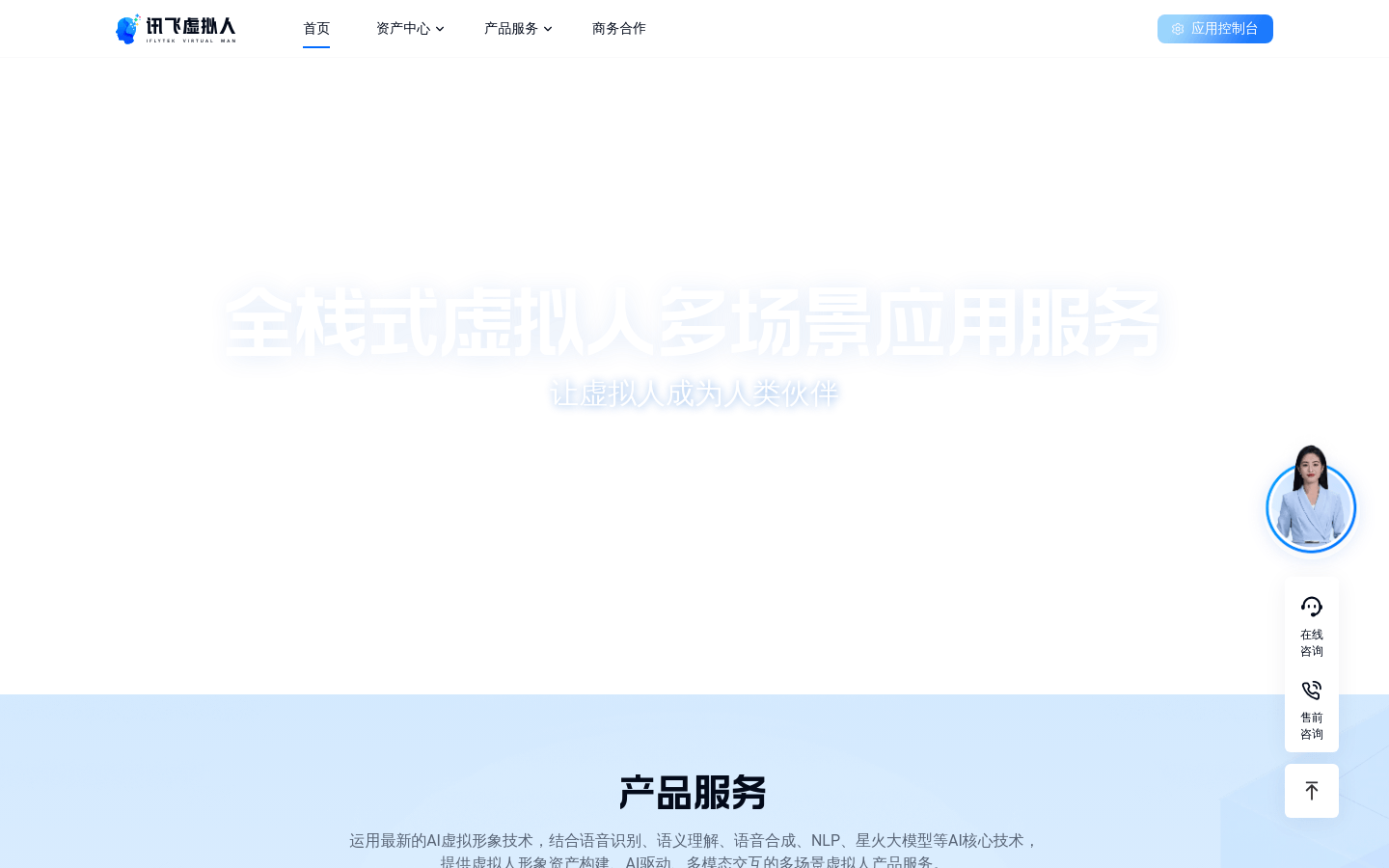
讯飞虚拟人:讯飞虚拟人利用最新的AI虚拟形象技术,结合语音识别、语义理解、语音合成、NLP、星火大模型等AI核心技术,提供虚拟人形象资产构建、AI驱动、多模态交互的多场景虚拟人产品服务。一站式虚拟人音视频内容生产,AIGC助力创作灵活高效;在虚拟AI演播室中输入文本或录音,一键完成音、视频作品的输出,3分钟内渲
TranscribeMe和讯飞虚拟人均是AI软件、AI工具中的一种,在功能设计、应用场景、用户体验上存在一些区别,以下是卓商AI整理出来的一些对比选项,仅供您参考。
官网地址
https://www.transcribeme.app/en
https://virtual-man.xfyun.cn/
功能简介
TranscribeMe是一款将Whatsapp和Telegram语音消息转化为文字的智能工具。它可以帮助用户免费将语音转换为文本,支持在Whatsapp和Telegram中直接使用。该工具注重用户隐私,不会保存或存储任何音频文件。同时,它还具备实时翻译和语言选择功能,帮助用户打破语言障碍。TranscribeMe提供免费计划和PLUS计划,PLUS计划可享受更多功能和服务。用户可以根据自己的需求选择适合的计划。如果您对我们的开发感兴趣,欢迎与我们联系。
