收集全球10,000⁺个好用的AI软件
-
 Magenta StudioMagenta Studio是基于Magenta开源工具和模型构建的一组音乐插件。它使用前沿的机器学习技术进行音乐生成。Magenta Studio提...
Magenta StudioMagenta Studio是基于Magenta开源工具和模型构建的一组音乐插件。它使用前沿的机器学习技术进行音乐生成。Magenta Studio提... -
 PolymathPolymath利用机器学习将任何音乐库(例如来自硬盘或YouTube)转换为音乐制作样本库。该工具能自动将歌曲分割成节拍、贝斯等音轨部分,将它们量化...
PolymathPolymath利用机器学习将任何音乐库(例如来自硬盘或YouTube)转换为音乐制作样本库。该工具能自动将歌曲分割成节拍、贝斯等音轨部分,将它们量化... -
 Image to Music V2该应用通过先进的机器学习算法,将用户上传的图像转换为相应的音乐作品。适用于艺术家、创作者和音乐爱好者,为他们提供全新的创作工具。...
Image to Music V2该应用通过先进的机器学习算法,将用户上传的图像转换为相应的音乐作品。适用于艺术家、创作者和音乐爱好者,为他们提供全新的创作工具。... -
 Stable Audio Open 1.0Stable Audio Open 1.0是一个利用自编码器、基于T5的文本嵌入和基于变压器的扩散模型来生成长达47秒的立体声音频的AI模型。它通过文...
Stable Audio Open 1.0Stable Audio Open 1.0是一个利用自编码器、基于T5的文本嵌入和基于变压器的扩散模型来生成长达47秒的立体声音频的AI模型。它通过文... -
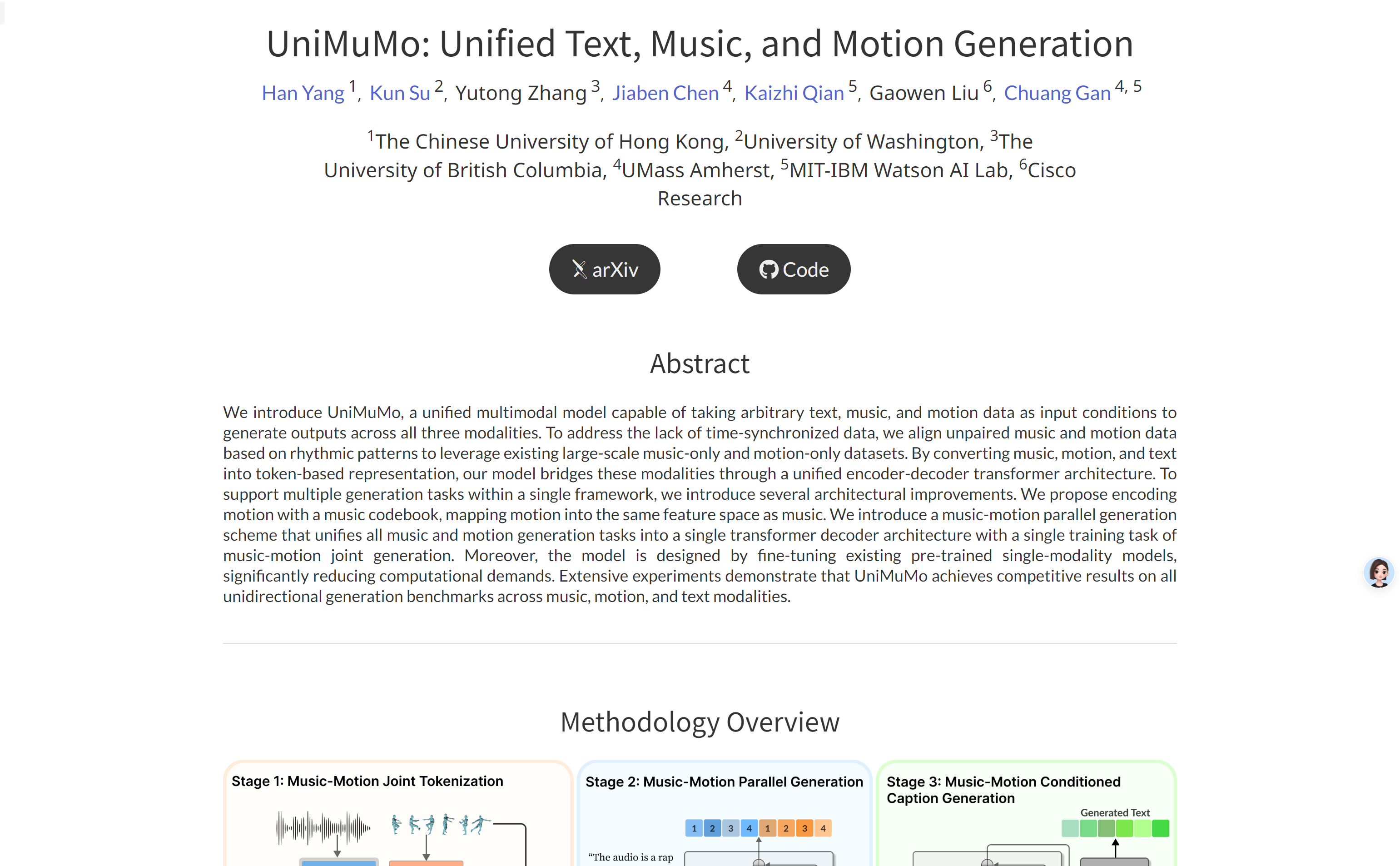 UniMuMoUniMuMo是一个多模态模型,能够将任意文本、音乐和动作数据作为输入条件,生成跨所有三种模态的输出。该模型通过将音乐、动作和文本转换为基于令牌的表示...
UniMuMoUniMuMo是一个多模态模型,能够将任意文本、音乐和动作数据作为输入条件,生成跨所有三种模态的输出。该模型通过将音乐、动作和文本转换为基于令牌的表示... -
