首页 >Adobe Podcast和Ascenscia对比
Adobe Podcast和Ascenscia哪个好用,Adobe Podcast和Ascenscia详细对比
Adobe Podcast:Adobe Podcast是一款基于人工智能技术的音频录制和编辑工具。它提供清晰、高质量的音频录制和编辑功能,支持自动转录、剪辑和分享。无论您是专业的播客主持人还是想要创作自己的播客节目,Adobe Podcast都可以满足您的需求。它还提供多种音频效果和工具,帮助您创建独特而专业的音频内容。Ado
Ascenscia:Ascenscia是一个专门针对科学实验室设计的AI语音助手,通过与实验室软件和机器的集成,实现免提交互,加速数据收集,优化工作流程,减少错误,并加速研发周期。产品具备97%的准确率理解复杂科学术语,支持端到端加密确保数据安全,提供多语言服务,并可定制以适应不同实验室的独特需求。
Adobe Podcast和Ascenscia均是AI软件、AI工具中的一种,在功能设计、应用场景、用户体验上存在一些区别,以下是卓商AI整理出来的一些对比选项,仅供您参考。
官网地址
https://podcast.adobe.com
https://www.ascenscia.ai/
功能简介
Adobe Podcast是一款基于人工智能技术的音频录制和编辑工具。它提供清晰、高质量的音频录制和编辑功能,支持自动转录、剪辑和分享。无论您是专业的播客主持人还是想要创作自己的播客节目,Adobe Podcast都可以满足您的需求。它还提供多种音频效果和工具,帮助您创建独特而专业的音频内容。Adobe Podcast定价灵活,适用于个人和团队使用。
Ascenscia是一个专门针对科学实验室设计的AI语音助手,通过与实验室软件和机器的集成,实现免提交互,加速数据收集,优化工作流程,减少错误,并加速研发周期。产品具备97%的准确率理解复杂科学术语,支持端到端加密确保数据安全,提供多语言服务,并可定制以适应不同实验室的独特需求。
排名榜单 🔥
可平替产品
声音复刻
声音复刻是一套高效化的轻量级音色定制方案。用户在开放环境中录制秒级别录音即可极速拥有专属 AI 定制音色。核心产品优势包括超低成本、极速复刻、高度还原和技术领先。适用场景包括视频配音、语音助手、车载助
Universal-2
