首页 >AssemblyAI和vta-ldm对比
AssemblyAI和vta-ldm哪个好用,AssemblyAI和vta-ldm详细对比
AssemblyAI:AssemblyAI是构建音频AI的最快捷途径。通过简单的API,获得生产就绪的AI模型,实现语音转录和理解。
vta-ldm:vta-ldm是一个专注于视频到音频生成的深度学习模型,能够根据视频内容生成语义和时间上与视频输入对齐的音频内容。它代表了视频生成领域的一个新突破,特别是在文本到视频生成技术取得显著进展之后。该模型由腾讯AI实验室的Manjie Xu等人开发,具有生成与视频内容高度一致的音频的能力,对于视频制作、音
AssemblyAI和vta-ldm均是AI软件、AI工具中的一种,在功能设计、应用场景、用户体验上存在一些区别,以下是卓商AI整理出来的一些对比选项,仅供您参考。
官网地址
https://www.assemblyai.com
https://github.com/ariesssxu/vta-ldm
功能简介
AssemblyAI是构建音频AI的最快捷途径。通过简单的API,获得生产就绪的AI模型,实现语音转录和理解。
vta-ldm是一个专注于视频到音频生成的深度学习模型,能够根据视频内容生成语义和时间上与视频输入对齐的音频内容。它代表了视频生成领域的一个新突破,特别是在文本到视频生成技术取得显著进展之后。该模型由腾讯AI实验室的Manjie Xu等人开发,具有生成与视频内容高度一致的音频的能力,对于视频制作、音频后期处理等领域具有重要的应用价值。
排名榜单 🔥
可平替产品
MasteredNow
Magnetic Mastering是一款专为现代音乐人设计的私人母带工具包。它可以在几分钟内使你的音乐达到分发标准,并自动优化在不同平台上的播放效果。通过独特的智能EQ功能,你可以获得个性化的音频调
SALMONN
SALMONN是由清华大学电子工程系和字节跳动开发的大型语言模型(LLM),支持语音、音频事件和音乐输入。与仅支持语音或音频事件输入的模型不同,SALMONN可以感知和理解各种音频输入,从而获得多语言
Tenyx
Tenyx是一个AI驱动的语音代理平台,专注于提供企业级的交互式语音响应(IVR)解决方案。它通过三个技术支柱:会话AI语音代理、会话语音平台和核心AI,来实现高效、定制化的语音服务。Tenyx的核心
Ewolve AI
EwolveAI是一个集成了文本生成、语音识别、图像生成、聊天机器人等多种功能的全能AI工具。它提供高质量的AI生成内容,帮助用户更快地开发项目。通过智能的仪表盘,用户可以访问有价值的用户洞察、分析和
WhisperFusion
