收集全球10,000⁺个好用的AI软件
-
 VideoReTalkingVideoReTalking是一个新的系统,可以根据输入的音频编辑真实世界的说话头部视频的面部,产生高质量的唇形同步输出视频,即使情感不同。该系统将此...
VideoReTalkingVideoReTalking是一个新的系统,可以根据输入的音频编辑真实世界的说话头部视频的面部,产生高质量的唇形同步输出视频,即使情感不同。该系统将此... -
 VividTalkVividTalk是一种一次性音频驱动的头像生成技术,基于3D混合先验。它能够生成具有表情丰富、自然头部姿态和唇同步的逼真说唱视频。该技术采用了两阶段...
VividTalkVividTalk是一种一次性音频驱动的头像生成技术,基于3D混合先验。它能够生成具有表情丰富、自然头部姿态和唇同步的逼真说唱视频。该技术采用了两阶段... -
 AniPortraitAniPortrait是一个根据音频和图像输入生成会说话、唱歌的动态视频的项目。它能够根据音频和静态人脸图片生成逼真的人脸动画,口型保持一致。支持多种...
AniPortraitAniPortrait是一个根据音频和图像输入生成会说话、唱歌的动态视频的项目。它能够根据音频和静态人脸图片生成逼真的人脸动画,口型保持一致。支持多种... -