Universal-2是AssemblyAI推出的最新语音识别模型,它在准确度和精确度上超越了前一代Universal-1,能够更好地捕捉人类语言的复杂性,为用户提供无需二次检查的音频数据。这一技术的
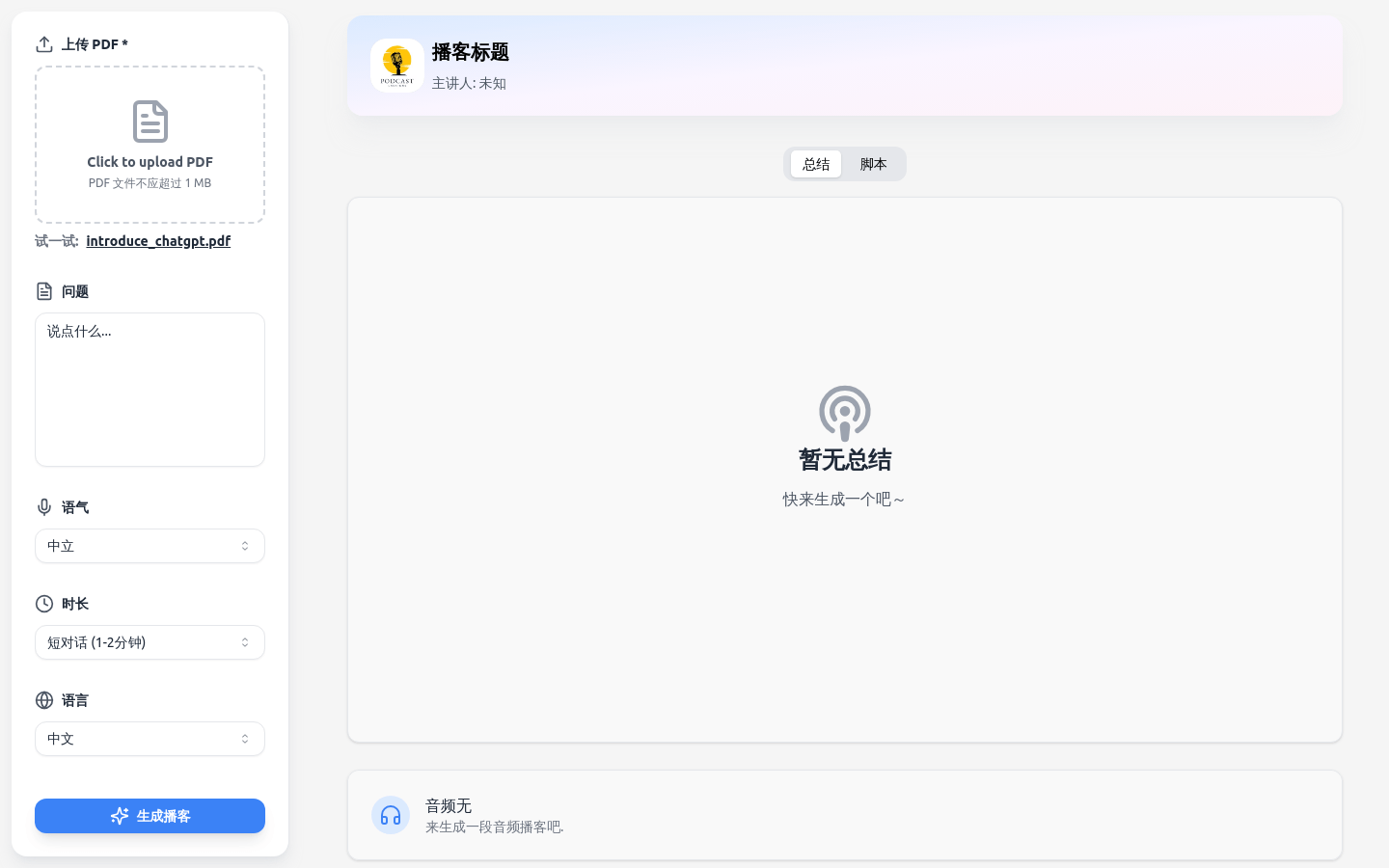
PodCastLM
PodCastLM是一个创新的智能播客生成平台,它利用先进的人工智能技术,让用户能够快速生成个性化的音频内容。用户只需上传PDF文件,选择问题、语气、时长和语言等参数,即可生成一段高质量的音频播客。该
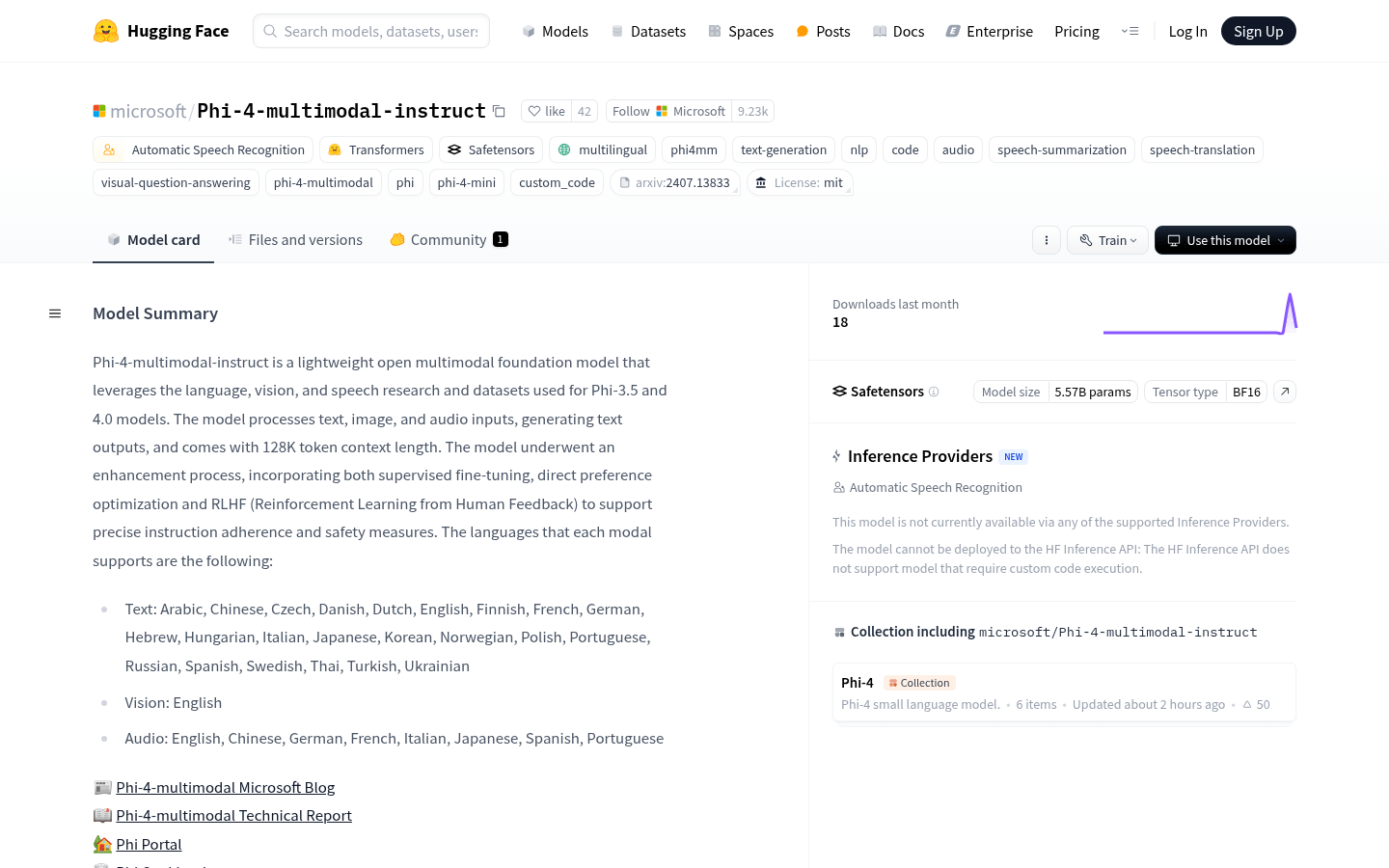
Phi-4-multimodal-instruct
Phi-4-multimodal-instruct 是微软开发的多模态基础模型,支持文本、图像和音频输入,生成文本输出。该模型基于Phi-3.5和Phi-4.0的研究和数据集构建,经过监督微调、直接偏
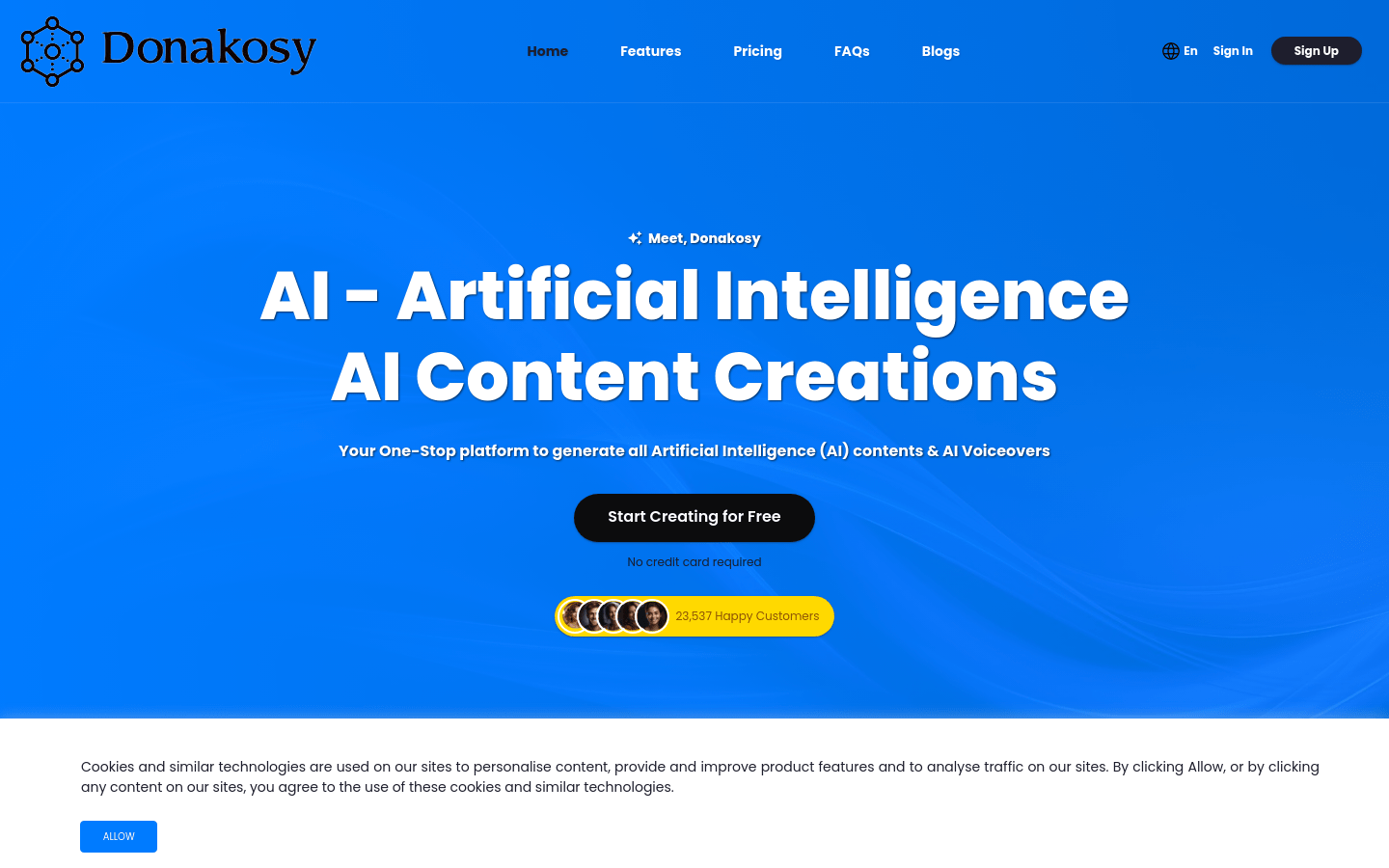
Donakosy
Donakosy是一款智能AI技术平台,为专业人士、内容创作者、图像设计、语音生成等提供全方位的AI服务。通过Chat GPT、AI和OpenAI技术,实现无缝的AI体验。
