首页 >PlayNote和VideoReTalking对比
PlayNote和VideoReTalking哪个好用,PlayNote和VideoReTalking详细对比
PlayNote:PlayNote是一款利用尖端AI语音合成技术,将各种文件和数据转换成音频创作的产品。它支持多种文件格式,包括PDF、CSV、TXT等文档,以及PNG、JPEG等图片格式,还有MP4、MOV等视频格式,以及WAV、MP3等音频格式。用户可以上传文件,PlayNote会将文件内容转化为音频,方便用户在
VideoReTalking:VideoReTalking是一个新的系统,可以根据输入的音频编辑真实世界的说话头部视频的面部,产生高质量的唇形同步输出视频,即使情感不同。该系统将此目标分解为三个连续的任务:(1)使用表情编辑网络生成带有规范表情的面部视频;(2)音频驱动的唇形同步;(3)用于提高照片逼真度的面部增强。给定一个说话
PlayNote和VideoReTalking均是AI软件、AI工具中的一种,在功能设计、应用场景、用户体验上存在一些区别,以下是卓商AI整理出来的一些对比选项,仅供您参考。

官网地址
https://opentalker.github.io/video-retalking/
功能简介
PlayNote是一款利用尖端AI语音合成技术,将各种文件和数据转换成音频创作的产品。它支持多种文件格式,包括PDF、CSV、TXT等文档,以及PNG、JPEG等图片格式,还有MP4、MOV等视频格式,以及WAV、MP3等音频格式。用户可以上传文件,PlayNote会将文件内容转化为音频,方便用户在各种场合下收听。这项技术的重要性在于它能够提高信息的可访问性,特别是对于视觉障碍人士或者在无法阅读的情况下需要获取信息的用户。PlayNote的背景信息显示,它是由PlayAI提供的,旨在通过技术创新提升工作效率和生活质量。关于价格,用户可以访问Pricing页面了解更多详情。
VideoReTalking是一个新的系统,可以根据输入的音频编辑真实世界的说话头部视频的面部,产生高质量的唇形同步输出视频,即使情感不同。该系统将此目标分解为三个连续的任务:(1)使用表情编辑网络生成带有规范表情的面部视频;(2)音频驱动的唇形同步;(3)用于提高照片逼真度的面部增强。给定一个说话头部视频,我们首先使用表情编辑网络根据相同的表情模板修改每个帧的表情,从而得到具有规范表情的视频。然后将该视频与给定的音频一起输入到唇形同步网络中,生成唇形同步视频。最后,我们通过一个身份感知的面部增强网络和后处理来提高合成面部的照片逼真度。我们对所有三个步骤使用基于学习的方法,所有模块都可以在顺序管道中处理,无需任何用户干预。
排名榜单 🔥
可平替产品
Silvia
Silvia是一款能够适应用户说话方式的语音输入系统,支持用户在不同语言之间自由切换,即使在句子中也能无缝切换。它支持英语和西班牙语,并且即将支持法语、罗马尼亚语、德语和荷兰语。Silvia作为苹果应
Aimusic so