WhisperFusion是一款基于WhisperLive和WhisperSpeech功能的产品,通过在实时语音转文字流程中集成Mistral大型语言模型(LLM)来实现与AI的无缝对话。Whispe
audio2photoreal
audio2photoreal是一个从音频生成照片级逼真avatar的开源项目。它包含了一个pytorch实现,可以从音频中合成交谈中的人类形象。该项目提供了训练代码、测试代码、预训练的运动模型以及数

Skeleton Fingers
这是一款基于AI技术的网页音频转录产品,可以直接在浏览器中将音频链接、上传的音频文件或语音录制转换为文字。它具有以下优势:1)无需下载安装,在线即可使用;2)支持多种音频输入方式;3)AI语音识别技术
百宝音
百宝音是一个在线免费文字转语音的配音合成软件,提供近百种配音模板,主打影视解说配音、专题片配音、广告配音等,具有高度定制化的优势,可根据用户需求定制各种音色风格。
Ongkanon
Ongkanon是一款智能对话AI助手,提供有意义且上下文相关的对话体验。它能够自然地与您交谈,就像与亲密的朋友聊天一样。Ongkanon会根据您的偏好进行个性化定制,还能记住以前对话的上下文,以便进
TransVIP
TransVIP是由微软研究院开发的一个创新的语音到语音翻译系统,它能够在翻译过程中保留说话者的声音特征和等时性(即说话的节奏和停顿),这对于视频配音等场景非常有用。TransVIP通过联合概率实现端
PengChengStarling
PengChengStarling 是一个专注于多语言自动语音识别(ASR)的开源工具包,基于 icefall 项目开发。它支持完整的 ASR 流程,包括数据处理、模型训练、推理、微调和部署。该工具包
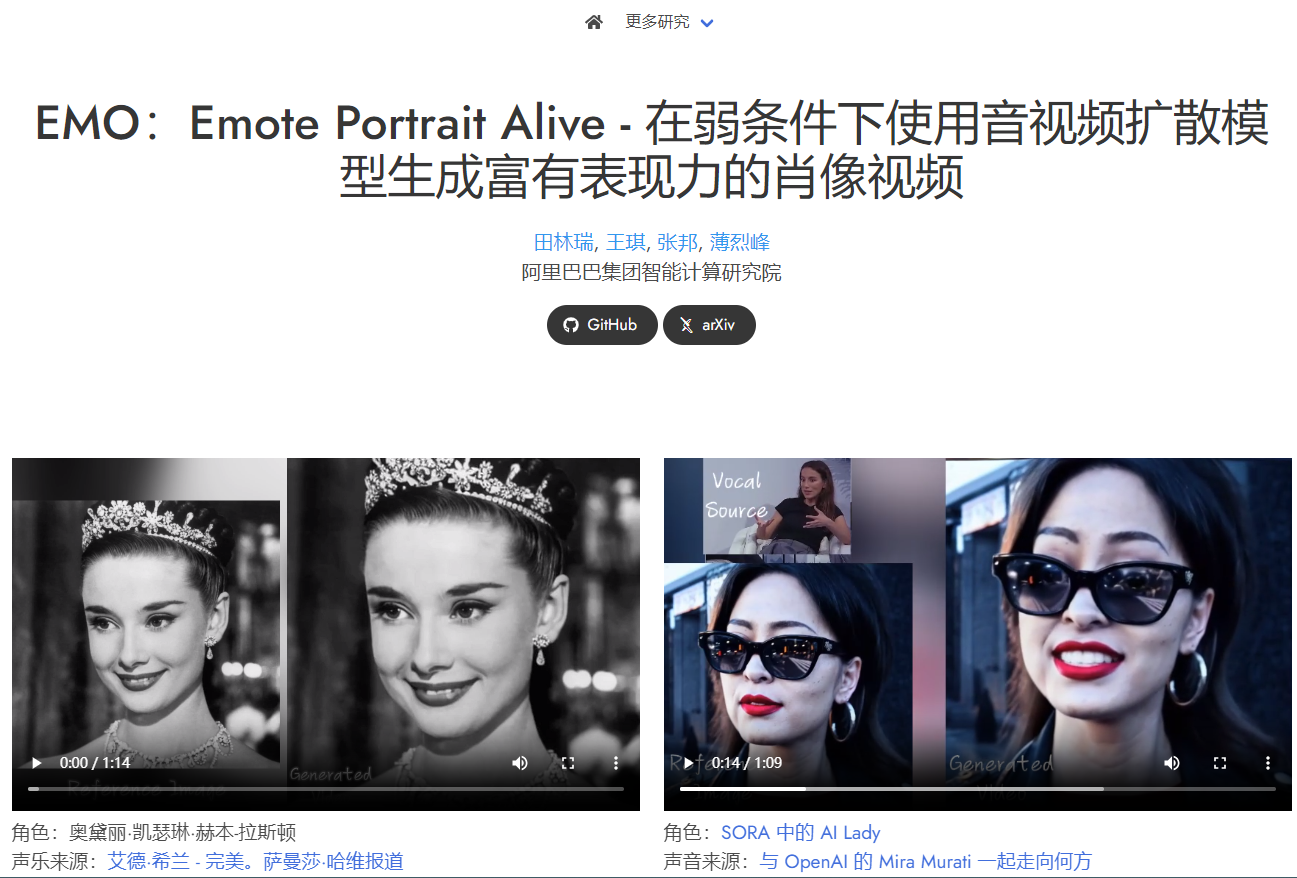
EMO
阿里巴巴的EMO: 是一款生成具有表情丰富的面部表情视频的工具,可以根据输入的角色图像和声音音频生成各种头部姿势和表情的声音头像视频。支持多语言歌曲和各种肖像风格,能够根据音频节奏生成动态、表现丰富

Cerence Chat Pro
Cerence Chat Pro是一款面向汽车制造商的应用,可以通过语音交互的方式,将ChatGPT等生成式AI系统无缝集成到车载系统中。它具有极高的定制性和兼容性,使汽车制造商可以根据品牌定位和用户
DenoLyrics
DenoLyrics是一个基于人工智能模型的网络应用,支持143种语言,无论音频速度快慢。它可以将音频转换为文字,并提供实时的语音转录服务。我们的团队使用最先进的技术,为您提供高质量的转录体验。Den
讯飞A.I.智能客服解决方案
A.I.智能客服解决方案是科大讯飞基于其先进的语音技术,为企业提供的一套完整的客户服务系统。该系统通过电话、Web、APP、小程序、自助终端等多种渠道,实现智能外呼、智能接听、语音导航、在线文字客服、