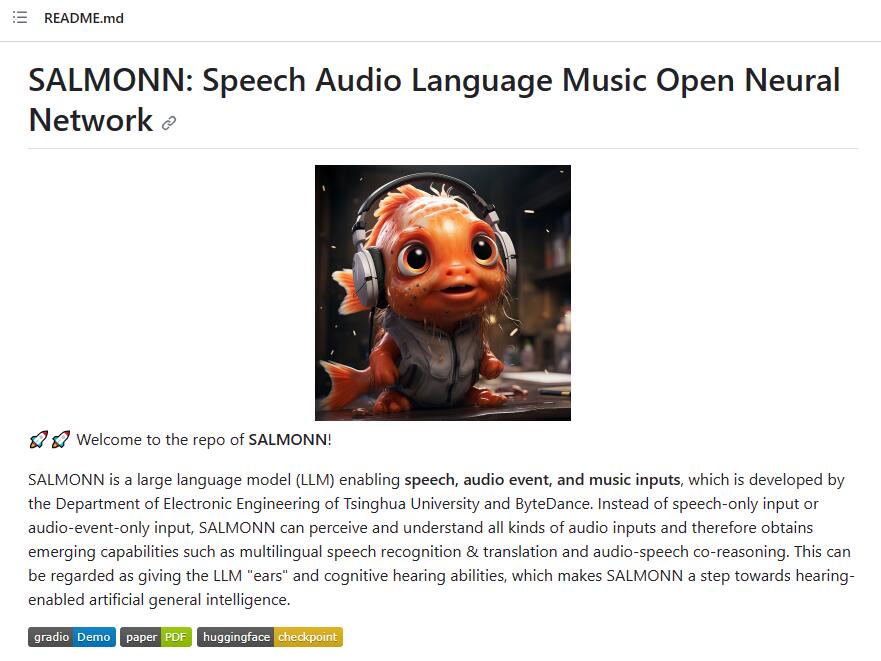
SALMONN
SALMONN是由清华大学电子工程系和字节跳动开发的大型语言模型(LLM),支持语音、音频事件和音乐输入。与仅支持语音或音频事件输入的模型不同,SALMONN可以感知和理解各种音频输入,从而获得多语言
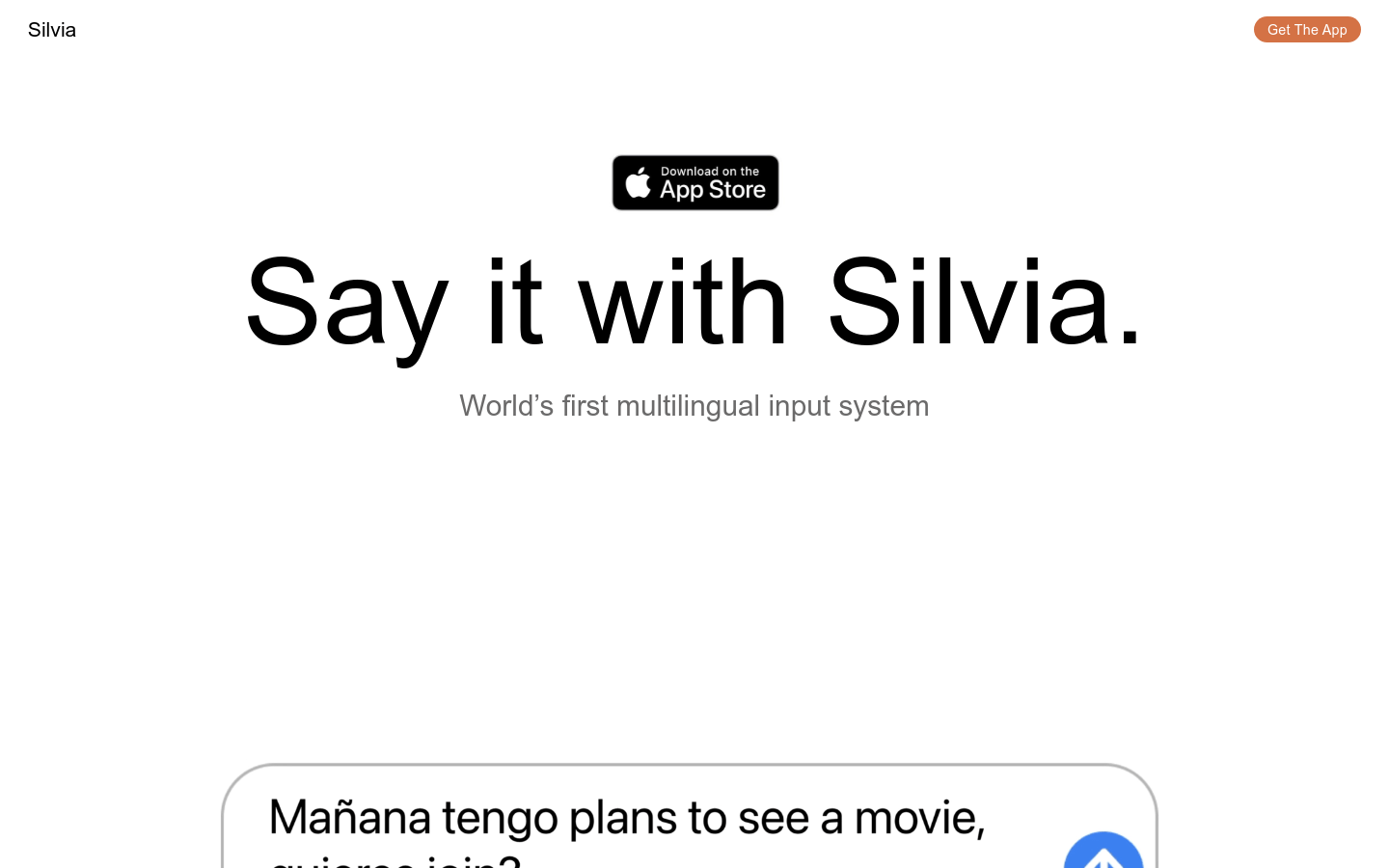
Silvia
Silvia是一款能够适应用户说话方式的语音输入系统,支持用户在不同语言之间自由切换,即使在句子中也能无缝切换。它支持英语和西班牙语,并且即将支持法语、罗马尼亚语、德语和荷兰语。Silvia作为苹果应
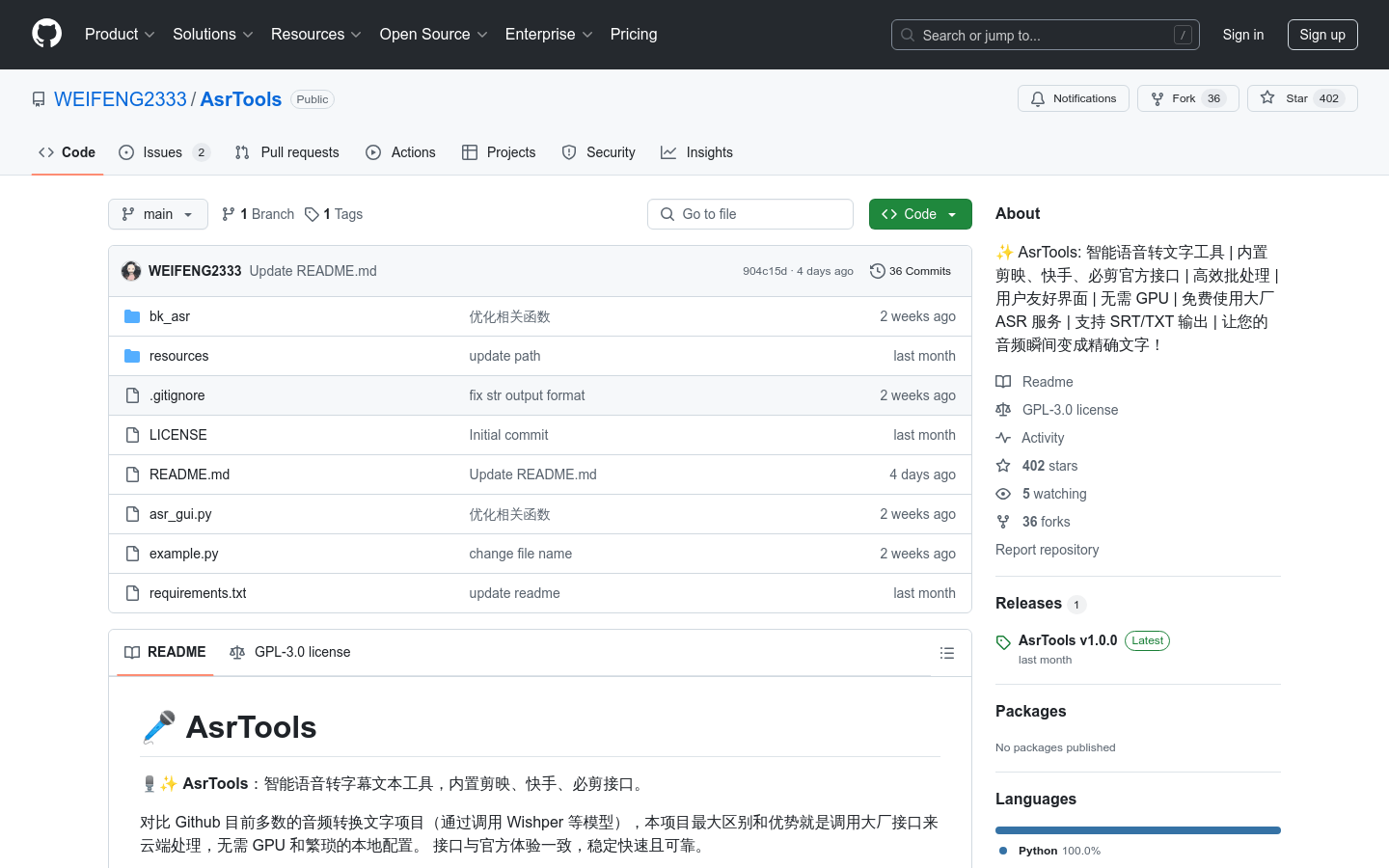
AsrTools
AsrTools是一款基于人工智能技术的语音转文字工具,它通过调用大厂的ASR服务接口,实现了无需GPU和复杂配置的高效语音识别功能。该工具支持批量处理和多线程并发,能够快速将音频文件转换成SRT或T

Tab
