首页 >VideoChat和讯飞虚拟人对比
VideoChat和讯飞虚拟人哪个好用,VideoChat和讯飞虚拟人详细对比
VideoChat:VideoChat是一个实时语音交互数字人项目,支持端到端语音方案(GLM-4-Voice - THG)和级联方案(ASR-LLM-TTS-THG)。用户可以自定义数字人的形象和音色,支持音色克隆,无需训练,首包延迟低至3秒。该项目利用了最新的人工智能技术,包括自动语音识别(ASR)、大型语言模型(
讯飞虚拟人:讯飞虚拟人利用最新的AI虚拟形象技术,结合语音识别、语义理解、语音合成、NLP、星火大模型等AI核心技术,提供虚拟人形象资产构建、AI驱动、多模态交互的多场景虚拟人产品服务。一站式虚拟人音视频内容生产,AIGC助力创作灵活高效;在虚拟AI演播室中输入文本或录音,一键完成音、视频作品的输出,3分钟内渲
VideoChat和讯飞虚拟人均是AI软件、AI工具中的一种,在功能设计、应用场景、用户体验上存在一些区别,以下是卓商AI整理出来的一些对比选项,仅供您参考。
官网地址
https://github.com/Henry-23/VideoChat
https://virtual-man.xfyun.cn/
功能简介
VideoChat是一个实时语音交互数字人项目,支持端到端语音方案(GLM-4-Voice - THG)和级联方案(ASR-LLM-TTS-THG)。用户可以自定义数字人的形象和音色,支持音色克隆,无需训练,首包延迟低至3秒。该项目利用了最新的人工智能技术,包括自动语音识别(ASR)、大型语言模型(LLM)、端到端多模态大型语言模型(MLLM)、文本到语音(TTS)和说话头生成(THG),为用户提供了一个高度定制化和低延迟的交互体验。