AI Music Generator Free Online是一个创新的音乐生成平台,利用先进的深度学习技术,将用户输入的文本转化为充满情感和高质量的音乐作品。该平台能够覆盖广泛的音乐风格,从古典音乐
Udio v1.5
Udio v1.5是一个音乐创作平台的高级版本,它在v1的基础上进行了多项改进,包括提高音质、提供音调控制、改善全球语言支持等。它生成48kHz立体声轨道,提供更清晰的音质和更好的乐器分离度。此外,U
AI Music Generator
AI音乐生成器(AMG)是一款通过简单描述即可生成音频片段的AI工具。它由Meta的AudioCraft技术提供支持。每秒0.008美元,试用版可生成60秒。
Jib
Jib是一款基于语音的人工智能助手,它快速且流畅,以至于几乎无法分辨它是一个机器人。它支持完全免提操作,非常适合在移动中、在车内或步行时使用。Jib能够处理中断,用户可以在其回应过程中随时打断它,而不
Gemini 1.5 Flash
Gemini 1.5 Flash是Google DeepMind团队推出的最新AI模型,它通过蒸馏过程从更大的1.5 Pro模型中提炼出核心知识和技能,以更小、更高效的模型形式提供服务。该模型在多模态
Home Assistant Voice
Home Assistant Voice Preview Edition是一款开源、注重隐私的语音助手硬件产品,旨在提供一种开放、本地化、私人化的语音控制解决方案。它允许用户通过语音控制家中的智能设备
Coqui
Coqui Studio通过生成式人工智能实现了逼真、感性的文本转语音,用户可以克隆现有声音或设计自己的理想声音,还可以调整语速和情感,全面掌控AI声音。通过高级编辑器,用户可以为每个句子、单词或角色
Kits AI
Kits AI 是一个 AI 声音生成和免费 AI 声音训练平台,让音乐人使用和创建 AI 声音。您可以使用 Kits.AI 来改变您的声音,使用我们的官方授权或免费声音库中的 AI 艺术家声音,也可
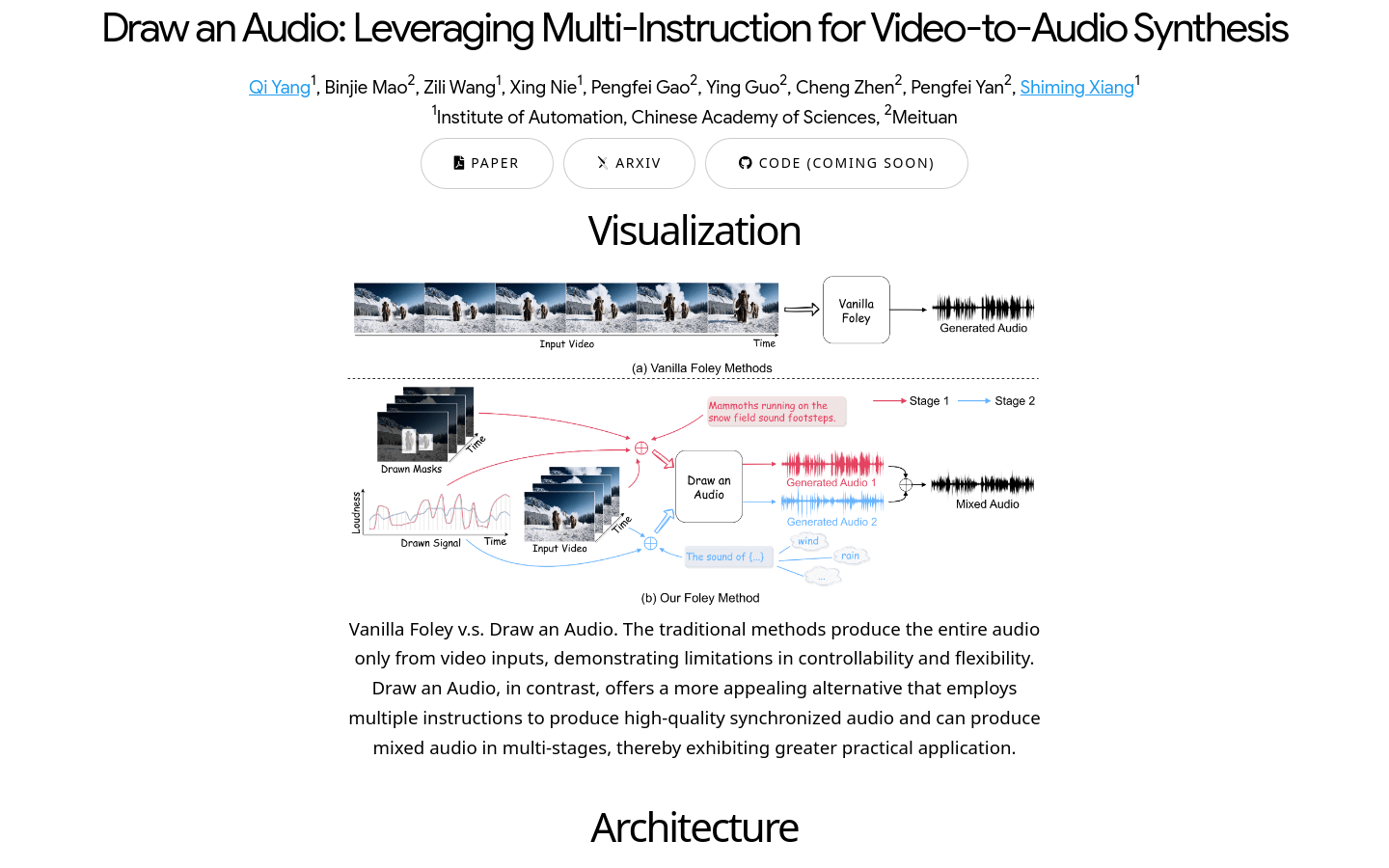
Draw an Audio
Draw an Audio是一个创新的视频到音频合成技术,它通过多指令控制,能够根据视频内容生成高质量的同步音频。这项技术不仅提升了音频生成的可控性和灵活性,还能够在多阶段产生混合音频,展现出更广泛的
instaSpeak
instaSpeak AI bot 是一款强大的语音转文字 AI 机器人。它可以将用户输入的语音实时转换为文字,并且支持多种语言识别。用户可以在网站上直接录制语音,并立即获得文字转录。instaSpe
StreamVC
StreamVC是由Google研发的实时低延迟语音转换解决方案,能够在保持源语音内容和韵律的同时,匹配目标语音的音色。该技术特别适合实时通信场景,如电话和视频会议,并且可用于语音匿名化等用例。Str
deciphr
