收集全球10,000⁺个好用的AI软件
-
 ElevenLabs Text to Sound EffectsText to Sound Effects是ElevenLabs开发的最新AI音频模型,能够根据文本提示生成各种音效、短音乐曲目、音景和角色声音。它代...
ElevenLabs Text to Sound EffectsText to Sound Effects是ElevenLabs开发的最新AI音频模型,能够根据文本提示生成各种音效、短音乐曲目、音景和角色声音。它代... -
 Stable Audio OpenStable Audio Open是一个开源的文本到音频模型,专为生成短音频样本、音效和制作元素而优化。它允许用户通过简单的文本提示生成高达47秒的高...
Stable Audio OpenStable Audio Open是一个开源的文本到音频模型,专为生成短音频样本、音效和制作元素而优化。它允许用户通过简单的文本提示生成高达47秒的高... -
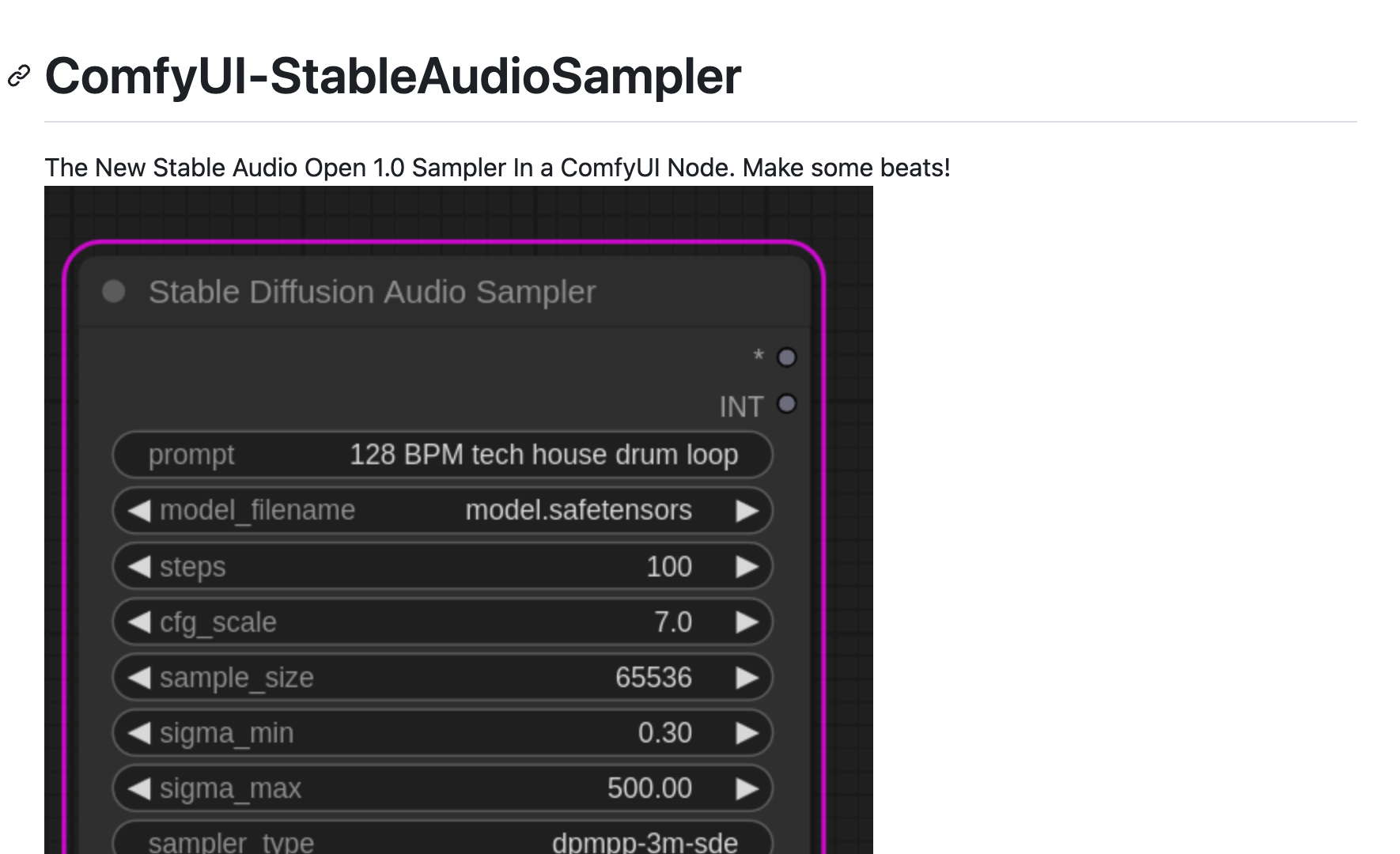 ComfyUI-StableAudioSamplerComfyUI-StableAudioSampler 是一款集成在 ComfyUI 节点中的音频采样器插件,它允许用户生成音频并输出原始字节和采样率,...