讯飞虚拟人利用最新的AI虚拟形象技术,结合语音识别、语义理解、语音合成、NLP、星火大模型等AI核心技术,提供虚拟人形象资产构建、AI驱动、多模态交互的多场景虚拟人产品服务。一站式虚拟人音视频内容生产,AIGC助力创作灵活高效;在虚拟AI演播室中输入文本或录音,一键完成音、视频作品的输出,3分钟内渲染出稿。
排名榜单 🔥
可平替产品
AI Tools List
AI Tools List是一个专注于AI工具的资源网站,它收集并分类了各种AI工具,包括写作、设计、视频编辑、音频编辑、客户支持等。用户可以通过这个平台快速找到适合自己需求的AI工具,提高工作效率。
BASE TTS
BASE TTS是亚马逊开发的大规模文本到语音合成模型,运用了10亿参数的自动回归转换器,可将文本转换成语音代码,再通过卷积解码器生成语音波形。该模型使用了超过10万小时的公共语音数据进行训练,实现了
TikTok Voice Generator
TikTok Voice Generator是一个基于最新TikTok文本到语音技术的工具,能够生成多种有趣且逼真的AI语音效果,如Jessie语音、C3PO语音、鬼脸杀手语音等。它支持多种语言,且用
Mikrotakt
Mikrotakt Vocal Remover & Instrumental AI Splitter是一款利用人工智能算法从歌曲或视频文件中提取人声、伴奏、吉他、钢琴、贝斯、鼓等不同乐器的音频分离工具

Vocapia
Vocapia Research开发的语音识别软件提供先进的语音处理技术,支持多语种识别,并能应用于广播监控、讲座和研讨会转录、视频字幕、电话会议转录和语音分析等领域。我们的产品具有大词汇量连续语音识
Emilia
Emilia是一个开源的多语种野外语音数据集,专为大规模语音生成研究设计。它包含超过101,000小时的六种语言高质量语音数据和相应的文本转录,覆盖了各种说话风格和内容类型,如脱口秀、访谈、辩论、体育
