首页 >VideoChat和PodLM对比
VideoChat和PodLM哪个好用,VideoChat和PodLM详细对比
VideoChat:VideoChat是一个实时语音交互数字人项目,支持端到端语音方案(GLM-4-Voice - THG)和级联方案(ASR-LLM-TTS-THG)。用户可以自定义数字人的形象和音色,支持音色克隆,无需训练,首包延迟低至3秒。该项目利用了最新的人工智能技术,包括自动语音识别(ASR)、大型语言模型(
PodLM:PodLM是一个AI播客生成器,旨在帮助企业和营销人员轻松创建高质量的播客,以推动结果。它利用先进的AI技术,从URL和文本生成高质量播客,提供多样化的内容来源,并且是一个NotebookLM的替代品,专门用于AI播客创作。
VideoChat和PodLM均是AI软件、AI工具中的一种,在功能设计、应用场景、用户体验上存在一些区别,以下是卓商AI整理出来的一些对比选项,仅供您参考。
官网地址
https://github.com/Henry-23/VideoChat
功能简介
VideoChat是一个实时语音交互数字人项目,支持端到端语音方案(GLM-4-Voice - THG)和级联方案(ASR-LLM-TTS-THG)。用户可以自定义数字人的形象和音色,支持音色克隆,无需训练,首包延迟低至3秒。该项目利用了最新的人工智能技术,包括自动语音识别(ASR)、大型语言模型(LLM)、端到端多模态大型语言模型(MLLM)、文本到语音(TTS)和说话头生成(THG),为用户提供了一个高度定制化和低延迟的交互体验。
PodLM是一个AI播客生成器,旨在帮助企业和营销人员轻松创建高质量的播客,以推动结果。它利用先进的AI技术,从URL和文本生成高质量播客,提供多样化的内容来源,并且是一个NotebookLM的替代品,专门用于AI播客创作。
排名榜单 🔥
可平替产品
Stability AI
Stability AI是一个专注于生成式人工智能技术的公司,提供多种AI模型,包括文本到图像、视频、音频、3D和语言模型。这些模型能够处理复杂提示,生成逼真的图像和视频,以及高质量的音乐和音效。公司
OpenVoice
OpenVoice是一个开源的语音克隆技术,可以准确地克隆参考音色,生成多种语言和口音的语音。它可以灵活地控制语音风格,如情感、口音等参数,以及节奏、停顿和语调等。它实现了零样本跨语言语音克隆,即生成
LLaSA_training
LLaSA_training 是一个基于 LLaMA 的语音合成训练项目,旨在通过优化训练时间和推理时间的计算资源,提升语音合成模型的效率和性能。该项目利用开源数据集和内部数据集进行训练,支持多种配置
Luvvoice
Luvvoice是一个免费的文字转语音工具,提供200多种声音选择,可根据用户需求将文本转化为语音。Luvvoice具有易用性、多语言支持和高质量的声音合成等优势。Luvvoice的定价非常实惠,让用
Dictate Buddy
Dictate Buddy是一款利用人工智能技术将语音转换为文字的应用程序。它支持99种语言,并且能够自动检测语言。该应用使用OpenAI Whisper模型,能够准确转录并正确使用标点符号,将口语转

Tab
Tab是一款可佩戴的人工智能设备,集成语音助手、实时翻译、日程管理等功能,可成为用户的智能伴侣。它采用轻薄便携的设计,佩戴舒适。通过语音交互,可帮助用户提高工作效率,陪伴用户的日常生活。

SyncAnimation
SyncAnimation 是一种创新的音频驱动技术,能够实时生成高度逼真的说话头像和上半身动作。它通过结合音频与姿态、表情的同步技术,解决了传统方法在实时性和细节表现上的不足。该技术主要面向需要高质
AI ContentCraft
AI ContentCraft 是一个强大的内容创作平台,旨在帮助创作者快速生成故事、播客脚本和多媒体内容。它通过集成文本生成、语音合成和图像生成技术,为创作者提供一站式的解决方案。该工具支持中英文内

