首页 >Adobe Podcast和Ongkanon对比
Adobe Podcast和Ongkanon哪个好用,Adobe Podcast和Ongkanon详细对比
Adobe Podcast:Adobe Podcast是一款基于人工智能技术的音频录制和编辑工具。它提供清晰、高质量的音频录制和编辑功能,支持自动转录、剪辑和分享。无论您是专业的播客主持人还是想要创作自己的播客节目,Adobe Podcast都可以满足您的需求。它还提供多种音频效果和工具,帮助您创建独特而专业的音频内容。Ado
Ongkanon:Ongkanon是一款智能对话AI助手,提供有意义且上下文相关的对话体验。它能够自然地与您交谈,就像与亲密的朋友聊天一样。Ongkanon会根据您的偏好进行个性化定制,还能记住以前对话的上下文,以便进行更连贯、有意义的交互。
Adobe Podcast和Ongkanon均是AI软件、AI工具中的一种,在功能设计、应用场景、用户体验上存在一些区别,以下是卓商AI整理出来的一些对比选项,仅供您参考。
官网地址
https://podcast.adobe.com
https://ongkanon.com
功能简介
Adobe Podcast是一款基于人工智能技术的音频录制和编辑工具。它提供清晰、高质量的音频录制和编辑功能,支持自动转录、剪辑和分享。无论您是专业的播客主持人还是想要创作自己的播客节目,Adobe Podcast都可以满足您的需求。它还提供多种音频效果和工具,帮助您创建独特而专业的音频内容。Adobe Podcast定价灵活,适用于个人和团队使用。
Ongkanon是一款智能对话AI助手,提供有意义且上下文相关的对话体验。它能够自然地与您交谈,就像与亲密的朋友聊天一样。Ongkanon会根据您的偏好进行个性化定制,还能记住以前对话的上下文,以便进行更连贯、有意义的交互。
排名榜单 🔥
可平替产品
whisper-ner-v1
Whisper-NER是一个创新的模型,它允许同时进行语音转录和实体识别。该模型支持开放类型的命名实体识别(NER),能够识别多样化和不断演变的实体。Whisper-NER旨在作为自动语音识别(ASR
Meco
Meco是一个新闻通讯聚合器,旨在帮助用户将新闻通讯从电子邮件收件箱中移出,以减少干扰并提高阅读效率。它通过提供智能过滤器、分组、AI音频摘要、个性化推荐等功能,使用户能够更有效地管理和阅读新闻通讯。
麦耳会记
麦耳会记是一款集实时语音转写、实时翻译和 AI 辅助写作功能为一体的 AI 办公助手。它可以用于办公会议、学生网课、客户访谈录音等场景。软件支持边录音、边转写,录音结束后,音频、文本实时同步至 PC
vta-ldm
vta-ldm是一个专注于视频到音频生成的深度学习模型,能够根据视频内容生成语义和时间上与视频输入对齐的音频内容。它代表了视频生成领域的一个新突破,特别是在文本到视频生成技术取得显著进展之后。该模型由
MiniCPM-o-2_6
MiniCPM-o 2.6是MiniCPM-o系列中最新且功能最强大的模型。该模型基于SigLip-400M、Whisper-medium-300M、ChatTTS-200M和Qwen2.5-7B构建