Whisper Memo Dictation
使用先进的人工智能技术,将语音备忘录转录为文字。该应用能够轻松处理大型音频录音并生成准确的转录。支持离线转录,所有数据在设备上进行处理。免费功能包括:轻松录制和转录音频文件、无需互联网进行转录、所有数

EchoMimicV2
EchoMimicV2是由支付宝蚂蚁集团终端技术部研发的半身人体动画技术,它通过参考图像、音频剪辑和一系列手势来生成高质量的动画视频,确保音频内容与半身动作的连贯性。这项技术简化了以往复杂的动画制作流
Gemini 1.5 Flash
Gemini 1.5 Flash是Google DeepMind团队推出的最新AI模型,它通过蒸馏过程从更大的1.5 Pro模型中提炼出核心知识和技能,以更小、更高效的模型形式提供服务。该模型在多模态
AudioSeal
AudioSeal 是一种用于AI生成语音音频的本地化水印技术,具有最先进的鲁棒性和极快的检测速度。它通过联合训练一个嵌入水印的生成器和一个检测器,即使在音频编辑的情况下,也能在较长的音频中检测到水印
Narrated Tours (On Demand Audio Guides)
Narrated Tours是一款让您在任何城市都能成为自己的导游的产品。通过选择不同的城市和景点,您可以自己策划和定制属于自己的音频漫游。它为您提供了个人导游的体验,让您在新的城市中轻松探索和了解当
CyberHost
CyberHost是一个端到端音频驱动的人体动画框架,通过区域码本注意力机制,实现了手部完整性、身份一致性和自然运动的生成。该模型利用双U-Net架构作为基础结构,并通过运动帧策略进行时间延续,为音频
ttsMP3.com