Tab是一款可佩戴的人工智能设备,集成语音助手、实时翻译、日程管理等功能,可成为用户的智能伴侣。它采用轻薄便携的设计,佩戴舒适。通过语音交互,可帮助用户提高工作效率,陪伴用户的日常生活。
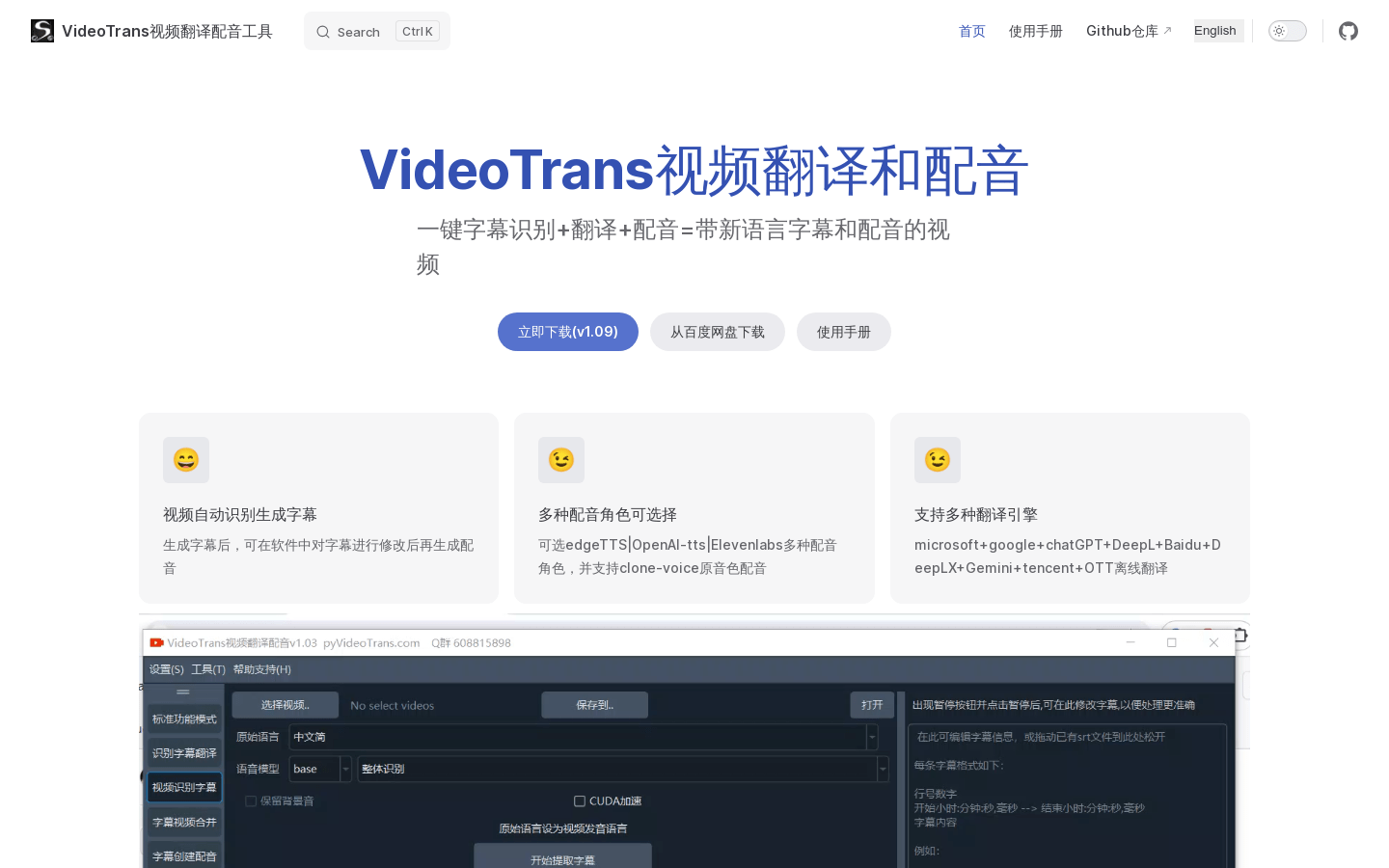
VideoTrans视频翻译配音工具
VideoTrans是一款免费开源的视频翻译配音工具。它可以一键识别视频字幕、翻译成其他语言、进行多种语音合成,最终输出带字幕和配音的目标语言视频。该软件使用简单,支持多种翻译和配音引擎,能大幅提高视
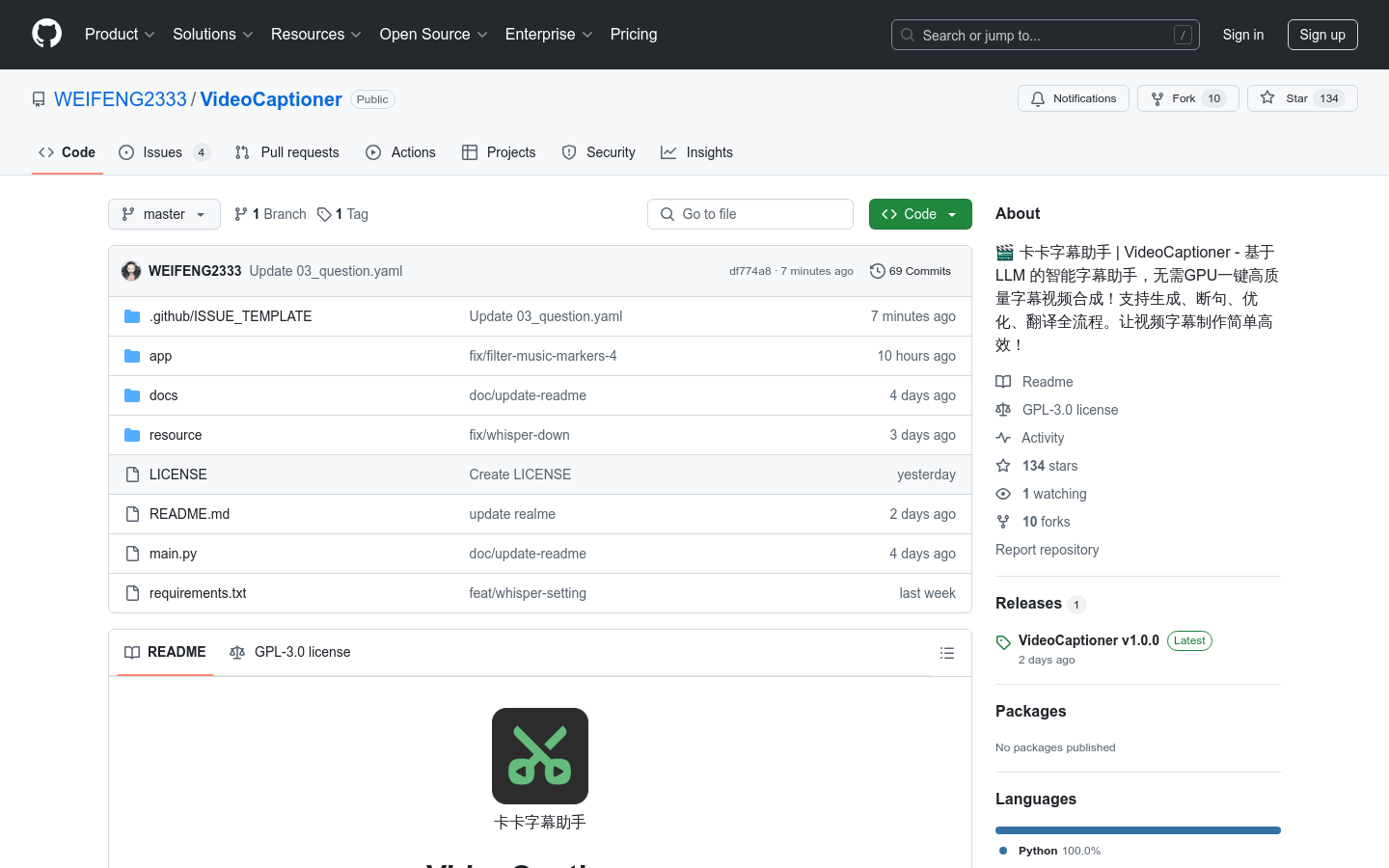
卡卡字幕助手
卡卡字幕助手(VideoCaptioner)是一款功能强大的视频字幕配制软件,利用大语言模型进行字幕智能断句、校正、优化、翻译,实现字幕视频全流程一键处理。产品无需高配置,操作简单,内置基础LLM模型
ttsMP3.com
ttsMP3是一个免费的多语言文本转语音工具,支持28种以上的语言和口音。用户可以将文本转换为自然流利的语音,并可在线收听或下载为MP3文件。适用于电子学习、演示、YouTube视频以及提高网站的可访