ComfyUI-StableAudioSamplerComfyUI-StableAudioSampler 是一款集成在 ComfyUI 节点中的音频采样器插件,它允许用户生成音频并输出原始字节和采样率,... -
 Stable Audio Open 1.0Stable Audio Open 1.0是一个利用自编码器、基于T5的文本嵌入和基于变压器的扩散模型来生成长达47秒的立体声音频的AI模型。它通过文...
Stable Audio Open 1.0Stable Audio Open 1.0是一个利用自编码器、基于T5的文本嵌入和基于变压器的扩散模型来生成长达47秒的立体声音频的AI模型。它通过文... -
 AudioLCMAudioLCM是一个基于PyTorch实现的文本到音频生成模型,它通过潜在一致性模型来生成高质量且高效的音频。该模型由Huadai Liu等人开发,...
AudioLCMAudioLCM是一个基于PyTorch实现的文本到音频生成模型,它通过潜在一致性模型来生成高质量且高效的音频。该模型由Huadai Liu等人开发,... -
 VideoLLaMA 2VideoLLaMA 2 是一个针对视频理解任务优化的大规模语言模型,它通过先进的空间-时间建模和音频理解能力,提升了对视频内容的解析和理解。该模型在...
VideoLLaMA 2VideoLLaMA 2 是一个针对视频理解任务优化的大规模语言模型,它通过先进的空间-时间建模和音频理解能力,提升了对视频内容的解析和理解。该模型在... -
 ElevenLabs 文本转音效APIElevenLabs的文本转音效API允许用户根据简短的文本描述生成高质量的音效,这些音效可以应用于游戏开发、音乐制作应用等多种场景。该API利用先进...
ElevenLabs 文本转音效APIElevenLabs的文本转音效API允许用户根据简短的文本描述生成高质量的音效,这些音效可以应用于游戏开发、音乐制作应用等多种场景。该API利用先进... -
 AudioSealAudioSeal 是一种用于AI生成语音音频的本地化水印技术,具有最先进的鲁棒性和极快的检测速度。它通过联合训练一个嵌入水印的生成器和一个检测器,即...