 EchoMimicEchoMimic是一个先进的人像图像动画模型,能够通过音频和选定的面部特征点单独或组合驱动生成逼真的肖像视频。它通过新颖的训练策略,解决了传统方法在...
EchoMimicEchoMimic是一个先进的人像图像动画模型,能够通过音频和选定的面部特征点单独或组合驱动生成逼真的肖像视频。它通过新颖的训练策略,解决了传统方法在... -
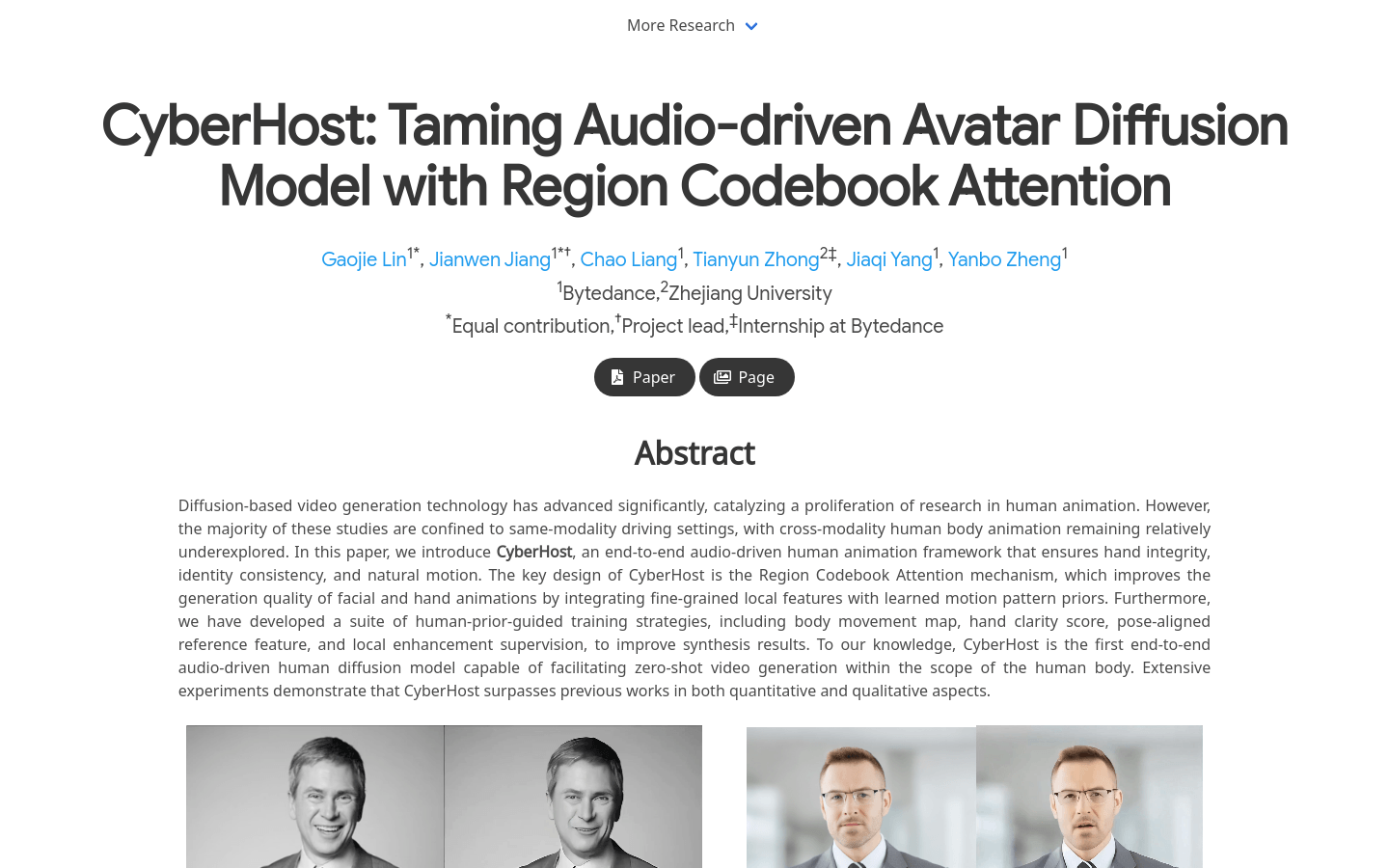 CyberHostCyberHost是一个端到端音频驱动的人体动画框架,通过区域码本注意力机制,实现了手部完整性、身份一致性和自然运动的生成。该模型利用双U-Net架构...
CyberHostCyberHost是一个端到端音频驱动的人体动画框架,通过区域码本注意力机制,实现了手部完整性、身份一致性和自然运动的生成。该模型利用双U-Net架构... -
 Loopy modelLoopy是一个端到端的音频驱动视频扩散模型,专门设计了跨剪辑和内部剪辑的时间模块以及音频到潜在表示模块,使模型能够利用数据中的长期运动信息来学习自然...
Loopy modelLoopy是一个端到端的音频驱动视频扩散模型,专门设计了跨剪辑和内部剪辑的时间模块以及音频到潜在表示模块,使模型能够利用数据中的长期运动信息来学习自然... -
 Hallo2Hallo2是一种基于潜在扩散生成模型的人像图像动画技术,通过音频驱动生成高分辨率、长时的视频。它通过引入多项设计改进,扩展了Hallo的功能,包括生...
