收集全球10,000⁺个好用的AI软件
-
 MusicLMMusicLM是一个模型,可以根据文本描述生成高保真音乐。它可以生成24kHz的音频,音乐风格和文本描述一致,并支持根据旋律进行条件生成。通过使用Mu...
MusicLMMusicLM是一个模型,可以根据文本描述生成高保真音乐。它可以生成24kHz的音频,音乐风格和文本描述一致,并支持根据旋律进行条件生成。通过使用Mu... -
 Stable Audio Open 1.0Stable Audio Open 1.0是一个利用自编码器、基于T5的文本嵌入和基于变压器的扩散模型来生成长达47秒的立体声音频的AI模型。它通过文...
Stable Audio Open 1.0Stable Audio Open 1.0是一个利用自编码器、基于T5的文本嵌入和基于变压器的扩散模型来生成长达47秒的立体声音频的AI模型。它通过文... -
 Stable Audio Open demoStable Audio Open 是一个能够从文本提示生成长达47秒的立体声音频的技术。它包含三个主要组件:一个将波形压缩到可管理序列长度的自编码器...
Stable Audio Open demoStable Audio Open 是一个能够从文本提示生成长达47秒的立体声音频的技术。它包含三个主要组件:一个将波形压缩到可管理序列长度的自编码器... -
 Sketch2SoundSketch2Sound是一个生成音频的模型,能够从一组可解释的时间变化控制信号(响度、亮度、音高)以及文本提示中创建高质量的声音。该模型能够在任何文...
Sketch2SoundSketch2Sound是一个生成音频的模型,能够从一组可解释的时间变化控制信号(响度、亮度、音高)以及文本提示中创建高质量的声音。该模型能够在任何文... -
MusicLMMusicLM是一个模型,可以根据文本描述生成高保真音乐。它可以生成24kHz的音频,音乐风格和文本描述一致,并支持根据旋律进行条件生成。通过使用Mu...
-
 Make-An-Audio 2Make-An-Audio 2是一种基于扩散模型的文本到音频生成技术,由浙江大学、字节跳动和香港中文大学的研究人员共同开发。该技术通过使用预训练的大型...
Make-An-Audio 2Make-An-Audio 2是一种基于扩散模型的文本到音频生成技术,由浙江大学、字节跳动和香港中文大学的研究人员共同开发。该技术通过使用预训练的大型... -
Stable Audio Open 1.0Stable Audio Open 1.0是一个利用自编码器、基于T5的文本嵌入和基于变压器的扩散模型来生成长达47秒的立体声音频的AI模型。它通过文...
-
 AudioLCMAudioLCM是一个基于PyTorch实现的文本到音频生成模型,它通过潜在一致性模型来生成高质量且高效的音频。该模型由Huadai Liu等人开发,...
AudioLCMAudioLCM是一个基于PyTorch实现的文本到音频生成模型,它通过潜在一致性模型来生成高质量且高效的音频。该模型由Huadai Liu等人开发,... -
Stable Audio Open demoStable Audio Open 是一个能够从文本提示生成长达47秒的立体声音频的技术。它包含三个主要组件:一个将波形压缩到可管理序列长度的自编码器...
-
 BarkBark是由Suno开发的基于Transformer的文本到音频模型,能够生成逼真的多语言语音以及其他类型的音频,如音乐、背景噪声和简单音效。它还支持...