讯飞虚拟人利用最新的AI虚拟形象技术,结合语音识别、语义理解、语音合成、NLP、星火大模型等AI核心技术,提供虚拟人形象资产构建、AI驱动、多模态交互的多场景虚拟人产品服务。一站式虚拟人音视频内容生产,AIGC助力创作灵活高效;在虚拟AI演播室中输入文本或录音,一键完成音、视频作品的输出,3分钟内渲染出稿。
排名榜单 🔥
可平替产品
PengChengStarling
PengChengStarling 是一个专注于多语言自动语音识别(ASR)的开源工具包,基于 icefall 项目开发。它支持完整的 ASR 流程,包括数据处理、模型训练、推理、微调和部署。该工具包
Gemini 2.0 Flash-Lite
Gemini 2.0 Flash-Lite 是 Google 推出的高效语言模型,专为长文本处理和复杂任务优化。它在推理、多模态、数学和事实性基准测试中表现出色,具备简化的价格策略,使得百万级上下文窗

Podcastle AI
Podcastle AI可以将您撰写的新闻和文章、博客文章即时转换为播客,并在我们的全方位基于Web的协作播客创建平台中继续编辑您的播客。\n价格:免费使用,付费计划可提供额外功能。\n定位:帮助用户
Luvvoice
Luvvoice是一个免费的文字转语音工具,提供200多种声音选择,可根据用户需求将文本转化为语音。Luvvoice具有易用性、多语言支持和高质量的声音合成等优势。Luvvoice的定价非常实惠,让用
celebrity ai voice generator