Hallo2Hallo2是一种基于潜在扩散生成模型的人像图像动画技术,通过音频驱动生成高分辨率、长时的视频。它通过引入多项设计改进,扩展了Hallo的功能,包括生... -
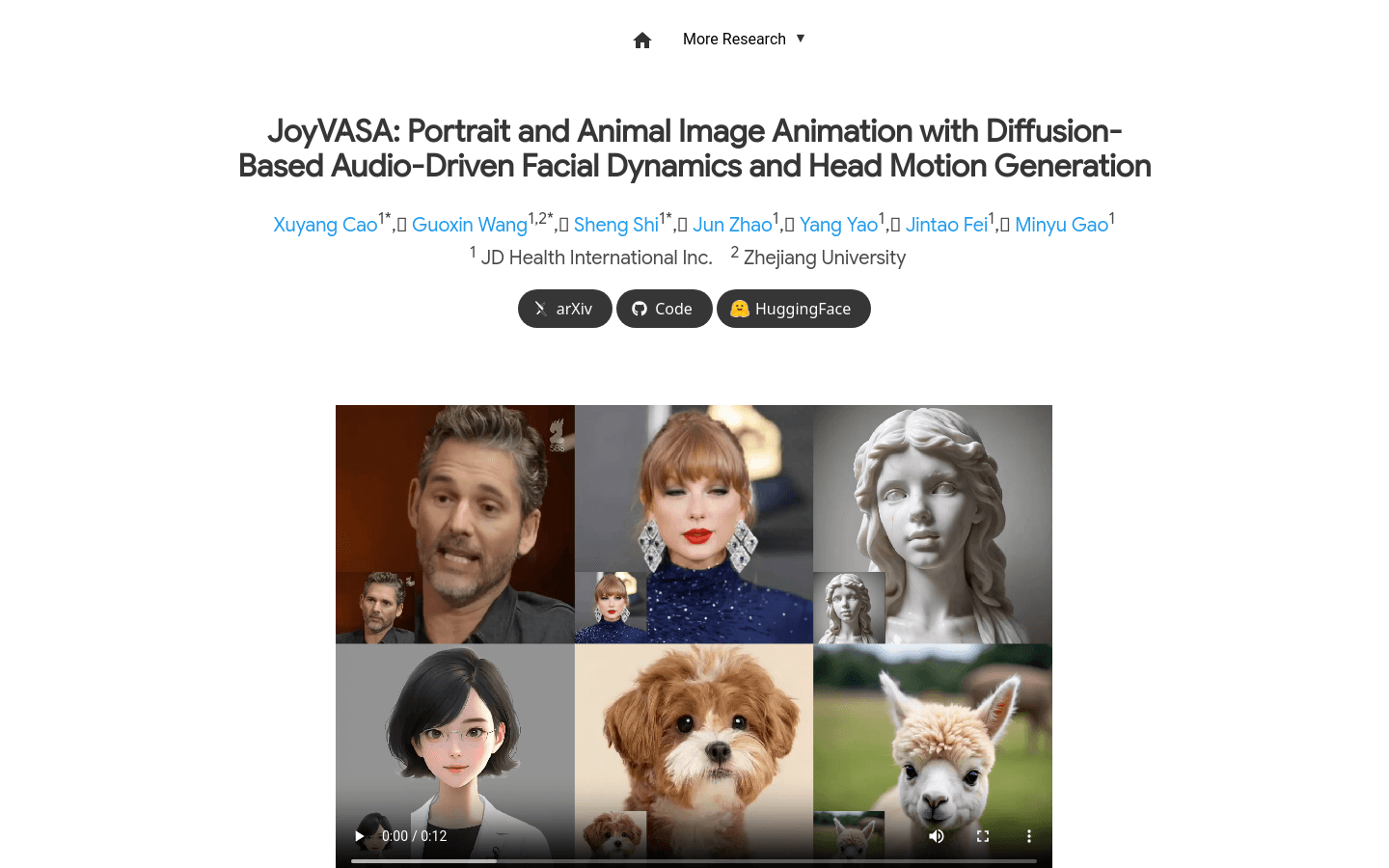 JoyVASAJoyVASA是一种基于扩散模型的音频驱动人像动画技术,它通过分离动态面部表情和静态3D面部表示来生成面部动态和头部运动。这项技术不仅能够提高视频质量...
JoyVASAJoyVASA是一种基于扩散模型的音频驱动人像动画技术,它通过分离动态面部表情和静态3D面部表示来生成面部动态和头部运动。这项技术不仅能够提高视频质量... -
 EchoMimicV2EchoMimicV2是由支付宝蚂蚁集团终端技术部研发的半身人体动画技术,它通过参考图像、音频剪辑和一系列手势来生成高质量的动画视频,确保音频内容与半...
EchoMimicV2EchoMimicV2是由支付宝蚂蚁集团终端技术部研发的半身人体动画技术,它通过参考图像、音频剪辑和一系列手势来生成高质量的动画视频,确保音频内容与半... -
 FLOATFLOAT是一种音频驱动的人像视频生成方法,它基于流匹配生成模型,将生成建模从基于像素的潜在空间转移到学习到的运动潜在空间,实现了时间上一致的运动设计...
