首页 >Adobe Podcast和Chopcast对比
Adobe Podcast和Chopcast哪个好用,Adobe Podcast和Chopcast详细对比
Adobe Podcast:Adobe Podcast是一款基于人工智能技术的音频录制和编辑工具。它提供清晰、高质量的音频录制和编辑功能,支持自动转录、剪辑和分享。无论您是专业的播客主持人还是想要创作自己的播客节目,Adobe Podcast都可以满足您的需求。它还提供多种音频效果和工具,帮助您创建独特而专业的音频内容。Ado
Chopcast:chopcast是一个内容再利用平台,通过使用OpenAI的GPT技术,自动识别关键时刻,设计为适合分享的YouTube Shorts、Reels、TikToks、Slack视频等。用户可以将YouTube视频、播客和录音上传到平台,chopcast会自动为您生成建议的片段。您还可以根据演讲者检测、
Adobe Podcast和Chopcast均是AI软件、AI工具中的一种,在功能设计、应用场景、用户体验上存在一些区别,以下是卓商AI整理出来的一些对比选项,仅供您参考。
官网地址
https://podcast.adobe.com
https://chopcast.io/
功能简介
Adobe Podcast是一款基于人工智能技术的音频录制和编辑工具。它提供清晰、高质量的音频录制和编辑功能,支持自动转录、剪辑和分享。无论您是专业的播客主持人还是想要创作自己的播客节目,Adobe Podcast都可以满足您的需求。它还提供多种音频效果和工具,帮助您创建独特而专业的音频内容。Adobe Podcast定价灵活,适用于个人和团队使用。
chopcast是一个内容再利用平台,通过使用OpenAI的GPT技术,自动识别关键时刻,设计为适合分享的YouTube Shorts、Reels、TikToks、Slack视频等。用户可以将YouTube视频、播客和录音上传到平台,chopcast会自动为您生成建议的片段。您还可以根据演讲者检测、主题选择等进行自定义剪辑。编辑好的片段可以导出为TikTok、YouTube Shorts、Reel等多种格式。此外,您还可以使用chopcast将文本转录稿转化为文章,将视频转化为音频播客等。chopcast旨在帮助B2B团队节省时间和精力。