Celebrity AI Voice Generator是一个免费的在线工具,可以快速生成任何名人的语音。它使用先进的AI技术,通过分析名人的声音样本来模拟和生成他们的语音。用户只需输入名人的名称,即

Earkind
Earkind是一个通过结合语言模型和神经表达文本转语音技术,生成播客节目描述的平台。它使用新闻和研究论文列表来自动生成完整的播客剧集描述,同时提供有趣的内容。用户可以听取由主持人Giovani Pe
Riverside
Riverside是一款准确的AI转录工具,可以快速将音频和视频转录为文字。它支持100多种语言,提供完全免费的准确AI转录服务。除了转录功能,Riverside还提供了实时编辑、多人协作和高音质录音
Fish Speech V1.2
Fish Speech V1.2是一款基于300,000小时的英语、中文和日语音频数据训练而成的文本到语音(TTS)模型。该模型代表了语音合成技术的最新进展,能够提供高质量的语音输出,适用于多种语言环
Writecream
Writecream是一款基于AI的写作助手,可以帮助您生成个性化的博客文章、广告文案、语音转换、电子商务产品描述等内容。它提供了35种写作工具,支持70种语言。Writecream是您进行冷邮件、市
BASE TTS
BASE TTS是亚马逊开发的大规模文本到语音合成模型,运用了10亿参数的自动回归转换器,可将文本转换成语音代码,再通过卷积解码器生成语音波形。该模型使用了超过10万小时的公共语音数据进行训练,实现了