FLOATFLOAT是一种音频驱动的人像视频生成方法,它基于流匹配生成模型,将生成建模从基于像素的潜在空间转移到学习到的运动潜在空间,实现了时间上一致的运动设计... -
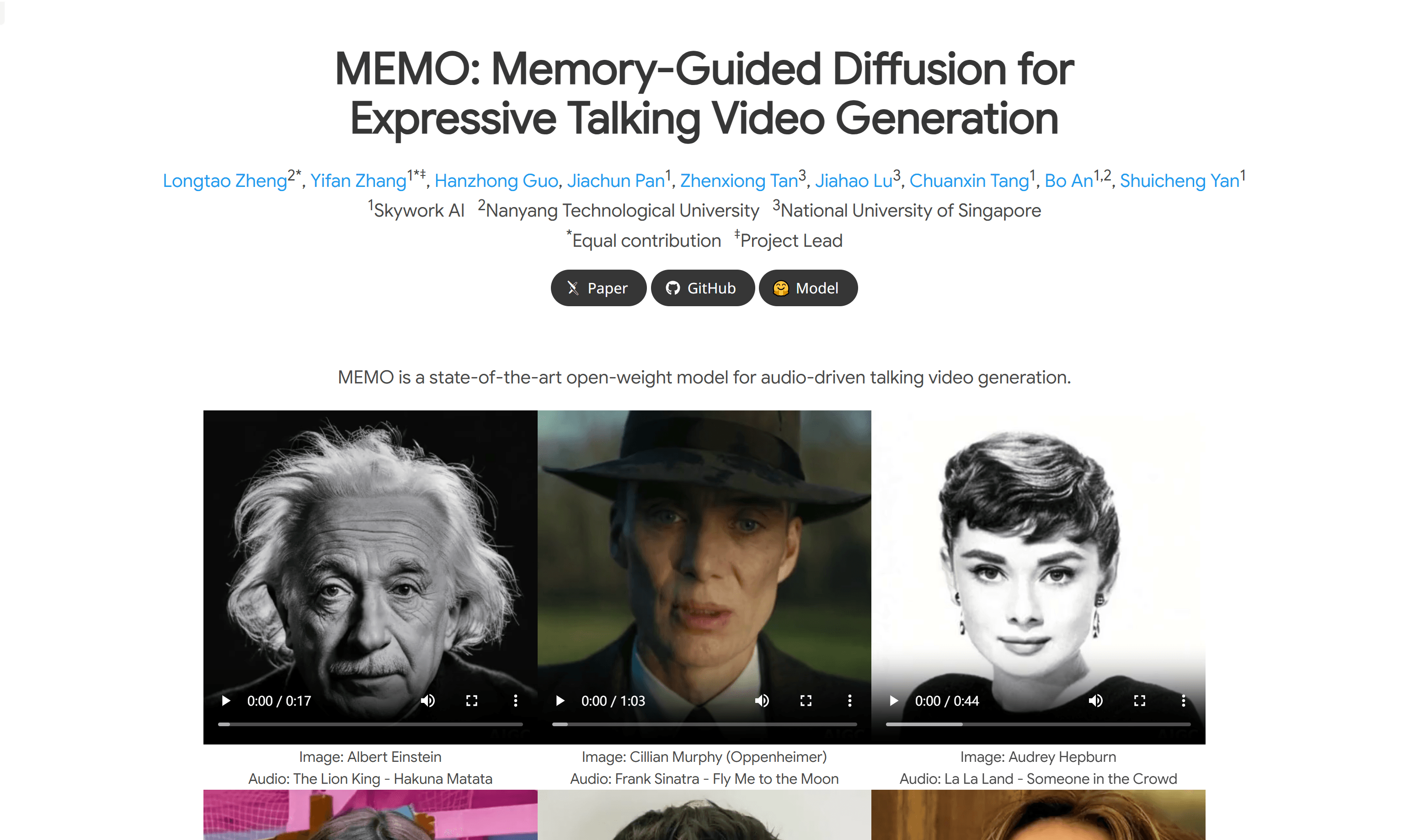 MEMOMEMO是一个先进的开放权重模型,用于音频驱动的说话视频生成。该模型通过记忆引导的时间模块和情感感知的音频模块,增强了长期身份一致性和运动平滑性,同时...