AudioSealAudioSeal 是一种用于AI生成语音音频的本地化水印技术,具有最先进的鲁棒性和极快的检测速度。它通过联合训练一个嵌入水印的生成器和一个检测器,即... -
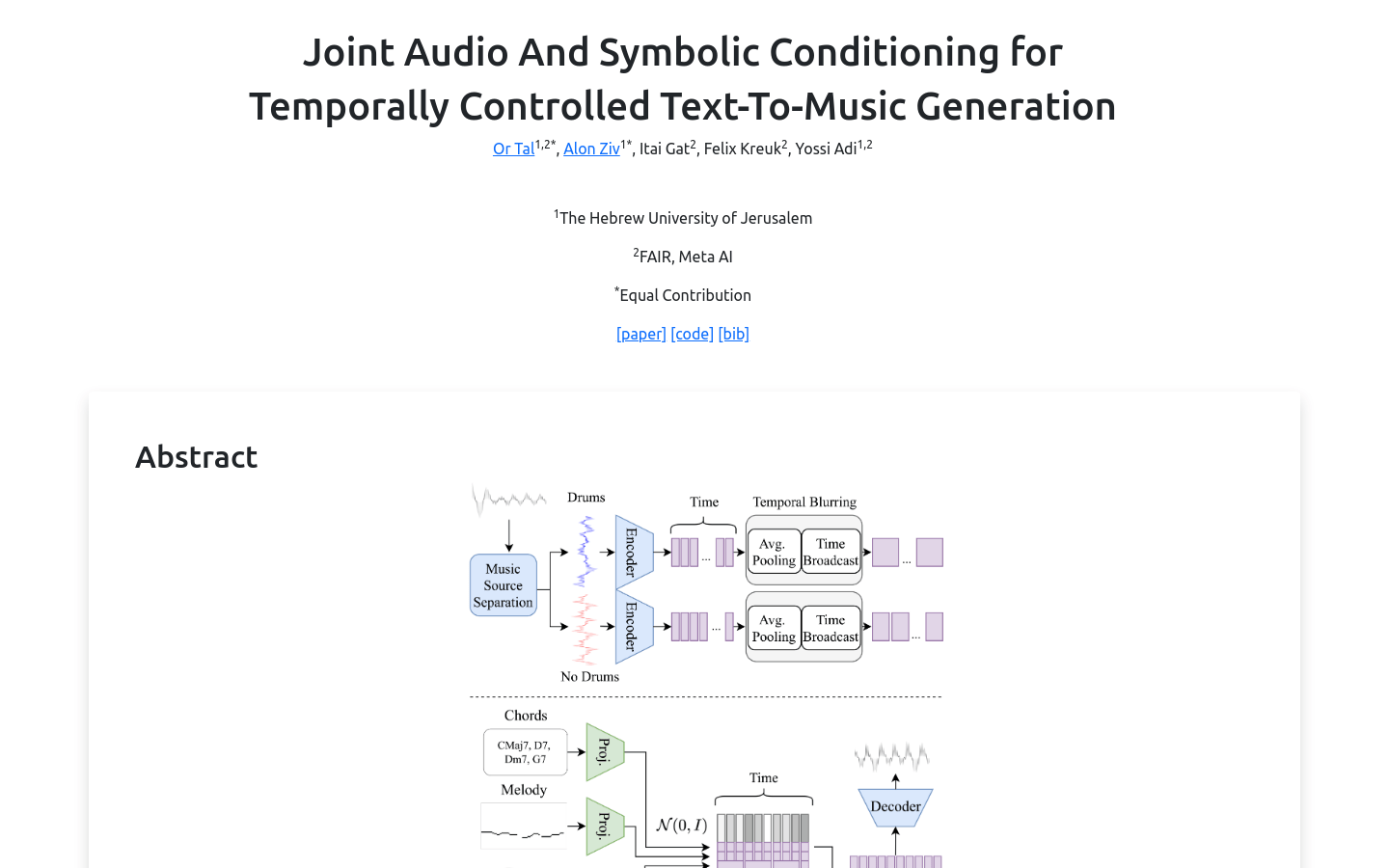 JASCOJASCO是一个结合了符号和基于音频的条件的文本到音乐生成模型,它能够根据全局文本描述和细粒度的局部控制生成高质量的音乐样本。JASCO基于流匹配建模...
JASCOJASCO是一个结合了符号和基于音频的条件的文本到音乐生成模型,它能够根据全局文本描述和细粒度的局部控制生成高质量的音乐样本。JASCO基于流匹配建模... -
 junejune是一个结合了Ollama、Hugging Face Transformers和Coqui TTS Toolkit的本地语音聊天机器人。它提供了...
junejune是一个结合了Ollama、Hugging Face Transformers和Coqui TTS Toolkit的本地语音聊天机器人。它提供了... -
 Resona V2AResona V2A是一款AI驱动的视频到音频生成技术产品,它能够仅通过视频数据自动生成与场景、动画或电影完美匹配的声音设计、效果、拟音和环境音。该技...