 AMT-APCAMT-APC是一种通过微调自动音乐转录(AMT)模型来训练自动钢琴封面生成模型的方法。该模型使用Sony的hFT-Transformer作为基础AM...
AMT-APCAMT-APC是一种通过微调自动音乐转录(AMT)模型来训练自动钢琴封面生成模型的方法。该模型使用Sony的hFT-Transformer作为基础AM... -
PolymathPolymath利用机器学习将任何音乐库(例如来自硬盘或YouTube)转换为音乐制作样本库。该工具能自动将歌曲分割成节拍、贝斯等音轨部分,将它们量化...
-
Stable Audio Open 1.0Stable Audio Open 1.0是一个利用自编码器、基于T5的文本嵌入和基于变压器的扩散模型来生成长达47秒的立体声音频的AI模型。它通过文...
-
 音频提取文字工具AIbase音频提取文字工具利用人工智能技术,通过机器学习模型快速生成高质量的音频文本描述,优化文本排版,提升可读性,同时完全免费使用,无需安装、下载...
音频提取文字工具AIbase音频提取文字工具利用人工智能技术,通过机器学习模型快速生成高质量的音频文本描述,优化文本排版,提升可读性,同时完全免费使用,无需安装、下载... -
 LabelULabelU是一个开源的数据标注工具,适用于需要对图像、视频、音频等数据进行高效标注的场景,以提升机器学习模型的性能和质量。它支持多种标注类型,包括标...
LabelULabelU是一个开源的数据标注工具,适用于需要对图像、视频、音频等数据进行高效标注的场景,以提升机器学习模型的性能和质量。它支持多种标注类型,包括标... -
 seed-vcseed-vc 是一个基于 SEED-TTS 架构的声音转换模型,能够实现零样本的声音转换,即无需特定人的声音样本即可转换声音。该技术在音频质量和音色...
seed-vcseed-vc 是一个基于 SEED-TTS 架构的声音转换模型,能够实现零样本的声音转换,即无需特定人的声音样本即可转换声音。该技术在音频质量和音色... -
 SafeEarSafeEar是一个创新的音频深度检测框架,它能够在不依赖于语音内容的情况下检测深度音频。这个框架通过设计一个神经音频编解码器,将语义和声学信息从音频...