Podcast GPT by Wondercraft
ChatGPT Podcast Generator是一个利用人工智能技术,帮助用户将文本内容快速转换成播客节目的平台。它通过AI声音、音频编辑器、协作功能等,使得内容创作者、市场营销人员和有故事要分享
Memo.ac
Memo是一个桌面应用程序,可以方便地将YouTube视频、播客和本地媒体文件转录为文本。它支持多种语言的转录和翻译,可以在转录的同时实时生成字幕和浮动注释,并可以轻松导出为SRT字幕、Markdow
网易见外
网易见外是一款提供一站式双语字幕服务的产品。它通过领先的机器引擎和高效交付成果,实现央媒级服务质量保证。用户可以快速获取中英文语音高速转写、无干扰准确率达95%的音频转写翻译,实时双语字幕同步投屏、会
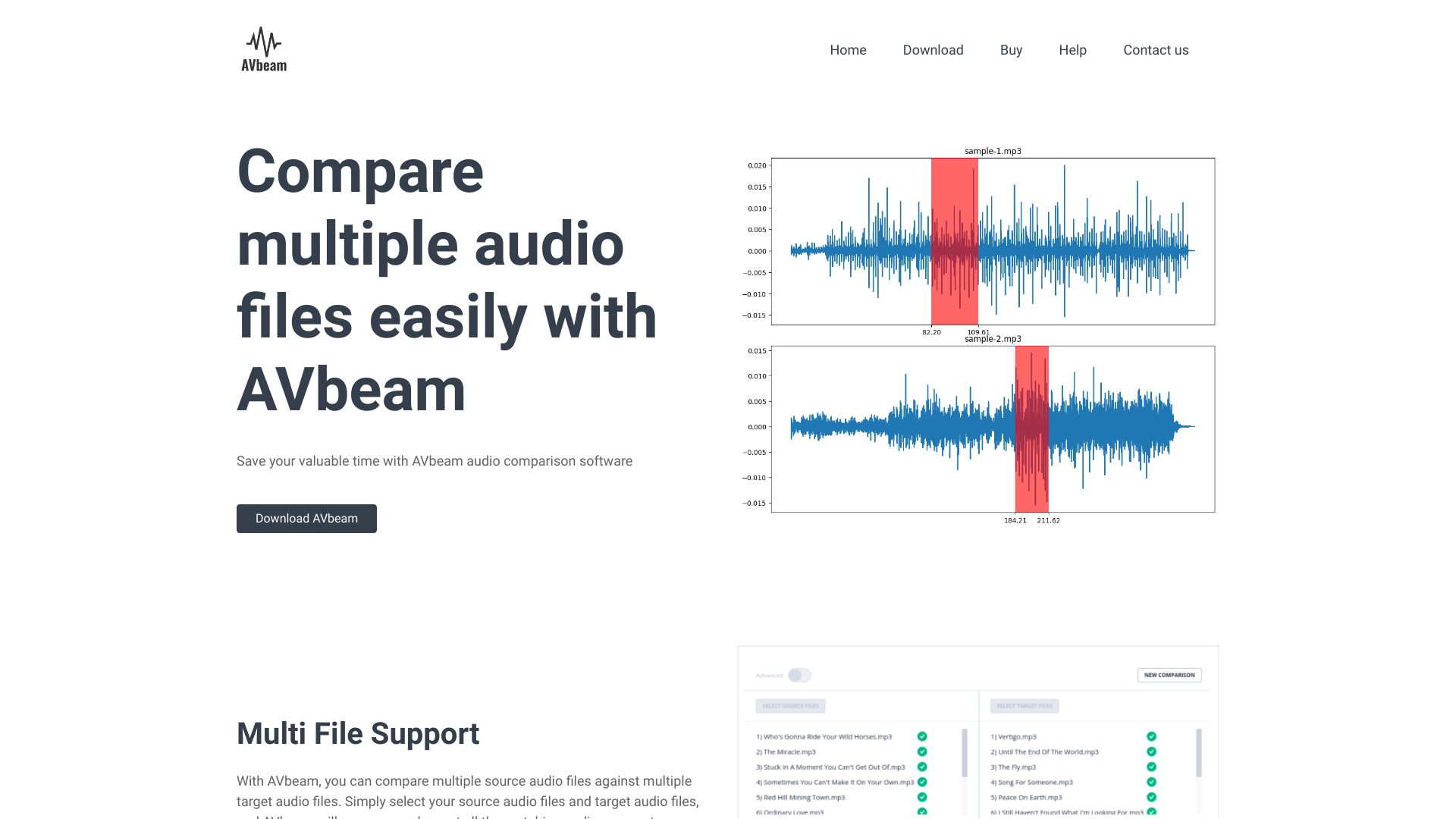
AVbeam
AVbeam是一款音频比对软件,可用于比较多个音频文件,识别相匹配的音频片段。它支持多种音频格式,能够识别部分匹配的音频片段,并展示匹配的时间偏移和相似度等信息。AVbeam采用强大的音频比对算法,能
UniFab
UniFab 是一款强大的 AI 助力的视频音频增强工具。它利用先进的超分辨率技术,能够将视频分辨率提升至 8K/16K,同时将 SDR 转换为 HDR,为用户提供影院级的视觉体验。其 AI 驱动的深
Udio v1.5
Udio v1.5是一个音乐创作平台的高级版本,它在v1的基础上进行了多项改进,包括提高音质、提供音调控制、改善全球语言支持等。它生成48kHz立体声轨道,提供更清晰的音质和更好的乐器分离度。此外,U
Riverside
Riverside是一款准确的AI转录工具,可以快速将音频和视频转录为文字。它支持100多种语言,提供完全免费的准确AI转录服务。除了转录功能,Riverside还提供了实时编辑、多人协作和高音质录音
pdf-to-podcast
pdf-to-podcast是一个基于人工智能技术的生产力工具,能够将PDF文档转换成播客节目。它使用OpenAI的文本到语音模型和Google Gemini技术,将PDF内容处理成适合音频播客的自然