AIssistify
AIssistify是一款AI助手,最大限度地提高销售、营销和RevOps的效率。它帮助自动化销售、营销和其他运营流程,简化工作流程。
Zonos
Zonos 是一个先进的文本到语音模型,支持多种语言,能够根据文本提示和说话者嵌入或音频前缀生成自然语音。它还支持语音克隆,只需几秒钟的参考音频即可准确复制说话者的声音。该模型具有高质量的语音输出(4
Media.io
Media.io 是一个在线平台,提供一系列便携式的 AI 工具,用于视频、音频和图像编辑。它提供了视频卡通化、AI 头像生成器、图像增强器和水印去除器等功能。Media.io 还提供了其他视频和音频
ChatTTS-ui
ChatTTS-ui是一个为ChatTTS项目提供的web界面和API接口,允许用户通过网页进行语音合成操作,并通过API接口进行远程调用。它支持多种音色选择,用户可以自定义语音合成的参数,如笑声、停
EVI 2
EVI 2是Hume AI推出的新型基础语音对语音模型,能够以接近人类的自然方式与用户进行流畅对话。它具备快速响应、理解用户语调、生成不同语调、以及执行特定请求的能力。EVI 2通过特殊训练增强了情感
AudioCraft
AudioCraft 是一个用于音频处理和生成的 PyTorch 库。它包含了两个最先进的人工智能生成模型:AudioGen 和 MusicGen,可以生成高质量的音频。AudioCraft 还提供了
speech-to-speech
speech-to-speech 是一个开源的模块化GPT4-o项目,通过语音活动检测、语音转文本、语言模型和文本转语音等连续部分实现语音到语音的转换。它利用了Transformers库和Huggin
whisper-ner-v1
Whisper-NER是一个创新的模型,它允许同时进行语音转录和实体识别。该模型支持开放类型的命名实体识别(NER),能够识别多样化和不断演变的实体。Whisper-NER旨在作为自动语音识别(ASR

Hero App
Hero是一款集成了日历、提醒、记事、购物清单、天气和GPT聊天功能的APP,旨在帮助用户更高效地管理日常生活和提高生产力。它通过一个简洁的界面,将多个日常任务整合在一起,让用户可以快速查看和管理自己
Emilia
Emilia是一个开源的多语种野外语音数据集,专为大规模语音生成研究设计。它包含超过101,000小时的六种语言高质量语音数据和相应的文本转录,覆盖了各种说话风格和内容类型,如脱口秀、访谈、辩论、体育
Repurpose.io
Repurpose.io是一个自动化内容再利用和分发平台,帮助视频和音频创作者自动将内容发布到多个平台。我们的目标是让你更轻松地扩大受众并节省时间。使用Repurpose.io,你可以一次性创建内容,
Adobe Enhance Speech
Enhance Speech from Adobe是一款免费的AI音频过滤器,可以将口语音频处理得像在声音隔音工作室中录制的一样。它可以自动清除背景噪音,调整音量平衡,提升音频质量。用户可以将录音文件
llm-podcast-engine
llm-podcast-engine是一个利用人工智能技术自动从网络资源创建引人入胜音频内容的智能播客生成器。该系统通过爬取新闻内容、使用Groq的语言模型生成自然叙述,并借助ElevenLabs的声
Bark
Bark是由Suno开发的基于Transformer的文本到音频模型,能够生成逼真的多语言语音以及其他类型的音频,如音乐、背景噪声和简单音效。它还支持生成非语言交流,例如笑声、叹息和哭泣声。Bark支

