首页 >Bangin Audio Recorder和PodSnacks对比
Bangin Audio Recorder和PodSnacks哪个好用,Bangin Audio Recorder和PodSnacks详细对比
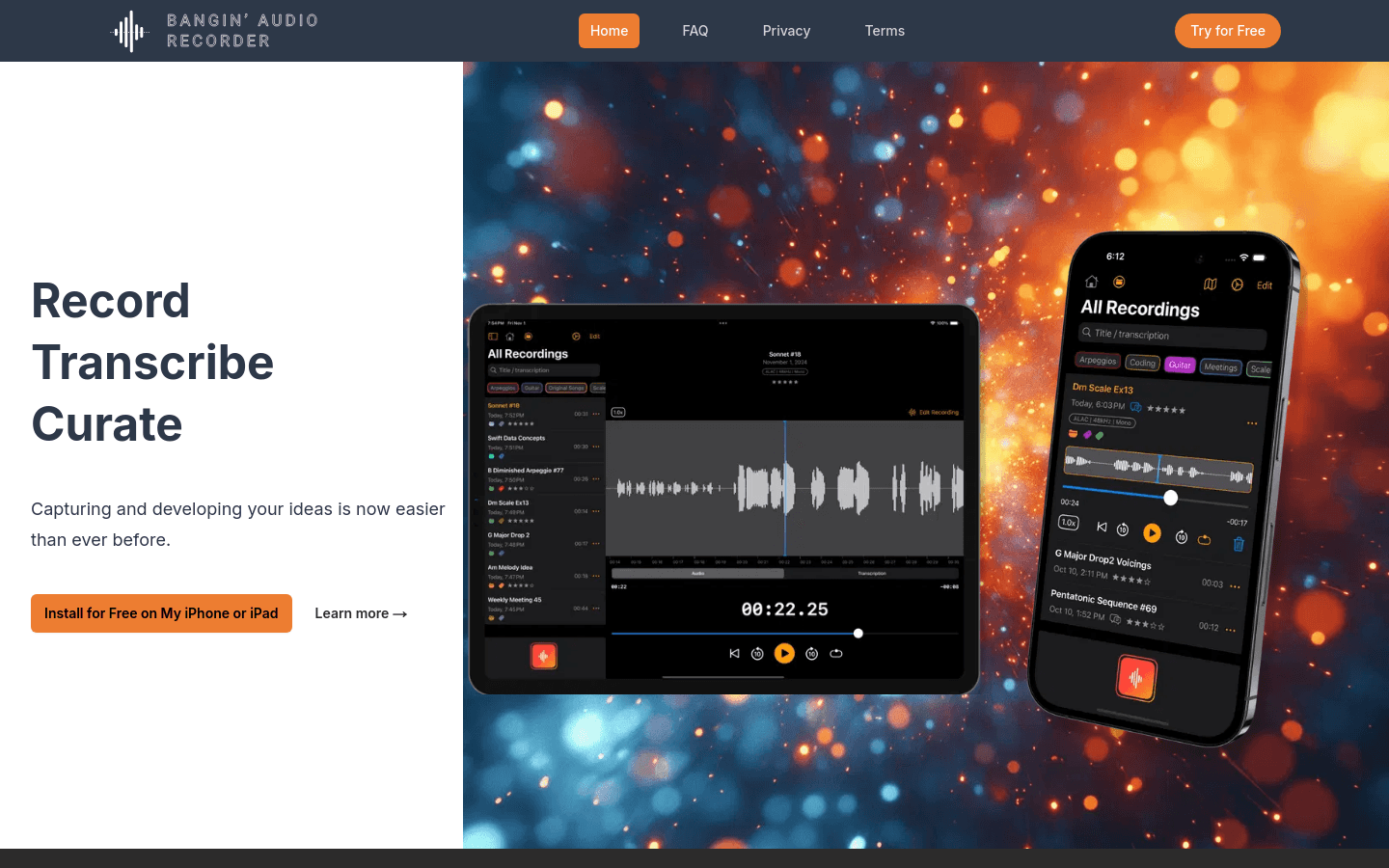
Bangin Audio Recorder:Bangin Audio Recorder是一款专为苹果平台设计的应用程序,旨在简化声音捕捉和想法发展的过程。由音乐作曲家、开发者Alistair Cooper创立,该应用支持高质量单声道或立体声音频录制,具备定制的语音时间戳算法,便于用户扫描和跳过语音录音。它还提供星级评分功能,帮助用户筛选出最佳
PodSnacks:PodSnacks是一款智能转录和摘要工具,帮助用户快速将音频转换为文字,并提供摘要功能。它使用先进的人工智能技术,准确地将音频内容转录为文字,并根据用户需求生成摘要。PodSnacks提供高效的转录和摘要服务,帮助用户节省时间和精力。定价灵活,适用于个人用户和商业用户。
Bangin Audio Recorder和PodSnacks均是AI软件、AI工具中的一种,在功能设计、应用场景、用户体验上存在一些区别,以下是卓商AI整理出来的一些对比选项,仅供您参考。
官网地址
https://www.banginaudiorecorder.com/
https://www.podsnacks.org/
功能简介
Bangin Audio Recorder是一款专为苹果平台设计的应用程序,旨在简化声音捕捉和想法发展的过程。由音乐作曲家、开发者Alistair Cooper创立,该应用支持高质量单声道或立体声音频录制,具备定制的语音时间戳算法,便于用户扫描和跳过语音录音。它还提供星级评分功能,帮助用户筛选出最佳创意,并支持标签、项目和搜索功能,以保持用户对重要录音的专注。此外,它还具备iCloud同步功能,确保用户在所有苹果设备上的录音保持最新。
PodSnacks是一款智能转录和摘要工具,帮助用户快速将音频转换为文字,并提供摘要功能。它使用先进的人工智能技术,准确地将音频内容转录为文字,并根据用户需求生成摘要。PodSnacks提供高效的转录和摘要服务,帮助用户节省时间和精力。定价灵活,适用于个人用户和商业用户。
排名榜单 🔥
可平替产品
Universal-2
Universal-2是AssemblyAI推出的最新语音识别模型,它在准确度和精确度上超越了前一代Universal-1,能够更好地捕捉人类语言的复杂性,为用户提供无需二次检查的音频数据。这一技术的