Music ControlNet
Music ControlNet 是一种基于扩散的音乐生成模型,可以提供多个精确的、时变的音乐控制。它可以根据旋律、动态和节奏控制生成音频,并且可以部分指定时间上的控制。与其他音乐生成模型相比,Mus
Cartesia
Cartesia提供实时多模态智能技术,旨在为各种设备提供服务。产品包括Sonic和On-Device两大核心功能。Sonic是快速、超逼真的生成性语音API,由下一代状态空间模型驱动。On-Devi
Soundify
Soundify是一个基于AI的音频编辑工具,提供音频修复、音质增强、去噪等功能,能够帮助用户简单快速地优化和提升音频质量。该产品采用独特的深度学习算法,能够准确识别和消除杂音,平滑音频细节,使声音更
Llasa
Llasa是一个基于Llama框架的文本到语音(TTS)基础模型,专为大规模语音合成任务设计。该模型利用16万小时的标记化语音数据进行训练,具备高效的语言生成能力和多语言支持。其主要优点包括强大的语音
Free Subtitles AI
FreeSubtitles.AI是一个免费的在线工具,可以自动将音频和视频转录为文本。它可以帮助用户将会议录音、访谈、演讲等各种类型的音频和视频文件快速转换成可编辑和搜索的文本。该工具提供免费的自动翻
心辰Lingo语音大模型
心辰Lingo语音大模型是一款先进的人工智能语音模型,专注于提供高效、准确的语音识别和处理服务。它能够理解并处理自然语言,使得人机交互更加流畅和自然。该模型背后依托西湖心辰强大的AI技术,致力于在各种
OpenAI TTS
OpenAI TTS提供文本到语音的API,基于他们的TTS模型。它带有6种内置语音,可用于朗读博客文章、在多种语言中生成口语音频以及使用流式传输实时音频输出。用户可以通过控制模型名称、文本和语音选择

Spark-TTS
Spark-TTS 是一种基于大语言模型的高效文本到语音合成模型,具有单流解耦语音令牌的特性。它利用大语言模型的强大能力,直接从代码预测的音频进行重建,省略了额外的声学特征生成模型,从而提高了效率并降

Cartesia Voice Changer
Voice Changer是Cartesia推出的一款音频变声模型,它能够在转换音频声音的同时,保持原始音频的表达方式和情感。这项技术基于Cartesia在状态空间模型(SSM)架构上的开创性工作,能
Alexa+
Alexa+ 是亚马逊在 2025 年推出的下一代智能语音助手,基于生成式 AI 技术构建。它不仅能够进行自然流畅的对话,还能连接数千种服务和设备,帮助用户完成各种任务。其核心优势在于强大的语言理解能

团子AI
团子AI是一款在线的人工智能工具箱,提供伴奏人声提取、任意乐器分离、无损升降调等实用功能。基于云计算,使用简单,无需下载安装就可以随时随地使用。通过深度学习和大数据训练,效果优异,大幅提高工作效率。定
AI爱好者的一站式人工智能AI工具箱,累计收录全球10,000⁺好用的AI工具软件和网站,方便您更便捷的探索前沿的AI技术。本站持续更新好的AI应用,力争做全球排名前三的AI网址导航网站,欢迎您成为我们的一员。