MEMOMEMO是一个先进的开放权重模型,用于音频驱动的说话视频生成。该模型通过记忆引导的时间模块和情感感知的音频模块,增强了长期身份一致性和运动平滑性,同时... -
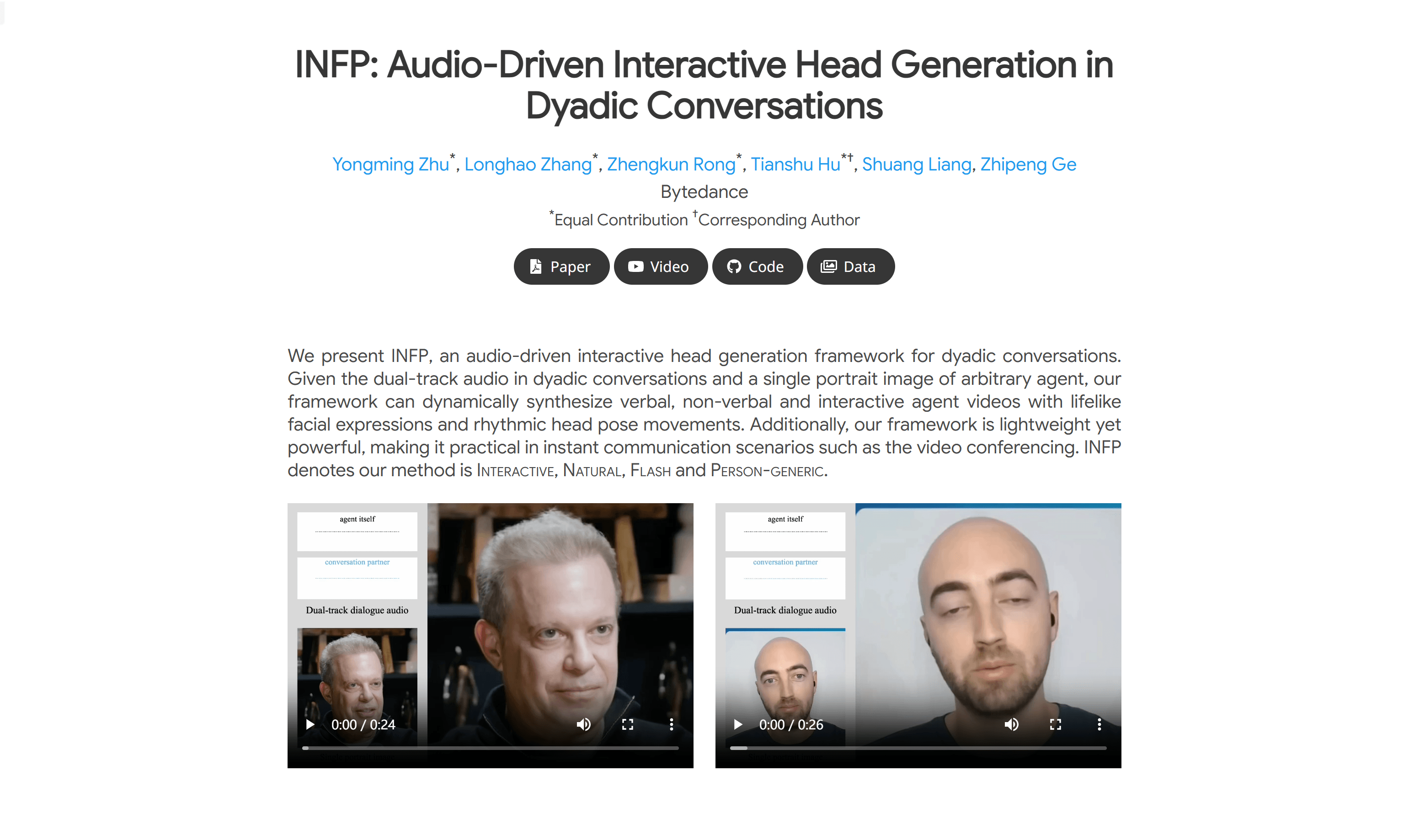 INFPINFP是一个音频驱动的交互式头部生成框架,专为双人对话设计。它可以根据双人对话中的双轨音频和一个任意代理的单人肖像图像动态合成具有逼真面部表情和节奏...
INFPINFP是一个音频驱动的交互式头部生成框架,专为双人对话设计。它可以根据双人对话中的双轨音频和一个任意代理的单人肖像图像动态合成具有逼真面部表情和节奏... -
 SyncAnimationSyncAnimation 是一种创新的音频驱动技术,能够实时生成高度逼真的说话头像和上半身动作。它通过结合音频与姿态、表情的同步技术,解决了传统方法...
SyncAnimationSyncAnimation 是一种创新的音频驱动技术,能够实时生成高度逼真的说话头像和上半身动作。它通过结合音频与姿态、表情的同步技术,解决了传统方法... -
 LiteAvatarLiteAvatar是一个音频驱动的实时2D头像生成模型,主要用于实时聊天场景。该模型通过高效的语音识别和嘴型参数预测技术,结合轻量级的2D人脸生成模...