Deciphr AI是一款创新的人工智能技术,可以将单一内容转化为多媒体资产,让您的受众在一键之间与之互动。无论是文章、音频还是视频,Deciphr AI都能以瞬间生成引人入胜的多媒体内容。您可以上传
AI Cover
AI Cover是一个音乐创作工具,它通过人工智能技术,让用户能够模仿不同艺术家的声音,快速生成歌曲翻唱。这项技术使用先进的算法分析并复制艺术家的声音特征,使得用户无需专业技能即可创作出听起来像是原唱
Stable Audio Open 1.0
Stable Audio Open 1.0是一个利用自编码器、基于T5的文本嵌入和基于变压器的扩散模型来生成长达47秒的立体声音频的AI模型。它通过文本提示生成音乐和音频,支持研究和实验,以探索生成性
Audo Studio
Audo Studio是一款利用最新的音频处理和人工智能技术,自动去除背景噪音并提升语音质量的工具。只需点击一次按钮,即可快速清理音频,节省时间和精力。功能包括高级噪音去除、回声降低和自动音量调整。A
Llasa
Llasa是一个基于Llama框架的文本到语音(TTS)基础模型,专为大规模语音合成任务设计。该模型利用16万小时的标记化语音数据进行训练,具备高效的语言生成能力和多语言支持。其主要优点包括强大的语音
MVSEP
MVSEP是一款在线音频处理工具,利用先进的音频分离技术可将音乐和语音从音频文件中分离出来,适用于音乐制作、音频编辑、广播、电影后期制作等领域。优点包括高质量的音频输出、快速的处理速度和用户友好的操作
sherpa-onnx
sherpa-onnx 是一个基于下一代 Kaldi 的语音识别和语音合成项目,使用onnxruntime进行推理,支持多种语音相关功能,包括语音转文字(ASR)、文字转语音(TTS)、说话人识别、说
Voxos
Voxos 是一款多功能且用户友好的桌面语音助手,可将LLM集成到日常工作流程中,相比于使用Web UI访问LLM,它更加简化。它非常适合任何使用桌面计算机且希望节省时间和精力的人。此外,您还可以在V
TranscribeAudio
TranscribeAudio是一个易于使用的转录工具和编辑器,可以在几分钟内将您的音频文件转换为文本。它能够准确地将语音转换为文字,并提供简单的编辑功能,以便您对转录进行审查和修改。您还可以将转录导

AI-Spy
Ai-SPY通过专有算法训练,可以准确区分人类和机器生成的音频,确保您能够以绝对的信心聆听。您只需要上传文件,Ai-SPY将告诉您它是由人工智能还是人类生成的。通过Ai-SPY,您可以验证音频内容,保
Audio Writer
Audio Writer将您的语音即时转换为清晰、连贯的文字。不仅如此,我们还可以帮助您将思维转化为各种格式的内容。支持多种语言转录,提供错误自动修正,可根据不同风格进行重写,并可以导出不同格式的内容
AI爱好者的一站式人工智能AI工具箱,累计收录全球10,000⁺好用的AI工具软件和网站,方便您更便捷的探索前沿的AI技术。本站持续更新好的AI应用,力争做全球排名前三的AI网址导航网站,欢迎您成为我们的一员。
