首页 >Podcastle和OpenAI TTS对比
Podcastle和OpenAI TTS哪个好用,Podcastle和OpenAI TTS详细对比
Podcastle:Podcastle是一款简单易用的专业音频处理与编辑工具。它提供多轨录音、音频剪辑、智能降噪等功能,让您能够创建高质量的播客节目。同时,它还支持AI语音转文本、文本转语音等创新功能,为您的播客节目添加更多可能性。
OpenAI TTS:OpenAI TTS提供文本到语音的API,基于他们的TTS模型。它带有6种内置语音,可用于朗读博客文章、在多种语言中生成口语音频以及使用流式传输实时音频输出。用户可以通过控制模型名称、文本和语音选择来生成音频文件,并且支持多种音频输出格式。
Podcastle和OpenAI TTS均是AI软件、AI工具中的一种,在功能设计、应用场景、用户体验上存在一些区别,以下是卓商AI整理出来的一些对比选项,仅供您参考。
官网地址
https://podcastle.ai/
https://platform.openai.com/docs/guides/text-to-speech
功能简介
Podcastle是一款简单易用的专业音频处理与编辑工具。它提供多轨录音、音频剪辑、智能降噪等功能,让您能够创建高质量的播客节目。同时,它还支持AI语音转文本、文本转语音等创新功能,为您的播客节目添加更多可能性。
OpenAI TTS提供文本到语音的API,基于他们的TTS模型。它带有6种内置语音,可用于朗读博客文章、在多种语言中生成口语音频以及使用流式传输实时音频输出。用户可以通过控制模型名称、文本和语音选择来生成音频文件,并且支持多种音频输出格式。
排名榜单 🔥
可平替产品
nijivoice
nijivoiceにじボイス是一个利用人工智能技术实现的语音生成平台,用户可以通过选择不同的角色和输入文本来生成富有情感的语音。这项技术的重要性在于它能够提供个性化的声音,满足从娱乐到商业的多种需求,
腾讯云语音识别ASR
腾讯云语音识别(ASR)为开发者提供语音转文字服务的最佳体验。语音识别服务具备识别准确率高、接入便捷、性能稳定等特点。腾讯云语音识别服务开放实时语音识别、一句话识别和录音文件识别三种服务形式,满足不同
aTrain
aTrain是由格拉茨大学商业分析与数据科学中心的研究人员开发,并由格拉茨知识中心的研究人员测试的一款离线语音转录工具。它利用最新的机器学习模型,无需上传任何数据即可自动转录语音录音。aTrain在《
AuroraAI
AuroraAI是由Incribo开发的产品,可以生成安全高质量的训练数据,为您的AI模型加速发展。它可以用于多种用途,包括语音合成、音频分割、人物建模、景观设计、图像处理等。AuroraAI注重隐私