DiariZen
DiariZen是一个基于AudioZen和Pyannote 3.1驱动的说话人分割工具包。说话人分割是音频处理中的一个关键步骤,它能够将一段音频中的不同说话人进行区分。这项技术在会议记录、电话监控、
Ascenscia
Ascenscia是一个专门针对科学实验室设计的AI语音助手,通过与实验室软件和机器的集成,实现免提交互,加速数据收集,优化工作流程,减少错误,并加速研发周期。产品具备97%的准确率理解复杂科学术语,
firecrawl-openai-realtime
firecrawl-openai-realtime是一个集成了Firecrawl的OpenAI实时API控制台,旨在为开发者提供一个交互式的API参考和检查器。它包括两个实用库,openai/open
OuteTTS-0.1-350M
OuteTTS-0.1-350M是一款基于纯语言模型的文本到语音合成技术,它不需要外部适配器或复杂架构,通过精心设计的提示和音频标记实现高质量的语音合成。该模型基于LLaMa架构,使用350M参数,展
Adobe Project Music GenAI Control
Adobe Research开发的Project Music GenAI Control是一个实验性的AI音乐生成和编辑工具,它允许创作者通过文本提示生成音乐,并提供精细的编辑控制,以满足特定需求。
Agentplace
Agentplace是一个无需编码知识即可在AI模型上构建AI应用和网站平台。它利用AI的适应性、常识、知识和语音能力,允许用户完全通过文本编程。产品的主要优点包括动态用户界面、语音模式、常识理解和即
Wav2Lip
Wav2Lip 是一个开源项目,旨在通过深度学习技术实现视频中人物的唇形与任意目标语音高度同步。该项目提供了完整的训练代码、推理代码和预训练模型,支持任何身份、声音和语言,包括CGI面孔和合成声音。W
Ad Auris
Ad Auris是一款能够将文章转换为语音并播放的应用。用户可以随时随地听取自己感兴趣的文章内容,同时支持保存到平台如Spotify。该应用定位于提升用户的阅读效率和便利性,使用户能够在忙碌的生活中享

DubbingAI
Dubbing AI是一款功能强大的实时AI语音转换软件,它为用户提供超过1000种不同的语音和100多种语言选择,能够实时将任何语音转换成用户所需的语音效果。该软件具有极低的时延和资源占用,与其他类
AI爱好者的一站式人工智能AI工具箱,累计收录全球10,000⁺好用的AI工具软件和网站,方便您更便捷的探索前沿的AI技术。本站持续更新好的AI应用,力争做全球排名前三的AI网址导航网站,欢迎您成为我们的一员。