Riverside
Riverside是一款准确的AI转录工具,可以快速将音频和视频转录为文字。它支持100多种语言,提供完全免费的准确AI转录服务。除了转录功能,Riverside还提供了实时编辑、多人协作和高音质录音

ai text to reels maker
毫不费力地使用Makereels创建卷轴 - AI文本用于卷轴制造商。只需在任何主题上输入文本或内容,然后观察此高级AI会生成带有语音旁白的令人惊叹的卷轴。通过利用事实,统计,测验和见解等功能来提高
Acoust
Acoust是一款强大的文本转语音(TTS)服务,使用最新的AI技术生成自然的声音音频。它提供30多种语言的200多种语音,并允许用户以MP3、WAV和OGG格式下载音频文件。使用Acoust,您可以

Audiomatic
Audiomatic是一个利用人工智能技术为视频内容生成定制音乐的平台。它通过理解视频内容来创建与视频完美匹配的音乐,大大简化了音频后期制作流程,提高了内容发布的效率。产品的主要优点包括快速生成音乐、
Easy Voice Toolkit
Easy Voice Toolkit是一个基于开源语音项目的AI语音工具箱,提供包括语音模型训练在内的多种自动化音频工具。该工具箱能够无缝集成,形成完整的工作流程,用户可以根据需要选择性使用这些工具,
TTSynth.com
TTSynth.com是一个免费的在线文本转语音(TTS)生成器,它使用先进的AI技术将书面文本转换为自然发音的语音。该服务支持多种语言和口音,适用于全球用户。它提供了高质量的音频输出,并且用户可以轻
Hurd.ai Beta
Hurd AI是一款能够捕捉每个讲座、会议和对话的每个字的AI助手。使用Hurd AI,您可以专注于倾听,而不必担心记笔记或错过重要的内容。它支持自动转录、组织和总结会议和对话,并且可以将音频文件转换
Real-time Voice AI Agent
Real-time Voice AI Agent是一个高度灵活的实时语音交互模型,它能够在大约500毫秒内通过语音回答任何查询。该模型支持用户选择任何大型语言模型、文本到语音(TTS)模型和语音到文本
Speech to Note
Speech to Note是一个AI驱动的语音识别工具,能够即时将口语转换为文本。它使用先进的语音转文本技术,将您的语音转换成可以编辑或分享的简洁摘要。该产品由GPT-4技术支持,旨在提升生产力并释
Narrated Tours (On Demand Audio Guides)
Narrated Tours是一款让您在任何城市都能成为自己的导游的产品。通过选择不同的城市和景点,您可以自己策划和定制属于自己的音频漫游。它为您提供了个人导游的体验,让您在新的城市中轻松探索和了解当
Trivoh
Trivoh是一个基于人工智能驱动的视频和音频通信平台,通过自动化提升用户参与度,为您的团队提供全面的协作和通信解决方案,提高整体生产力和效率。Trivoh提供虚拟会议、聊天系统和易于插件等功能,支持
Universal-2
Universal-2是AssemblyAI推出的最新语音识别模型,它在准确度和精确度上超越了前一代Universal-1,能够更好地捕捉人类语言的复杂性,为用户提供无需二次检查的音频数据。这一技术的
AI爱好者的一站式人工智能AI工具箱,累计收录全球10,000⁺好用的AI工具软件和网站,方便您更便捷的探索前沿的AI技术。本站持续更新好的AI应用,力争做全球排名前三的AI网址导航网站,欢迎您成为我们的一员。