麦耳会记
麦耳会记是一款集实时语音转写、实时翻译和 AI 辅助写作功能为一体的 AI 办公助手。它可以用于办公会议、学生网课、客户访谈录音等场景。软件支持边录音、边转写,录音结束后,音频、文本实时同步至 PC

StreamVoice
StreamVoice是一种基于语言模型的零唇语音转换模型,可实现实时转换,无需完整的源语音。它采用全因果上下文感知语言模型,结合时间独立的声学预测器,能够在每个时间步骤交替处理语义和声学特征,从而消
视频翻译配音
视频翻译配音是一个免费开源的视频翻译和配音工具,支持多种翻译引擎,可以将视频字幕翻译成多种语言,并生成自然的语音配音,操作简单方便。
UltimateAI
UltimateAI是一款基于AI的WordPress SaaS插件,提供AI生成文章、人类级博客帖子、广告等高质量内容,还可以生成代码、聊天机器人和图片等。它具有快速、灵活、易于使用和定制等特点。U
Bespoken
Bespoken是一个在线语言学习平台,提供个性化的学习计划,根据用户填写的学习目标和当前语言水平,自动生成适合用户的学习路线图,指导用户学习新语言。该平台提供大量真实场景对话和范例,用户可以随时练习
AVbeam
AVbeam是一款音频比对软件,可用于比较多个音频文件,识别相匹配的音频片段。它支持多种音频格式,能够识别部分匹配的音频片段,并展示匹配的时间偏移和相似度等信息。AVbeam采用强大的音频比对算法,能
呱呱有声
呱呱有声有声制作AI+是一款全流程一体化的声音制作工具,结合人机合作、语音合成、虚拟录音棚和全链条数据,旨在提高制作效率、降低成本。用户可以利用AI辅助画本和全自动对轨功能,轻松完成声音制作。产品支持
AV-HuBERT
AV-HuBERT是一个自监督表示学习框架,专门用于音视觉语音处理。它在LRS3音视觉语音基准测试中实现了最先进的唇读、自动语音识别(ASR)和音视觉语音识别结果。该框架通过掩蔽多模态聚类预测来学习音
AudioLCM
AudioLCM是一个基于PyTorch实现的文本到音频生成模型,它通过潜在一致性模型来生成高质量且高效的音频。该模型由Huadai Liu等人开发,提供了开源的实现和预训练模型。它能够将文本描述转化
botsplash.com
Botsplash是一款能够让您在聊天平台上与客户互动的一站式解决方案。它集成了多个渠道,通过一个基于SaaS的仪表板实现与客户的沟通。Botsplash能够帮助您提高收入、降低成本、生成更多潜在客户
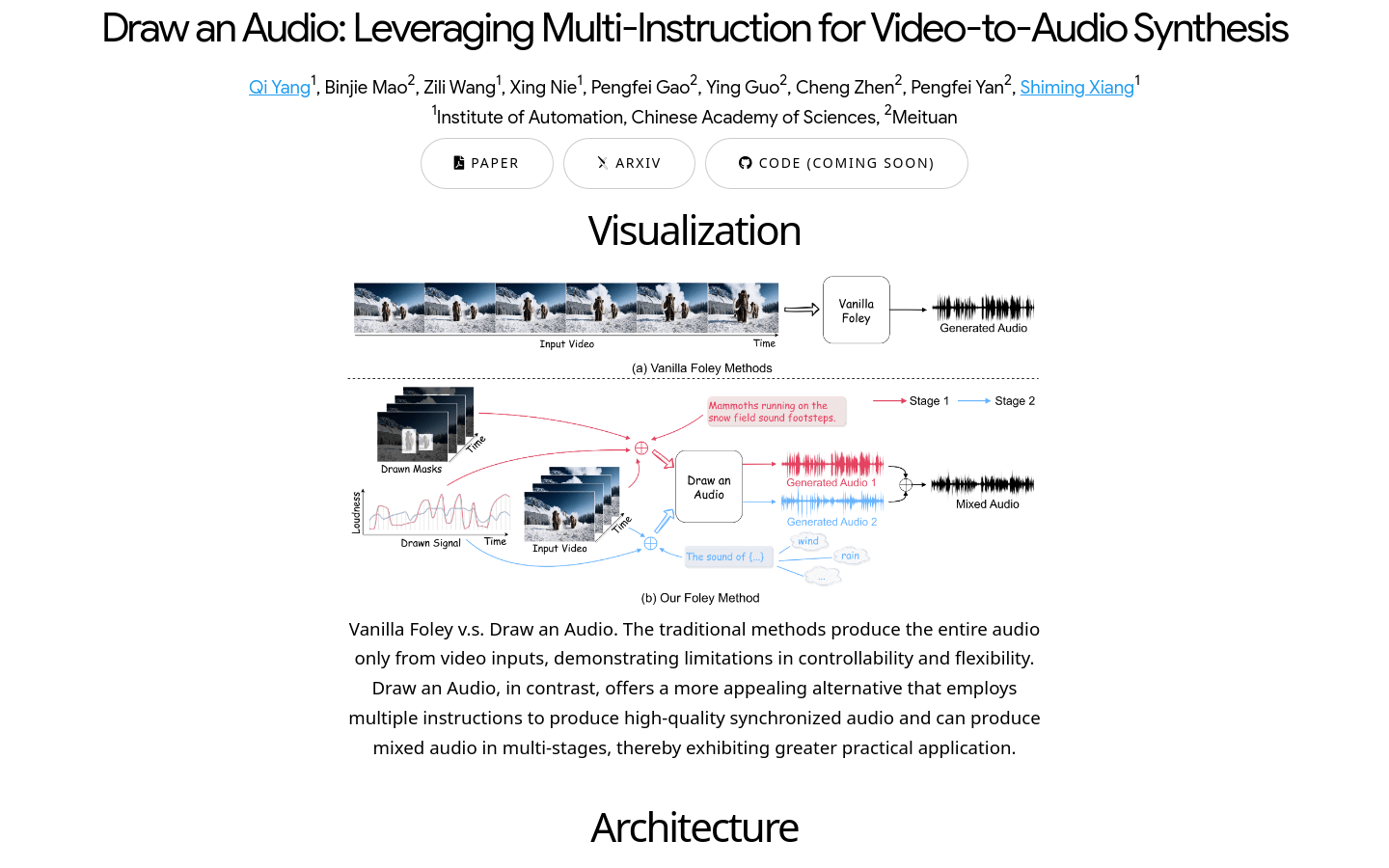
Draw an Audio
Draw an Audio是一个创新的视频到音频合成技术,它通过多指令控制,能够根据视频内容生成高质量的同步音频。这项技术不仅提升了音频生成的可控性和灵活性,还能够在多阶段产生混合音频,展现出更广泛的