LiteAvatarLiteAvatar是一个音频驱动的实时2D头像生成模型,主要用于实时聊天场景。该模型通过高效的语音识别和嘴型参数预测技术,结合轻量级的2D人脸生成模... -
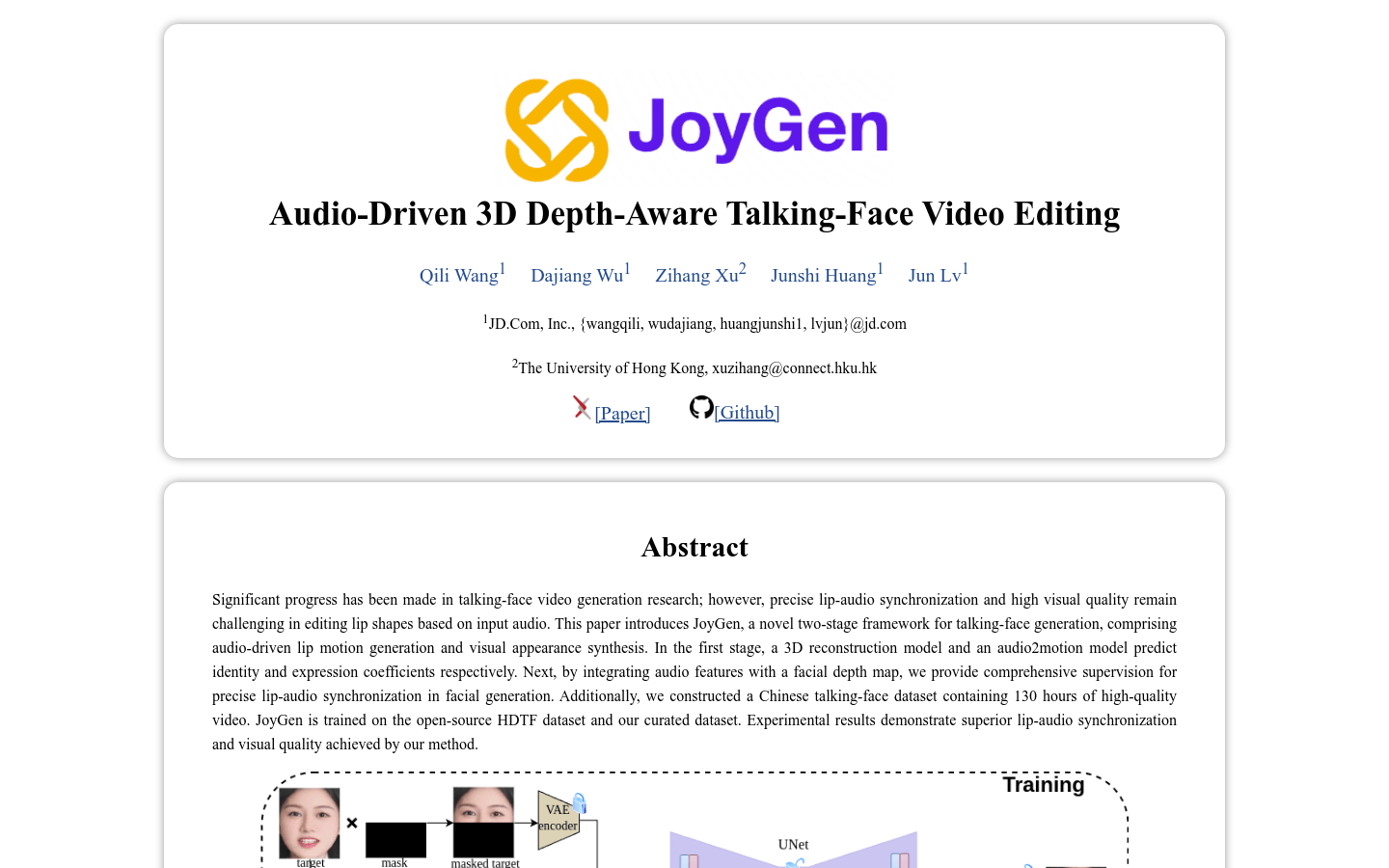 JoyGenJoyGen 是一种创新的音频驱动 3D 深度感知说话人脸视频生成技术。它通过音频驱动唇部动作生成和视觉外观合成,解决了传统技术中唇部与音频不同步和视...
JoyGenJoyGen 是一种创新的音频驱动 3D 深度感知说话人脸视频生成技术。它通过音频驱动唇部动作生成和视觉外观合成,解决了传统技术中唇部与音频不同步和视...
AI爱好者的一站式人工智能AI工具箱,累计收录全球10,000⁺好用的AI工具软件和网站,方便您更便捷的探索前沿的AI技术。本站持续更新好的AI应用,力争做全球排名前三的AI网址导航网站,欢迎您成为我们的一员。