SafeEar
SafeEar是一个创新的音频深度检测框架,它能够在不依赖于语音内容的情况下检测深度音频。这个框架通过设计一个神经音频编解码器,将语义和声学信息从音频样本中分离出来,仅使用声学信息(如韵律和音色)进行
AuroraAI
AuroraAI是由Incribo开发的产品,可以生成安全高质量的训练数据,为您的AI模型加速发展。它可以用于多种用途,包括语音合成、音频分割、人物建模、景观设计、图像处理等。AuroraAI注重隐私

Megrez-3B-Omni
Megrez-3B-Omni是由无问芯穹研发的端侧全模态理解模型,基于大语言模型Megrez-3B-Instruct扩展,具备图片、文本、音频三种模态数据的理解分析能力。该模型在图像理解、语言理解、语
ToolBaz
ToolBaz是一款免费的AI写作工具,可以帮助用户生成各种AI内容,包括故事、邮件、歌词、图片、语音等。它提供多种AI工具,能够快速生成与人类写作相似的内容,满足用户各种写作需求。
ElevenLabs GenFM
ElevenReader 是一款利用人工智能技术将PDF、文章、电子书等文本内容转化为播客的应用。它通过AI技术生成智能播客,让用户在任何时间、任何地点都能聆听内容。产品背景信息显示,ElevenLa
Just Story It
Just Story It是一款基于AI技术的音频故事创作平台。用户可以创建角色和环境,选择流派、时长和自定义输入,用于制作自己的音频故事。平台提供了Discovery Stories库,用户可以在其