dubecos
dubecos是一种采用先进的AI语音配音技术的在线平台,通过突破语言障碍,将您的视频推广至全球观众。我们平台完美结合AI和语音配音技术,为您提供完美的配音视频。无论是选择目标语言还是原始语言,dub
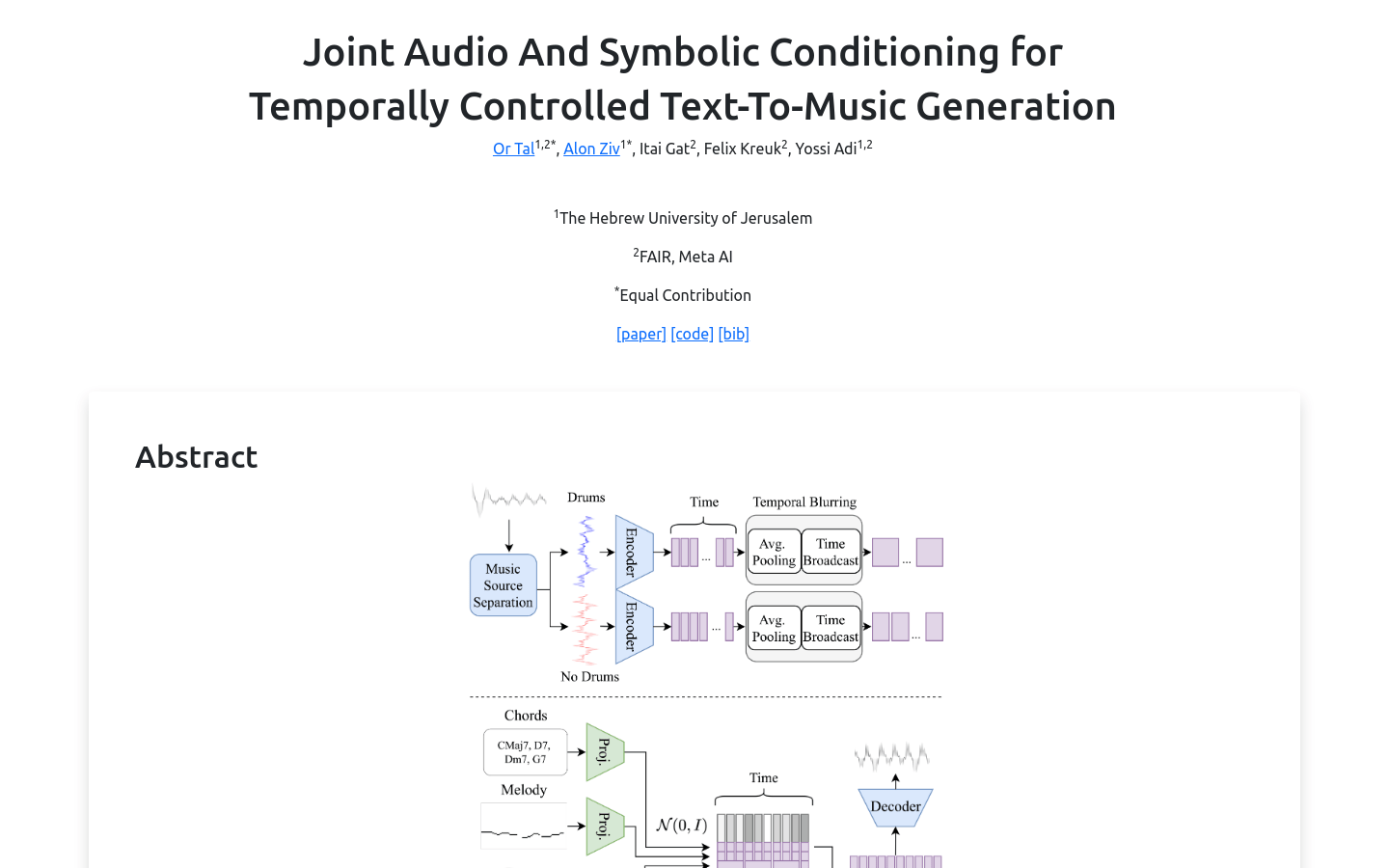
JASCO
JASCO是一个结合了符号和基于音频的条件的文本到音乐生成模型,它能够根据全局文本描述和细粒度的局部控制生成高质量的音乐样本。JASCO基于流匹配建模范式和一种新颖的条件方法,允许音乐生成同时受到局部
AI爱好者的一站式人工智能AI工具箱,累计收录全球10,000⁺好用的AI工具软件和网站,方便您更便捷的探索前沿的AI技术。本站持续更新好的AI应用,力争做全球排名前三的AI网址导航网站,欢迎您成为我们的一员。