BarkBark是由Suno开发的基于Transformer的文本到音频模型,能够生成逼真的多语言语音以及其他类型的音频,如音乐、背景噪声和简单音效。它还支持... -
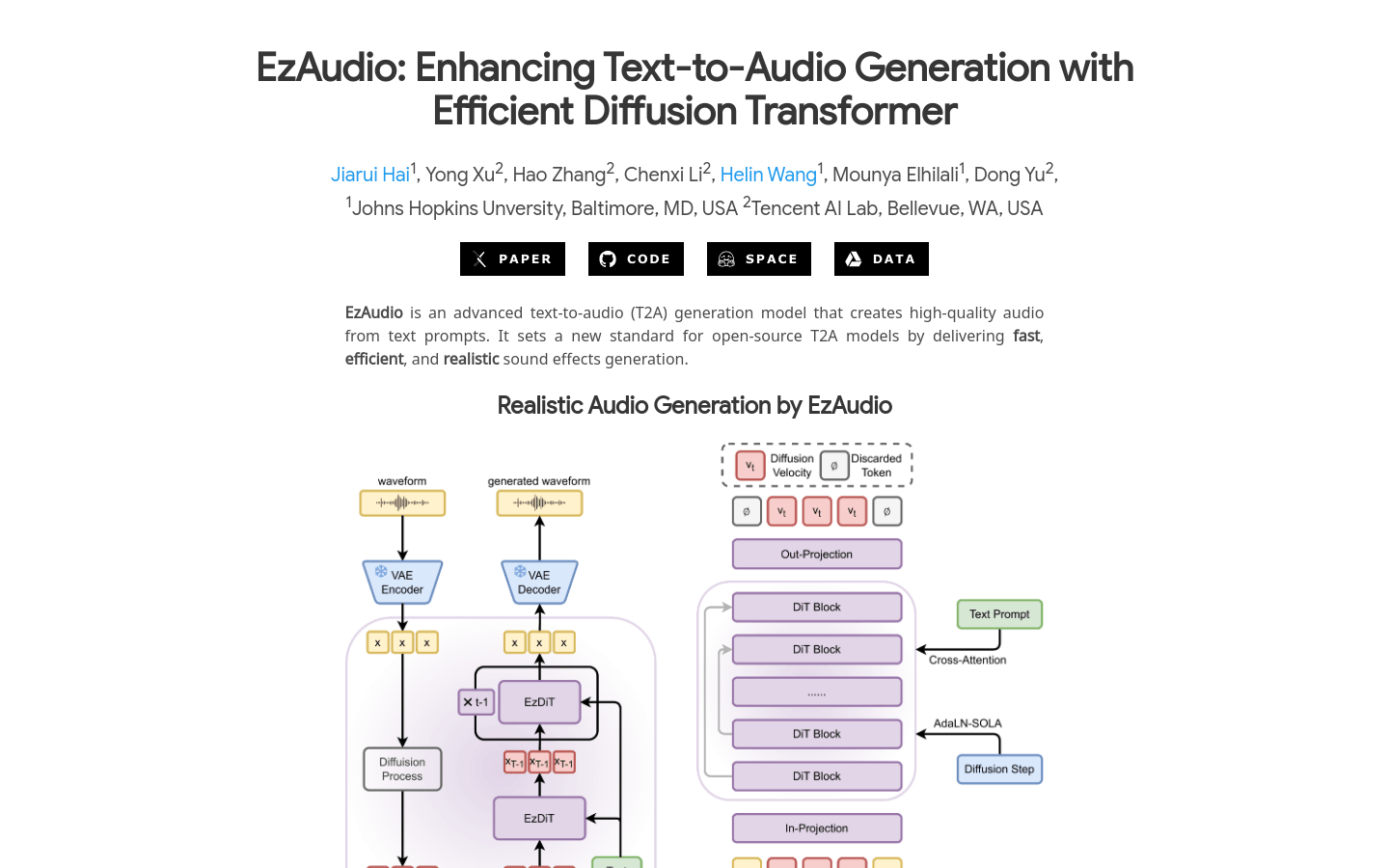 EzAudioEzAudio是一个先进的文本到音频(T2A)生成模型,它能够从文本提示中创建高质量的音频。它为开源T2A模型设定了新的标准,提供快速、高效和逼真的声...
EzAudioEzAudio是一个先进的文本到音频(T2A)生成模型,它能够从文本提示中创建高质量的音频。它为开源T2A模型设定了新的标准,提供快速、高效和逼真的声... -
Sketch2SoundSketch2Sound是一个生成音频的模型,能够从一组可解释的时间变化控制信号(响度、亮度、音高)以及文本提示中创建高质量的声音。该模型能够在任何文...
-
 TangoFluxTangoFlux是一个高效的文本到音频(TTA)生成模型,拥有515M参数,能够在单个A40 GPU上仅用3.7秒生成长达30秒的44.1kHz音频...
TangoFluxTangoFlux是一个高效的文本到音频(TTA)生成模型,拥有515M参数,能够在单个A40 GPU上仅用3.7秒生成长达30秒的44.1kHz音频... -
AudioLCMAudioLCM是一个基于PyTorch实现的文本到音频生成模型,它通过潜在一致性模型来生成高质量且高效的音频。该模型由Huadai Liu等人开发,...
AI爱好者的一站式人工智能AI工具箱,累计收录全球10,000⁺好用的AI工具软件和网站,方便您更便捷的探索前沿的AI技术。本站持续更新好的AI应用,力争做全球排名前三的AI网址导航网站,欢迎您成为我们的一员。