Wavflow.io
wavflow是一款最终的AI文本转语音生成器,无需订阅,积分不过期。它使用人工智能技术将文本转换为逼真的语音,适用于将文档、书籍和课程转换为语音。wavflow提供多种AI语音选择,具有快速、安全的
Stable Audio Open
Stable Audio Open是一个开源的文本到音频模型,专为生成短音频样本、音效和制作元素而优化。它允许用户通过简单的文本提示生成高达47秒的高质量音频数据,特别适用于创造鼓点、乐器即兴演奏、环
VoiceRec
VoiceRec 是一款集语音录制、转文字识别与共享于一体的人工智能语音应用。支持语音转文字、精准识别、支持多国语言、支持导出多种格式。
Clone-Voice
Clone-Voice是一个带 web 界面的声音克隆工具,可使用任何人类音色,将一段文字合成为使用该音色说话的声音,或者将一个声音使用该音色转换为另一个声音。支持中、英、日、韩、法、德、意等 16
OpenAI.fm
OpenAI.fm 是一个互动演示平台,允许开发者体验 OpenAI API 中的最新文本转语音模型gpt-4o-transcribe, gpt-4o-mini-transcribe and gpt-
Onyxium
Onyxium是一个综合性的AI工具平台,提供包括图像识别、文本分析、语音识别等在内的多种AI技术。它旨在帮助用户轻松访问最新AI技术,以低成本使用这些工具,提升项目和工作流程的效率。
Aura TTS Demo by Deepgram
Aura TTS(文字转语音)演示展现了Deepgram的高级语音合成技术,可以将文本转换成自然发音的语音,并提供多种声音选项。

Audiobox
Audiobox是Meta的新一代音频生成研究模型,可以利用语音输入和自然语言文本提示生成声音和音效,轻松为各种用例创建定制音频。Audiobox系列模型还包括专业模型Audiobox Speech和
Hanami Live Translator
Hanami Live Translator是一个实时翻译器,可以捕捉来自WINDOWS扬声器和麦克风的任何音频。它使用轻量级多进程和分块处理音频,每个块处理时间约为3-5秒。该应用程序通过低级访问创

finevoice text to speech
FineVoice是语音工具的直观AI驱动文本,具有40多种语言的500多种声音。它通过AI技术使创建配音变得快速,简单,以使过程和可自定义选项自动化以获取更多详细信息。立即使用FineVoice释放
Outspeed
Outspeed是一个为构建快速、实时语音和视频AI应用提供网络和推理基础设施的平台。它由Google和MIT的工程师开发,旨在为实时AI应用提供直观且强大的工具,无论是构建下一个大型应用还是扩展现有
OuteTTS-0.1-350M
OuteTTS-0.1-350M是一款基于纯语言模型的文本到语音合成技术,它不需要外部适配器或复杂架构,通过精心设计的提示和音频标记实现高质量的语音合成。该模型基于LLaMa架构,使用350M参数,展
WAKE UP MOTHAF&#$R
WAKE UP MOTHAF&#$R是一个提供个性化AI语音唤醒服务的网站,模仿知名人物David Goggins的声音,帮助用户在早晨醒来。该工具由David Goggins的粉丝们创建,并非由Da
Gan.AI
Gan.AI是一个专注于对话式人工智能研究和产品的公司,致力于通过其先进的AI技术,为全球知名品牌提供个性化的视频和音频通信解决方案。该公司的产品和技术在个性化营销、粉丝参与、以及提升用户体验方面展现
Origlio
Origlio是一款音频转文字的服务,还提供更多功能。它可以将您的音频消息转录成文字,帮助您管理和整理语音消息。您可以将音频转发给Origlio,几秒钟后即可获得转录结果。除了音频转录,Origlio
PodSnap.AI
PodSnap.AI是一个利用尖端AI技术,为用户提供播客摘要的服务。用户可以通过订阅,将播客的AI生成摘要直接发送到他们的邮箱。这项服务帮助用户节省时间,快速获取播客中的关键信息,特别适合忙碌的专业

Clone Anyones voice in seconds with AI
克隆我的声音是一个能够在几秒钟内克隆任何人的声音,并将其应用于任何音频内容的产品。即使作为一个英语初学者,您也可以获得一个出色的英语声音和发音。它可以立即提升您的音频内容质量,您可以轻松准确地为演讲、
AI爱好者的一站式人工智能AI工具箱,累计收录全球10,000⁺好用的AI工具软件和网站,方便您更便捷的探索前沿的AI技术。本站持续更新好的AI应用,力争做全球排名前三的AI网址导航网站,欢迎您成为我们的一员。