排名榜单 🔥
可平替产品
JASCO
JASCO是一个结合了符号和基于音频的条件的文本到音乐生成模型,它能够根据全局文本描述和细粒度的局部控制生成高质量的音乐样本。JASCO基于流匹配建模范式和一种新颖的条件方法,允许音乐生成同时受到局部
PodCastLM
PodCastLM是一个创新的智能播客生成平台,它利用先进的人工智能技术,让用户能够快速生成个性化的音频内容。用户只需上传PDF文件,选择问题、语气、时长和语言等参数,即可生成一段高质量的音频播客。该
VoicBot, AI Chatbot with ultra Realistic Voice
VocBot Turbo 是一个高效的语音转文字工具,可以快速将语音内容转换为文字,支持多种语言和音频格式,提供准确的识别结果。VocBot Turbo具有高度的准确性和灵活性,适用于各种场景,包括会
Speech to Note
Speech to Note是一个AI驱动的语音识别工具,能够即时将口语转换为文本。它使用先进的语音转文本技术,将您的语音转换成可以编辑或分享的简洁摘要。该产品由GPT-4技术支持,旨在提升生产力并释
Chopcast
chopcast是一个内容再利用平台,通过使用OpenAI的GPT技术,自动识别关键时刻,设计为适合分享的YouTube Shorts、Reels、TikToks、Slack视频等。用户可以将YouT
OptiSpeech
OptiSpeech是一个高效、轻量级且快速的文本到语音模型,专为设备端文本到语音转换设计。它利用了先进的深度学习技术,能够将文本转换为自然听起来的语音,适合需要在移动设备或嵌入式系统中实现语音合成的
AudioSeal
AudioSeal 是一种用于AI生成语音音频的本地化水印技术,具有最先进的鲁棒性和极快的检测速度。它通过联合训练一个嵌入水印的生成器和一个检测器,即使在音频编辑的情况下,也能在较长的音频中检测到水印
Xound.io
Xound是一个人工智能驱动的声音增强系统。它可以自动清理背景噪音,校正音高,提高音频质量,为YouTube和TikTok创作者提供专业水准的音频。该系统使用先进的机器学习算法,可以本地处理音频文件,
理想同学