GPT-Minus1
PGPT-Minus1是一款在线文本转录工具,可以将您的音频文件转录为完美的文本。它使用最先进的语音识别技术,支持多种语言和文件格式。GPT-Minus1的优势在于准确性高、速度快、易于使用。
Hamming
Hamming是一个端到端的AI语音代理测试平台,支持从开发到生产的全流程。它通过自动化语音角色创建成千上万的并发电话呼叫,以测试和发现语音代理中的bug,显著提高测试效率。此外,Hamming还提供
FunClip
FunClip是一款完全开源、本地部署的自动化视频剪辑工具,通过调用阿里巴巴通义实验室开源的FunASR Paraformer系列模型进行视频的语音识别,随后用户可以自由选择识别结果中的文本片段或说话
Hanami Live Translator
Hanami Live Translator是一个实时翻译器,可以捕捉来自WINDOWS扬声器和麦克风的任何音频。它使用轻量级多进程和分块处理音频,每个块处理时间约为3-5秒。该应用程序通过低级访问创
Speechless
Speechless 是一款基于 OpenAI 的 Whisper API 的终极应用,提供无缝的音频转录和翻译功能。通过 Speechless,您可以轻松导入音频并即时获取准确的转录。通过实时翻译打

hertz-dev
hertz-dev是Standard Intelligence开源的全双工、仅音频的变换器基础模型,拥有85亿参数。该模型代表了可扩展的跨模态学习技术,能够将单声道16kHz语音转换为8Hz潜在表示,
AV-HuBERT
AV-HuBERT是一个自监督表示学习框架,专门用于音视觉语音处理。它在LRS3音视觉语音基准测试中实现了最先进的唇读、自动语音识别(ASR)和音视觉语音识别结果。该框架通过掩蔽多模态聚类预测来学习音
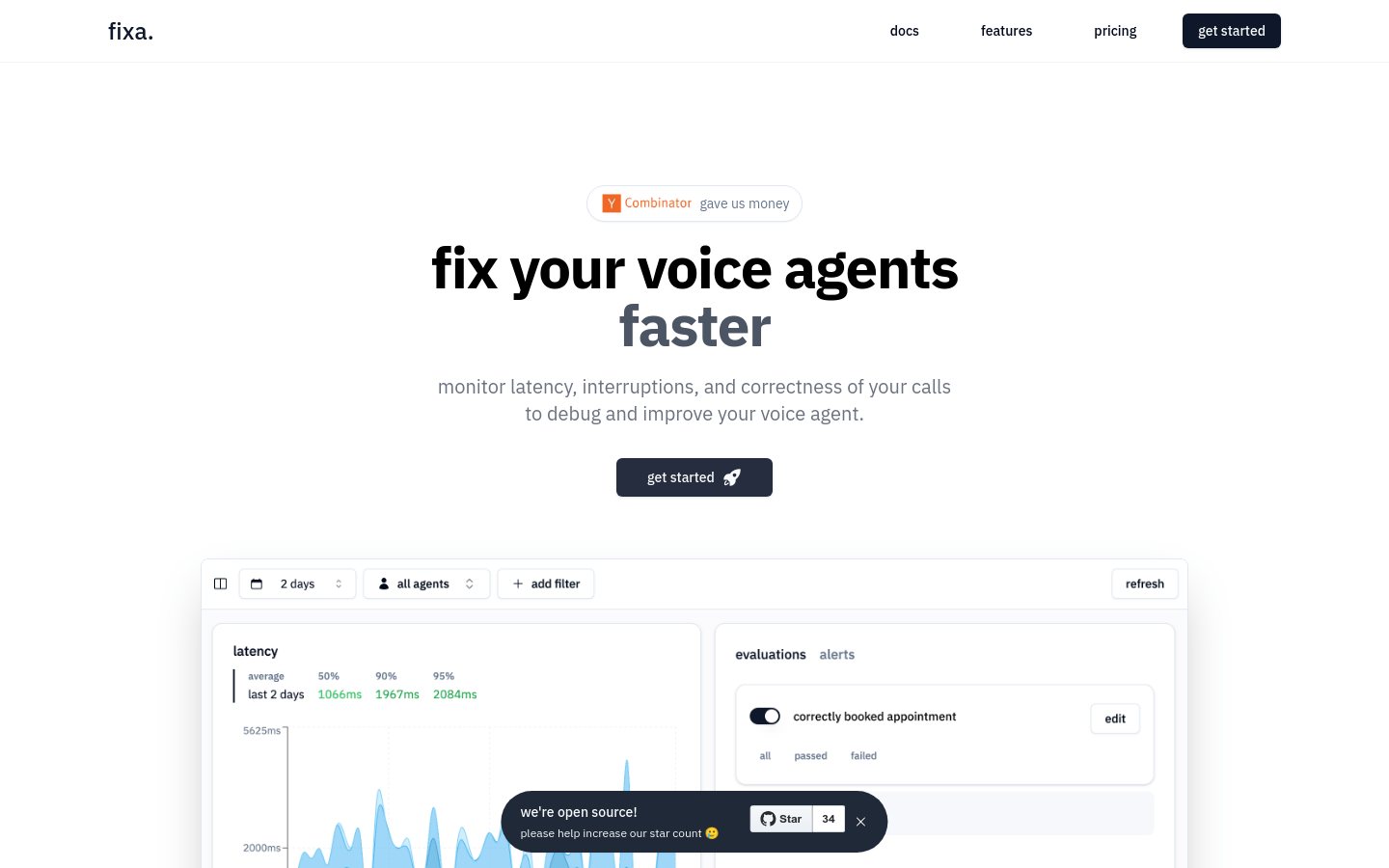
fixa
fixa是一个专注于AI语音代理测试与可观测性的平台,旨在帮助开发者和企业快速发现并修复语音代理中的问题。通过自动化测试、生产监控和错误检测等功能,确保语音代理的稳定性和可靠性。该平台由Y Combi
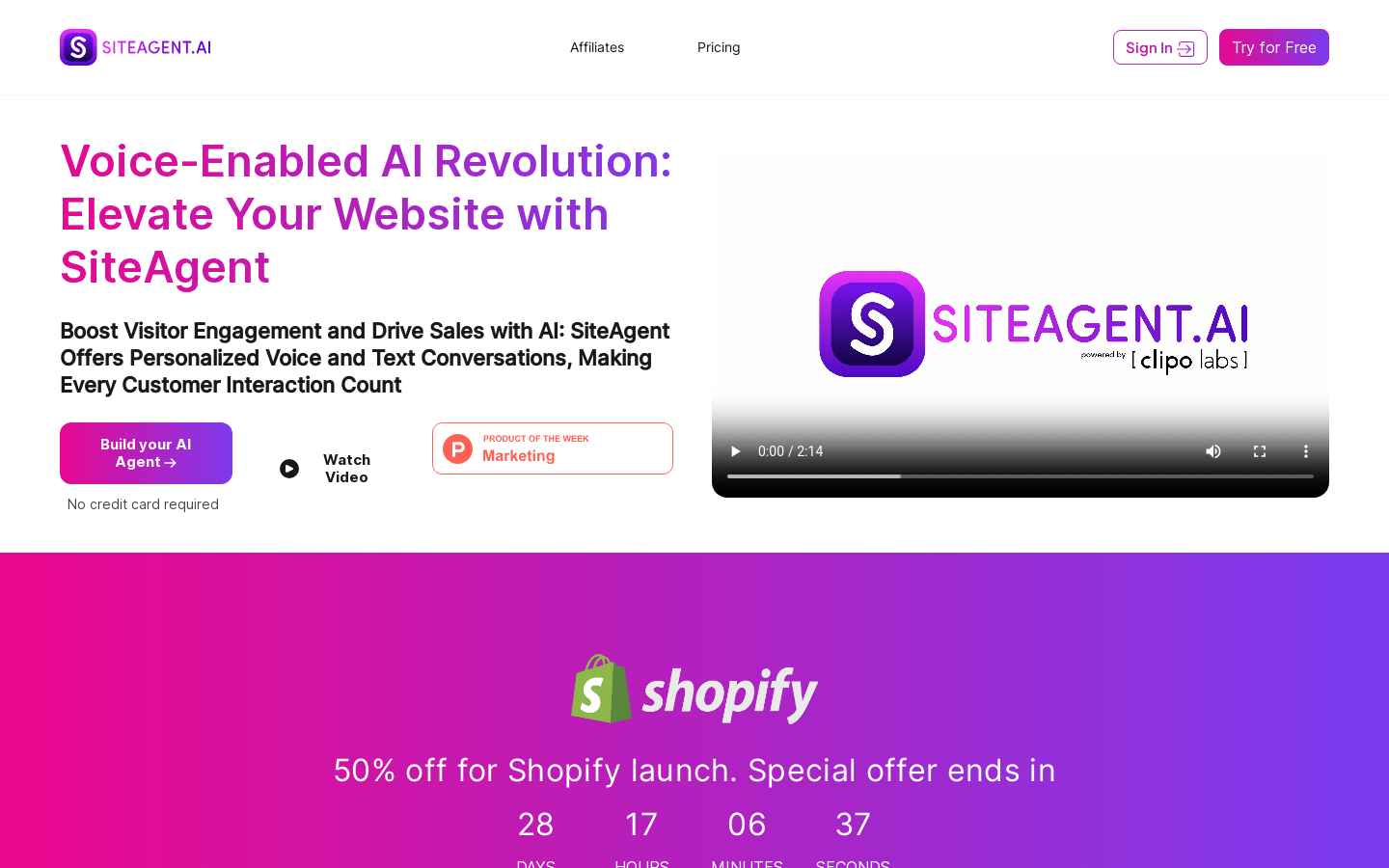
SiteAgent.AI
Site Agent是一款AI语音助手产品,能够个性化地与访问网站的用户进行语音和文字对话,提升用户参与度并促进销售。它结合了最新的AI技术和类似人类对话的细腻触感,为每个客户互动带来价值。Site
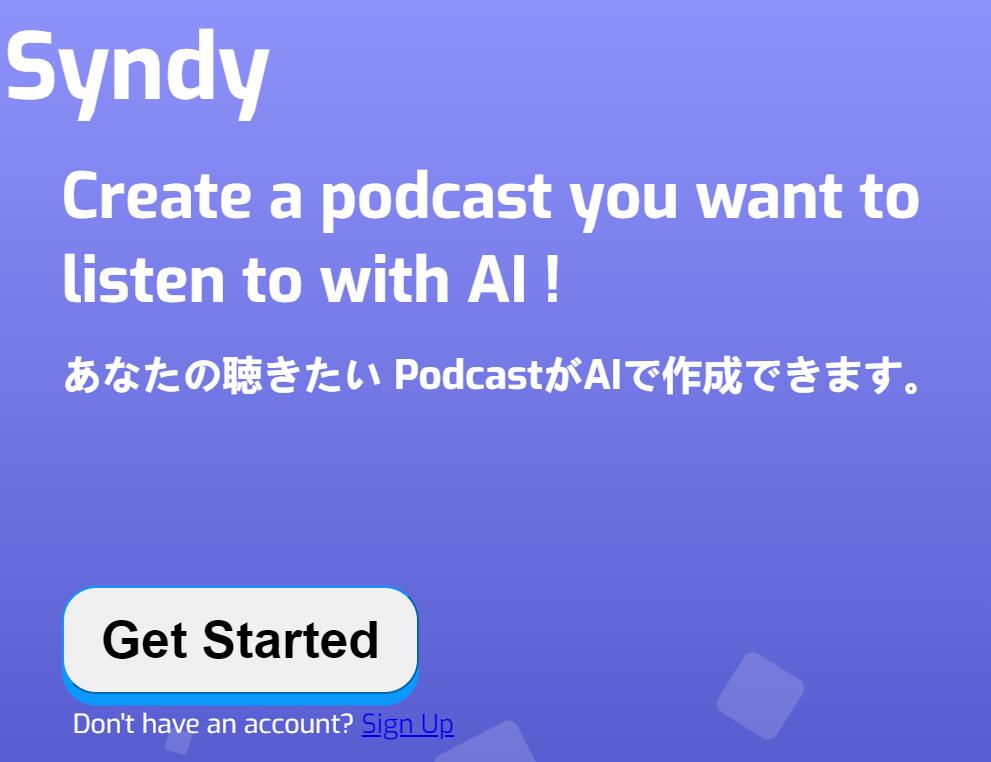
Syndy
Syndy是一个AI创造播客的平台。它使用先进的人工智能技术,帮助用户创造出他们想要听的播客内容。Syndy提供了丰富的功能,包括语音合成、音频编辑、内容推荐等。用户可以根据自己的喜好和需求,定制出独