Resona V2AResona V2A是一款AI驱动的视频到音频生成技术产品,它能够仅通过视频数据自动生成与场景、动画或电影完美匹配的声音设计、效果、拟音和环境音。该技... -
 FoleyCrafterFoleyCrafter是一个基于文本的视频到音频生成框架,能够生成与输入视频语义相关且时间同步的高质量音频。该技术在视频制作领域具有重要意义,特别是...
FoleyCrafterFoleyCrafter是一个基于文本的视频到音频生成框架,能够生成与输入视频语义相关且时间同步的高质量音频。该技术在视频制作领域具有重要意义,特别是... -
 Voice IsolatorVoice Isolator 是 ElevenLabs 开发的一项 AI 音频解决方案,它能够从各种音频中提取出清晰的人声,去除街道噪音、麦克风反馈等...
Voice IsolatorVoice Isolator 是 ElevenLabs 开发的一项 AI 音频解决方案,它能够从各种音频中提取出清晰的人声,去除街道噪音、麦克风反馈等... -
 GenAUGenAU是一个由Snap Research开发的音频生成模型,它通过AutoCap自动字幕生成模型和GenAu音频生成架构,显著提升了音频生成的质量...
GenAUGenAU是一个由Snap Research开发的音频生成模型,它通过AutoCap自动字幕生成模型和GenAu音频生成架构,显著提升了音频生成的质量... -
 TTSynth.comTTSynth.com是一个免费的在线文本转语音(TTS)生成器,它使用先进的AI技术将书面文本转换为自然发音的语音。该服务支持多种语言和口音,适用于...
TTSynth.comTTSynth.com是一个免费的在线文本转语音(TTS)生成器,它使用先进的AI技术将书面文本转换为自然发音的语音。该服务支持多种语言和口音,适用于... -
 ReadsssReadsss是一个提供每日音频新闻简报的应用程序,用户可以订阅并收听来自他们喜爱的Twitter人物的更新。它利用音频形式让用户在忙碌的日程中保持信...
ReadsssReadsss是一个提供每日音频新闻简报的应用程序,用户可以订阅并收听来自他们喜爱的Twitter人物的更新。它利用音频形式让用户在忙碌的日程中保持信... -
 ManiWAVManiWAV是一个研究项目,旨在通过野外的音频和视觉数据学习机器人操控技能。它通过收集人类演示的同步音频和视觉反馈,并通过相应的策略接口直接从演示中...
ManiWAVManiWAV是一个研究项目,旨在通过野外的音频和视觉数据学习机器人操控技能。它通过收集人类演示的同步音频和视觉反馈,并通过相应的策略接口直接从演示中... -
 EchoMimicEchoMimic是一个先进的人像图像动画模型,能够通过音频和选定的面部特征点单独或组合驱动生成逼真的肖像视频。它通过新颖的训练策略,解决了传统方法在...
EchoMimicEchoMimic是一个先进的人像图像动画模型,能够通过音频和选定的面部特征点单独或组合驱动生成逼真的肖像视频。它通过新颖的训练策略,解决了传统方法在... -
 音频提取文字工具AIbase音频提取文字工具利用人工智能技术,通过机器学习模型快速生成高质量的音频文本描述,优化文本排版,提升可读性,同时完全免费使用,无需安装、下载...
音频提取文字工具AIbase音频提取文字工具利用人工智能技术,通过机器学习模型快速生成高质量的音频文本描述,优化文本排版,提升可读性,同时完全免费使用,无需安装、下载... -
 vta-ldmvta-ldm是一个专注于视频到音频生成的深度学习模型,能够根据视频内容生成语义和时间上与视频输入对齐的音频内容。它代表了视频生成领域的一个新突破,特...
vta-ldmvta-ldm是一个专注于视频到音频生成的深度学习模型,能够根据视频内容生成语义和时间上与视频输入对齐的音频内容。它代表了视频生成领域的一个新突破,特...
AI爱好者的一站式人工智能AI工具箱,累计收录全球10,000⁺好用的AI工具软件和网站,方便您更便捷的探索前沿的AI技术。本站持续更新好的AI应用,力争做全球排名前三的AI网址导航网站,欢迎您成为我们的一员。