理想同学是由理想汽车依托自研大模型精心打造的一款人工智能应用,旨在为用户提供一个随时在线的智能助手。它具备知识问答能力,能解答汽车、出行、财经、科技等领域的问题,并擅长英文词句翻译、文本生成等,助力用
Luvvoice
Luvvoice是一个免费的文字转语音工具,提供200多种声音选择,可根据用户需求将文本转化为语音。Luvvoice具有易用性、多语言支持和高质量的声音合成等优势。Luvvoice的定价非常实惠,让用

Gemini 2.0 Flash Experimental
Gemini 2.0 Flash Experimental是Google DeepMind开发的最新AI模型,旨在提供低延迟和增强性能的智能代理体验。该模型支持原生工具使用,并首次能够原生创建图像和生
ultravox-v0_4_1-llama-3_1-70b
fixie-ai/ultravox-v0_4_1-llama-3_1-70b是一个基于预训练的Llama3.1-70B-Instruct和whisper-large-v3-turbo的大型语言模型,能
Azure 认知服务语音
Azure 认知服务语音是微软推出的一款语音识别与合成服务,支持超过100种语言和方言的语音转文本和文本转语音功能。它通过创建可处理特定术语、背景噪音和重音的自定义语音模型,提高听录的准确度。此外,该

NotHotDog
NotHotDog是一个专注于自动化测试AI代理和语音AI应用的平台。它通过提供自动化、可复用的语音测试案例,简化了对语音API、WebSocket API以及对话AI系统的测试和监控,从而加速功能部

MusicLM
MusicLM是一个模型,可以根据文本描述生成高保真音乐。它可以生成24kHz的音频,音乐风格和文本描述一致,并支持根据旋律进行条件生成。通过使用MusicCaps数据集,模型在音频质量和与文本描述的
Image Describer
Image Describer图像描述生成器是一款利用人工智能技术,通过上传图像并根据用户需求输出图像描述的工具。它能够理解图像内容,并生成详细的描述或解释,帮助用户更好地理解图片含义。这款工具不仅适
Fish Speech
Fish Speech是一款专注于语音合成的产品,它通过使用先进的深度学习技术,能够将文本转换为自然流畅的语音。该产品支持多种语言,包括中文、英文等,适用于需要文本到语音转换的场景,如语音助手、有声读