SafeEarSafeEar是一个创新的音频深度检测框架,它能够在不依赖于语音内容的情况下检测深度音频。这个框架通过设计一个神经音频编解码器,将语义和声学信息从音频... -
 DiariZenDiariZen是一个基于AudioZen和Pyannote 3.1驱动的说话人分割工具包。说话人分割是音频处理中的一个关键步骤,它能够将一段音频中的...
DiariZenDiariZen是一个基于AudioZen和Pyannote 3.1驱动的说话人分割工具包。说话人分割是音频处理中的一个关键步骤,它能够将一段音频中的... -
 NotebookLlamaNotebookLlama是一个开源项目,旨在通过一系列教程和笔记本指导用户构建从PDF到Podcast的工作流。该项目涵盖了从文本预处理到使用文本到...
NotebookLlamaNotebookLlama是一个开源项目,旨在通过一系列教程和笔记本指导用户构建从PDF到Podcast的工作流。该项目涵盖了从文本预处理到使用文本到... -
 TangoFluxTangoFlux是一个高效的文本到音频(TTA)生成模型,拥有515M参数,能够在单个A40 GPU上仅用3.7秒生成长达30秒的44.1kHz音频...
TangoFluxTangoFlux是一个高效的文本到音频(TTA)生成模型,拥有515M参数,能够在单个A40 GPU上仅用3.7秒生成长达30秒的44.1kHz音频... -
 Gemini 1.5 FlashGemini 1.5 Flash是Google DeepMind团队推出的最新AI模型,它通过蒸馏过程从更大的1.5 Pro模型中提炼出核心知识和技能...
Gemini 1.5 FlashGemini 1.5 Flash是Google DeepMind团队推出的最新AI模型,它通过蒸馏过程从更大的1.5 Pro模型中提炼出核心知识和技能... -
 bilibotbilibot是一个基于哔哩哔哩用户评论训练的本地聊天机器人,支持文字聊天和语音对话。它使用Qwen1.5-32B-Chat作为基础模型,并结合苹果的...
bilibotbilibot是一个基于哔哩哔哩用户评论训练的本地聊天机器人,支持文字聊天和语音对话。它使用Qwen1.5-32B-Chat作为基础模型,并结合苹果的... -
 sherpa-onnxsherpa-onnx 是一个基于下一代 Kaldi 的语音识别和语音合成项目,使用onnxruntime进行推理,支持多种语音相关功能,包括语音转文...
sherpa-onnxsherpa-onnx 是一个基于下一代 Kaldi 的语音识别和语音合成项目,使用onnxruntime进行推理,支持多种语音相关功能,包括语音转文... -
 CosyVoiceCosyVoice 是一个多语言的大型语音生成模型,它不仅支持多种语言的语音生成,还提供了从推理到训练再到部署的全栈能力。该模型在语音合成领域具有重要...
CosyVoiceCosyVoice 是一个多语言的大型语音生成模型,它不仅支持多种语言的语音生成,还提供了从推理到训练再到部署的全栈能力。该模型在语音合成领域具有重要... -
 aTrainaTrain是由格拉茨大学商业分析与数据科学中心的研究人员开发,并由格拉茨知识中心的研究人员测试的一款离线语音转录工具。它利用最新的机器学习模型,无需...
aTrainaTrain是由格拉茨大学商业分析与数据科学中心的研究人员开发,并由格拉茨知识中心的研究人员测试的一款离线语音转录工具。它利用最新的机器学习模型,无需...
AI爱好者的一站式人工智能AI工具箱,累计收录全球10,000⁺好用的AI工具软件和网站,方便您更便捷的探索前沿的AI技术。本站持续更新好的AI应用,力争做全球排名前三的AI网址导航网站,欢迎您成为我们的一员。