ttsMP3是一个免费的多语言文本转语音工具,支持28种以上的语言和口音。用户可以将文本转换为自然流利的语音,并可在线收听或下载为MP3文件。适用于电子学习、演示、YouTube视频以及提高网站的可访
VoiceZap
VoiceZap是一款创新的生产力工具,它允许用户通过语音指令来触发Zapier上的自动化流程。这一技术极大地简化了自动化任务的触发方式,无需手动操作,提高了工作效率。产品主要面向希望通过语音控制来优
Audio Muse
Audio Muse是一个提供一站式在线音频处理需求的平台,它拥有全面的音频工具集合,用户可以轻松使用。该产品以其易用性、多功能性和AI音乐创作功能而受到音乐爱好者和创作者的欢迎。它支持用户在线创建独
Read To Me
Read To Me是一个在线服务,它使用户能够将PDF文件转换成音频格式,从而在各种设备上收听,提高信息获取的便捷性和效率。这项技术的主要优点包括一键转换、随时随地的收听体验、提升生产力、简单透明的
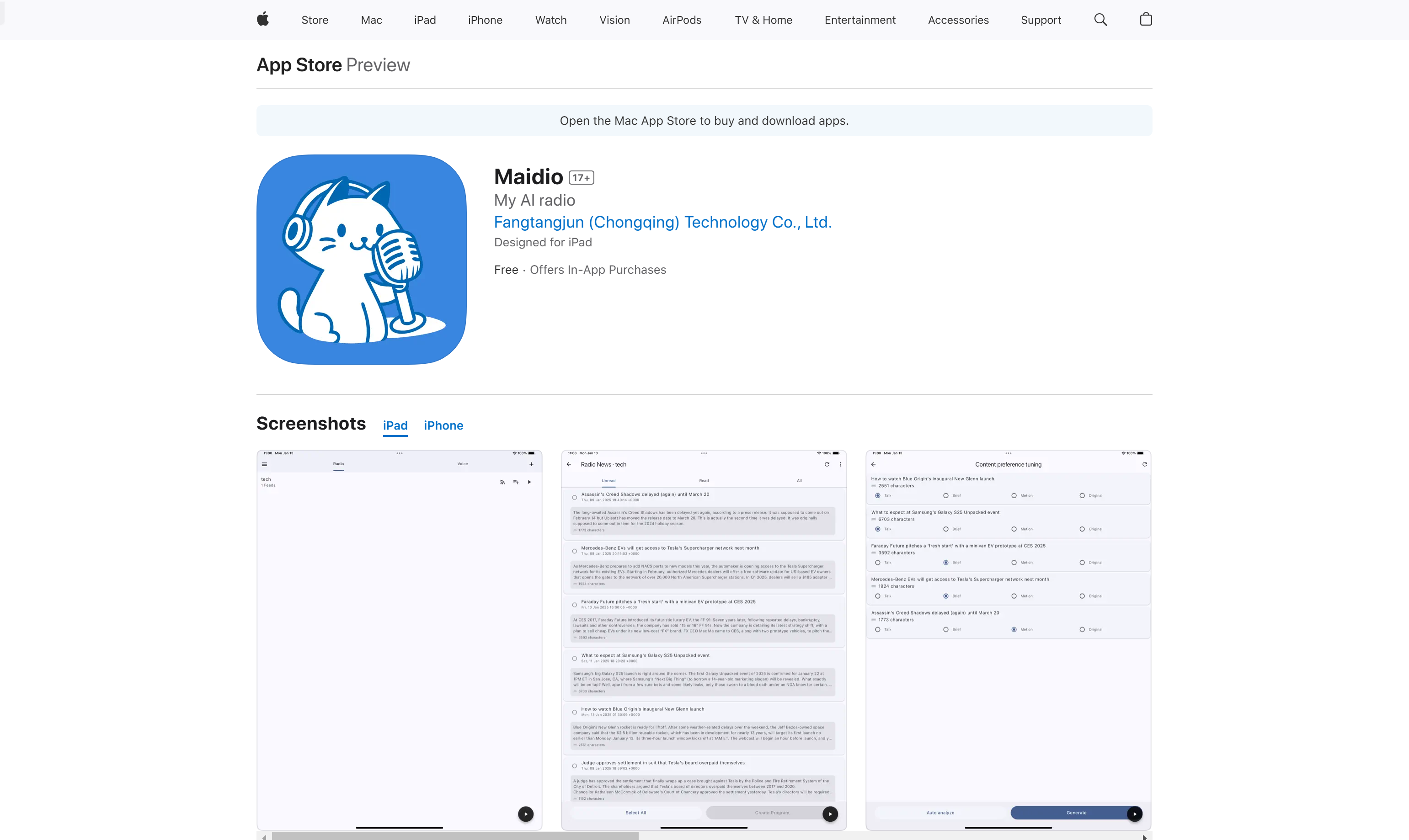
Maidio
Maidio 是一款创新的音频内容应用,通过 AI 技术将 RSS 新闻自动转换为生动的对话式播客。它利用先进的自然语言处理技术,将新闻内容以主持人与助手的对话形式呈现,使用户能够以更有趣的方式获取信

Loopy model
Loopy是一个端到端的音频驱动视频扩散模型,专门设计了跨剪辑和内部剪辑的时间模块以及音频到潜在表示模块,使模型能够利用数据中的长期运动信息来学习自然运动模式,并提高音频与肖像运动的相关性。这种方法消
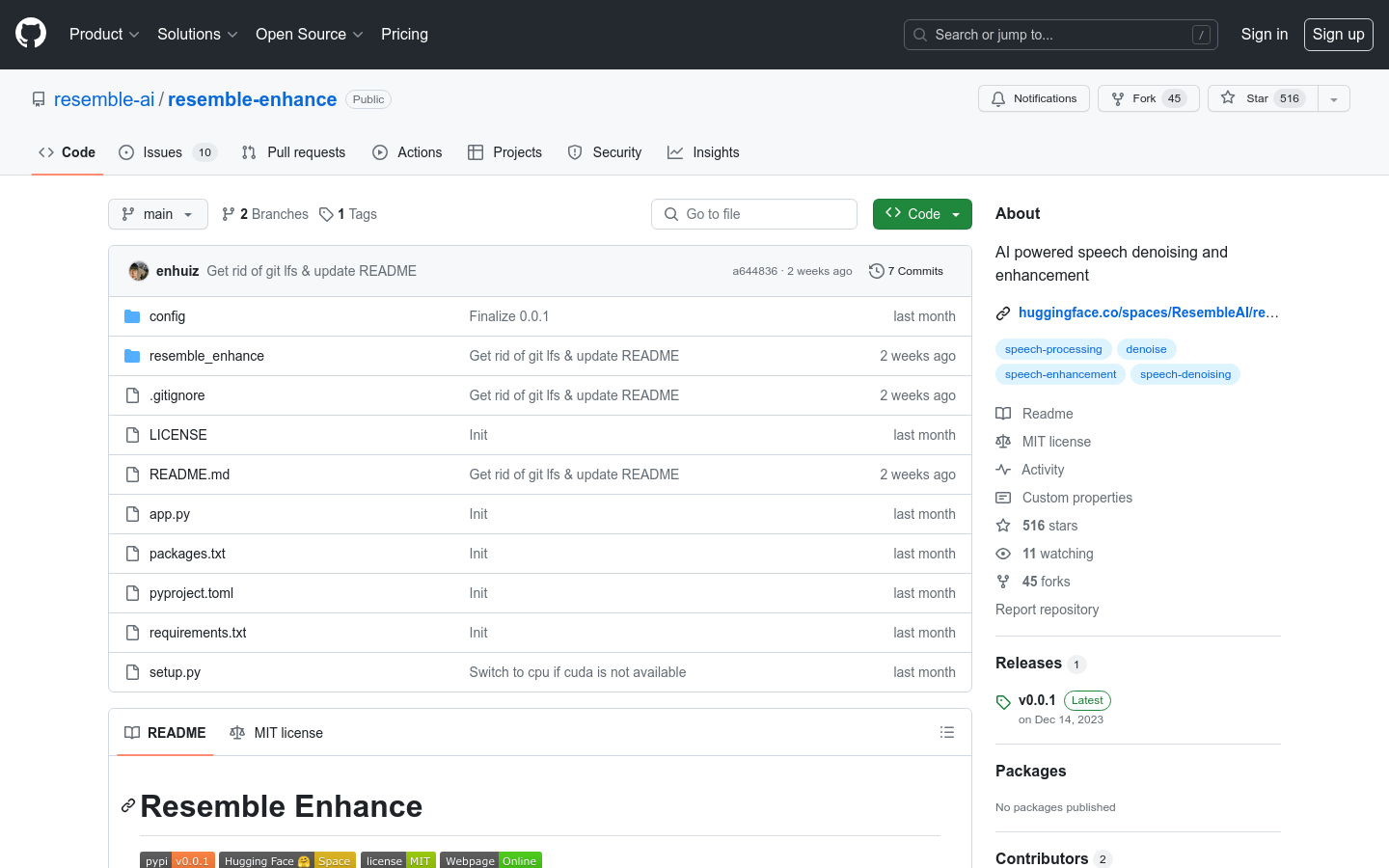
Resemble Enhance