Open-LLM-VTuber
Open-LLM-VTuber 是一个开源项目,旨在通过语音与大型语言模型(LLM)进行交互,具有实时的Live2D面部捕捉和跨平台的长期记忆功能。该项目支持macOS、Windows和Linux平台
Truecaller
Truecaller是一个全球领先的平台,致力于验证联系人和阻止不受欢迎的通信。它使人们之间的安全和相关对话成为可能,并使企业与消费者之间的联系更加高效。Truecaller致力于在数字经济中建立通信
GPTAssistant
这是一个基于ChatGPT API开发的安卓端语音助手APP,支持语音交互、连续对话、识别图片等功能。用户只需通过手机音量键,就可以从任意界面唤起并进行语音提问,无需打字,交互体验极佳。支持自定义问题
MaskGCT TTS Demo
MaskGCT TTS Demo 是一个基于MaskGCT模型的文本到语音(TTS)演示,由Hugging Face平台上的amphion提供。该模型利用深度学习技术,将文本转换为自然流畅的语音,适用
Music.AI
The Audio Intelligence Platform™是一款面向企业和开发者的音频智能平台。它提供了一系列先进的 Complementary AI™ 模型,可用于音频分离、转录、混音、母带制
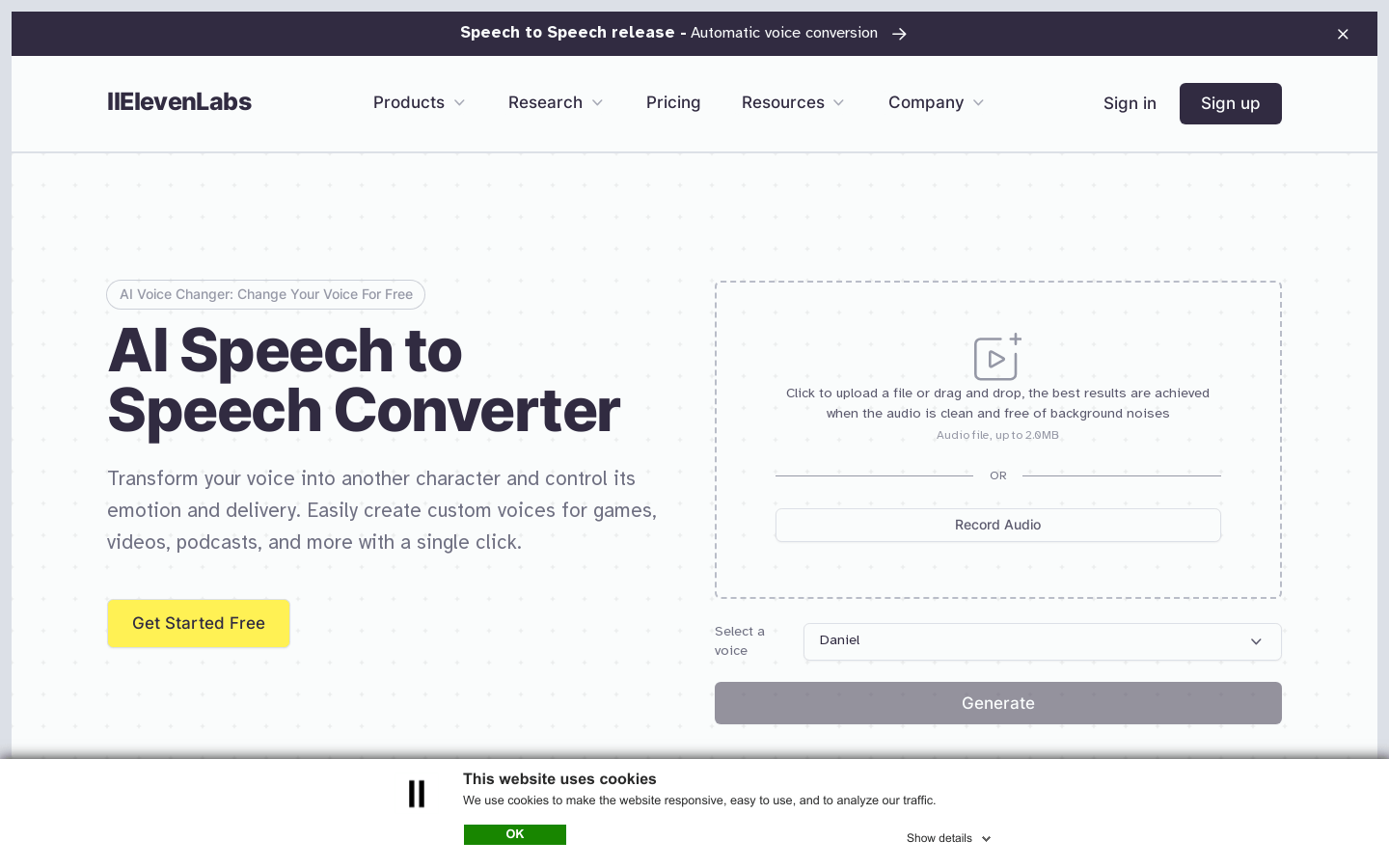
Voice Changer
Voice Changer可以将您的声音转换为另一个角色,并控制其情感和表达。通过单击轻松为游戏、视频、播客等创建自定义语音。您可以选择现有的声音库中的声音,也可以在几分钟内创建自己的声音。通过高级设
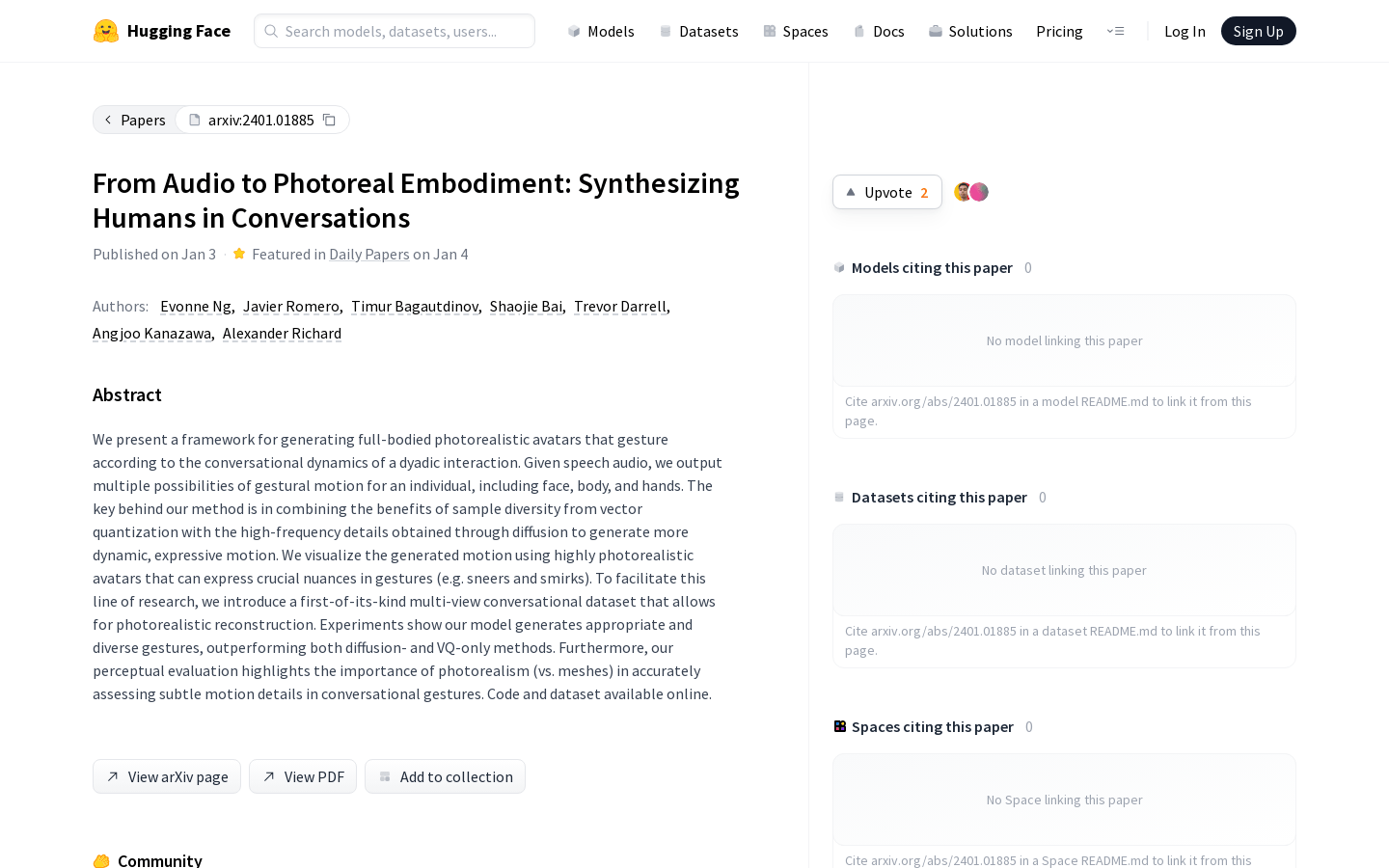
Audio to Photoreal Embodiment
Audio to Photoreal Embodiment是一个生成全身照片级人形化身的框架。它根据对话动态生成面部、身体和手部的多种姿势动作。其方法的关键在于通过将向量量化的样本多样性与扩散所获得的
AI爱好者的一站式人工智能AI工具箱,累计收录全球10,000⁺好用的AI工具软件和网站,方便您更便捷的探索前沿的AI技术。本站持续更新好的AI应用,力争做全球排名前三的AI网址导航网站,欢迎您成为我们的一员。