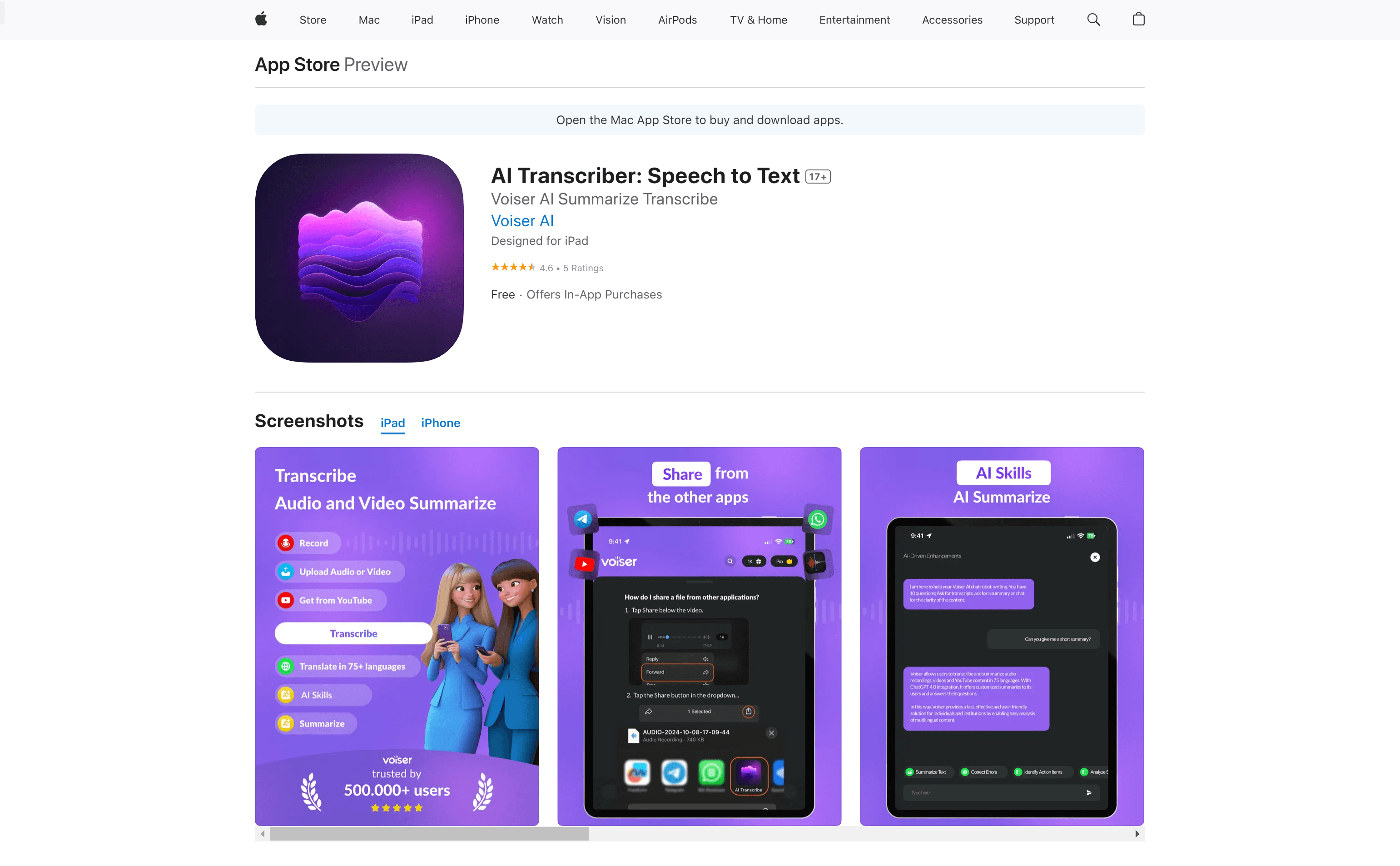
Voiser AI AI Transcriber
AI Transcriber: Speech to Text 是一款利用人工智能技术将语音备忘录、会议、访谈和视频转换成文字的应用。它不仅支持WhatsApp语音转录和通话录音转录,还具备多语言支持和

Notebooklm Podcast
Notebooklm Podcast 是一个创新的在线服务,它使用先进的人工智能技术将学术论文、文章、书籍或任何文本转换成引人入胜的对话式音频内容。这种服务非常适合学生、专业人士和终身学习者在移动中探
Vocera
Vocera是一个由Y Combinator支持的AI语音代理测试与监控平台,它允许用户通过模拟各种场景和使用真实音频来测试和评估AI语音代理的性能。该平台的主要优点在于能够快速启动测试,减少将AI代
Qwen2-Audio
Qwen2-Audio是由阿里云提出的大型音频语言模型,能够接受各种音频信号输入,并根据语音指令进行音频分析或直接文本回复。该模型支持两种不同的音频交互模式:语音聊天和音频分析。它在13个标准基准测试
AI爱好者的一站式人工智能AI工具箱,累计收录全球10,000⁺好用的AI工具软件和网站,方便您更便捷的探索前沿的AI技术。本站持续更新好的AI应用,力争做全球排名前三的AI网址导航网站,欢迎您成为我们的一员。