resemble-enhance是一个支持语音降噪与增强的AI模型,可以高效去除背景噪声,还原语音细节,提升语音质量。该模型包含降噪模块和增强模块,通过深度学习算法实现语音信号与噪声分离,以及语音品质
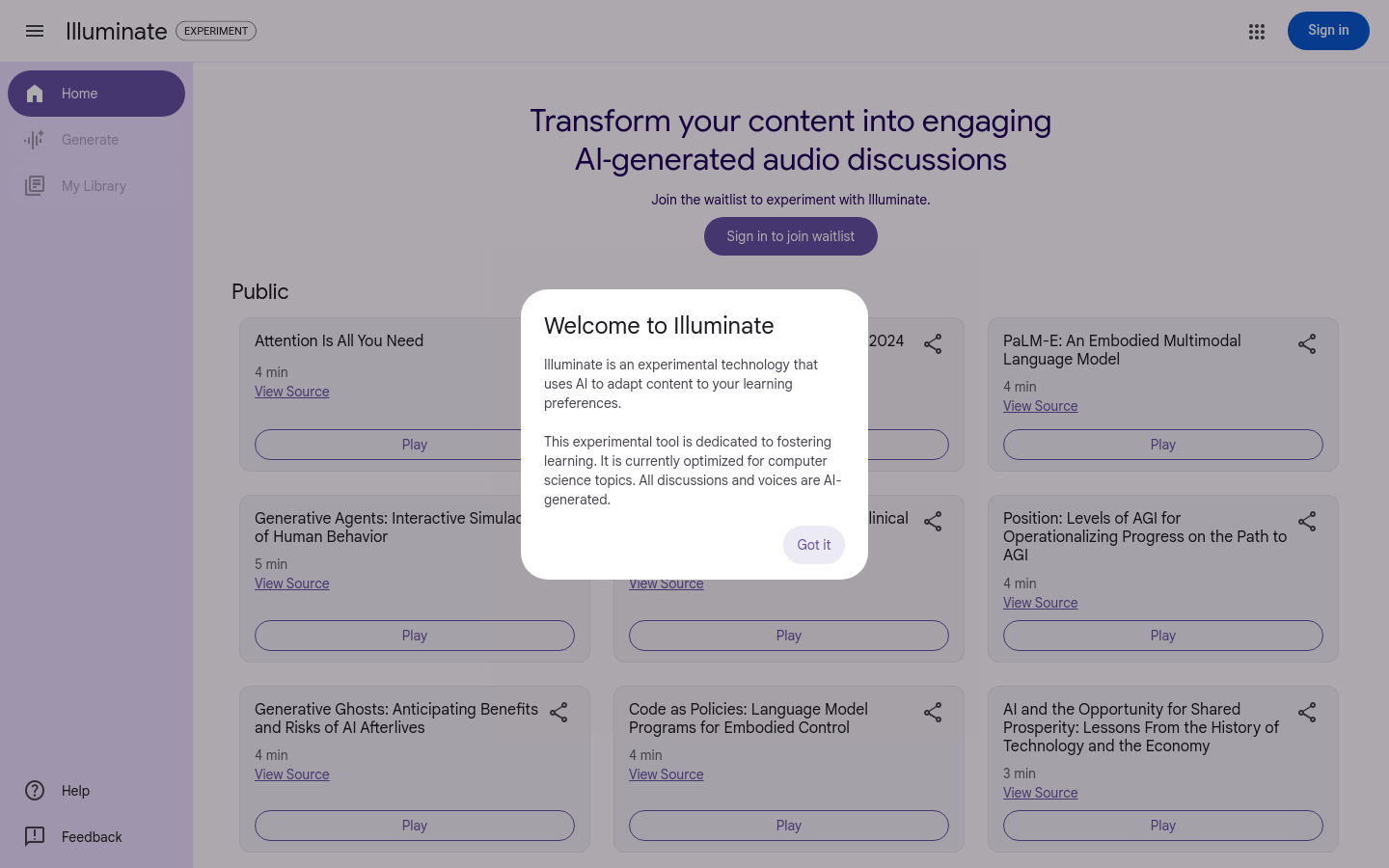
Google Illuminate
Illuminate是Google一个实验性技术,利用人工智能将选定的论文内容转化为两个AI生成的声音进行讨论的音频。这项技术特别适合计算机科学领域的学术论文,能够根据用户的学习偏好进行内容适应。它通
CogiX
cogiX是一款综合性的AI应用,为企业提供便捷的AI内容生成和高效的运营管理。通过cogiX,您可以轻松生成基于AI的内容,并在短时间内高效管理业务。无需多个工具,cogiX提供了一站式的解决方案,
QuickNoter
QuickNoter是一款基于人工智能技术的音频转文字工具。它可以将音频文件快速转换为文字笔记,提高工作效率和学习效果。QuickNoter具有智能识别和转写功能,支持多种常见音频格式,包括MP3、W

ElevenLabs Flash
Flash是ElevenLabs最新推出的文本转语音(Text-to-Speech, TTS)模型,它以75毫秒加上应用和网络延迟的速度生成语音,是低延迟、会话型语音代理的首选模型。Flash v2仅
Voicetapp
Voicetapp是一个强大的基于云端的人工智能软件,通过最新的语音识别技术,帮助您将任何语音、音频和视频自动转换为文字。具备高达99%的准确度。支持170种语言和方言。具备演讲者识别、实时转录、多种
AI爱好者的一站式人工智能AI工具箱,累计收录全球10,000⁺好用的AI工具软件和网站,方便您更便捷的探索前沿的AI技术。本站持续更新好的AI应用,力争做全球排名前三的AI网址导航网站,欢迎您成为我们的一员。