Wondercraft
Wondercraft是一个创新的在线服务,能够将作者的书稿转化为听起来像作者本人声音的语音阅读。这项技术不仅节省了作者在录音棚录制和雇佣音频专家编辑混音的时间和金钱,而且提供了一个高效、经济的解决方
OmniAudio-2.6B
OmniAudio-2.6B是一个2.6B参数的多模态模型,能够无缝处理文本和音频输入。该模型结合了Gemma-2B、Whisper turbo和一个自定义投影模块,与传统的将ASR和LLM模型串联的
Transcribethis.io
TranscribeThis是一款AI音频转录工具,提供高准确度和高精度的转录服务,帮助用户节省时间和精力。无论是采访、会议、播客还是讲座,都可以快速将音频转换为文字,支持近60种语言。采用AI转录技
AI-Powered Sleep Story Generator
AI-Powered Sleep Story Generator是一款创新的AI驱动工具,旨在帮助用户进入深度而宁静的睡眠。用户可以描述自己理想的睡眠场景,AI将利用最新技术制作出舒缓而沉浸式的音频故
Zivy Listen
Zivy Listen是一款可以将长篇文章、新闻简报等内容转化为关键观点的音频摘要的应用。用户可以在任何时间、任何地点通过听取音频摘要来节省时间并获取关键信息。该应用还提供了多种功能,包括根据个人喜好
ShipGPT AI
StartP是一个AI模型快速部署与集成的网站模板,通过集成AI技术,可以将应用程序转化为智能应用程序,也可以构建全新的AI应用程序。StartP提供各种API,可以用于处理文档、音频、视频、网站等不
OpenAI TTS
OpenAI TTS提供文本到语音的API,基于他们的TTS模型。它带有6种内置语音,可用于朗读博客文章、在多种语言中生成口语音频以及使用流式传输实时音频输出。用户可以通过控制模型名称、文本和语音选择
GPT-Minus1
PGPT-Minus1是一款在线文本转录工具,可以将您的音频文件转录为完美的文本。它使用最先进的语音识别技术,支持多种语言和文件格式。GPT-Minus1的优势在于准确性高、速度快、易于使用。
Listen Monster
ListenMonster是一款免费的英文字幕生成工具,可以将音频和视频转写为文本。它快速、准确,并且100%免费。你可以将结果以txt、srt和vtt格式下载,而且没有水印。
AI爱好者的一站式人工智能AI工具箱,累计收录全球10,000⁺好用的AI工具软件和网站,方便您更便捷的探索前沿的AI技术。本站持续更新好的AI应用,力争做全球排名前三的AI网址导航网站,欢迎您成为我们的一员。
