收集全球10,000⁺个好用的AI软件
-
 ragobbleragobble是一个利用人工智能将音频文件转换为文档的平台。通过将在线视频和音频信息转换为可向量化的RAG文档,用户可以将生成的文档应用于其LLM实...
ragobbleragobble是一个利用人工智能将音频文件转换为文档的平台。通过将在线视频和音频信息转换为可向量化的RAG文档,用户可以将生成的文档应用于其LLM实... -
 Make-An-Audio 2Make-An-Audio 2是一种基于扩散模型的文本到音频生成技术,由浙江大学、字节跳动和香港中文大学的研究人员共同开发。该技术通过使用预训练的大型...
Make-An-Audio 2Make-An-Audio 2是一种基于扩散模型的文本到音频生成技术,由浙江大学、字节跳动和香港中文大学的研究人员共同开发。该技术通过使用预训练的大型... -
 ElevenLabs Text to Sound EffectsText to Sound Effects是ElevenLabs开发的最新AI音频模型,能够根据文本提示生成各种音效、短音乐曲目、音景和角色声音。它代...
ElevenLabs Text to Sound EffectsText to Sound Effects是ElevenLabs开发的最新AI音频模型,能够根据文本提示生成各种音效、短音乐曲目、音景和角色声音。它代... -
 Stable Audio OpenStable Audio Open是一个开源的文本到音频模型,专为生成短音频样本、音效和制作元素而优化。它允许用户通过简单的文本提示生成高达47秒的高...
Stable Audio OpenStable Audio Open是一个开源的文本到音频模型,专为生成短音频样本、音效和制作元素而优化。它允许用户通过简单的文本提示生成高达47秒的高... -
 VideoLLaMA 2VideoLLaMA 2 是一个针对视频理解任务优化的大规模语言模型,它通过先进的空间-时间建模和音频理解能力,提升了对视频内容的解析和理解。该模型在...
VideoLLaMA 2VideoLLaMA 2 是一个针对视频理解任务优化的大规模语言模型,它通过先进的空间-时间建模和音频理解能力,提升了对视频内容的解析和理解。该模型在... -
 GenAUGenAU是一个由Snap Research开发的音频生成模型,它通过AutoCap自动字幕生成模型和GenAu音频生成架构,显著提升了音频生成的质量...
GenAUGenAU是一个由Snap Research开发的音频生成模型,它通过AutoCap自动字幕生成模型和GenAu音频生成架构,显著提升了音频生成的质量... -
 Qwen2-AudioQwen2-Audio是由阿里云提出的大型音频语言模型,能够接受各种音频信号输入,并根据语音指令进行音频分析或直接文本回复。该模型支持两种不同的音频交...
Qwen2-AudioQwen2-Audio是由阿里云提出的大型音频语言模型,能够接受各种音频信号输入,并根据语音指令进行音频分析或直接文本回复。该模型支持两种不同的音频交... -
 MaskVATMaskVAT是一种视频到音频(V2A)生成模型,它利用视频的视觉特征来生成与场景匹配的逼真声音。该模型特别强调声音的起始点与视觉动作的同步性,以避免...
MaskVATMaskVAT是一种视频到音频(V2A)生成模型,它利用视频的视觉特征来生成与场景匹配的逼真声音。该模型特别强调声音的起始点与视觉动作的同步性,以避免... -
 Easy Voice ToolkitEasy Voice Toolkit是一个基于开源语音项目的AI语音工具箱,提供包括语音模型训练在内的多种自动化音频工具。该工具箱能够无缝集成,形成完...
Easy Voice ToolkitEasy Voice Toolkit是一个基于开源语音项目的AI语音工具箱,提供包括语音模型训练在内的多种自动化音频工具。该工具箱能够无缝集成,形成完... -
 CyberHostCyberHost是一个端到端音频驱动的人体动画框架,通过区域码本注意力机制,实现了手部完整性、身份一致性和自然运动的生成。该模型利用双U-Net架构...
CyberHostCyberHost是一个端到端音频驱动的人体动画框架,通过区域码本注意力机制,实现了手部完整性、身份一致性和自然运动的生成。该模型利用双U-Net架构... -
 Stability AIStability AI是一个专注于生成式人工智能技术的公司,提供多种AI模型,包括文本到图像、视频、音频、3D和语言模型。这些模型能够处理复杂提示,...
Stability AIStability AI是一个专注于生成式人工智能技术的公司,提供多种AI模型,包括文本到图像、视频、音频、3D和语言模型。这些模型能够处理复杂提示,... -
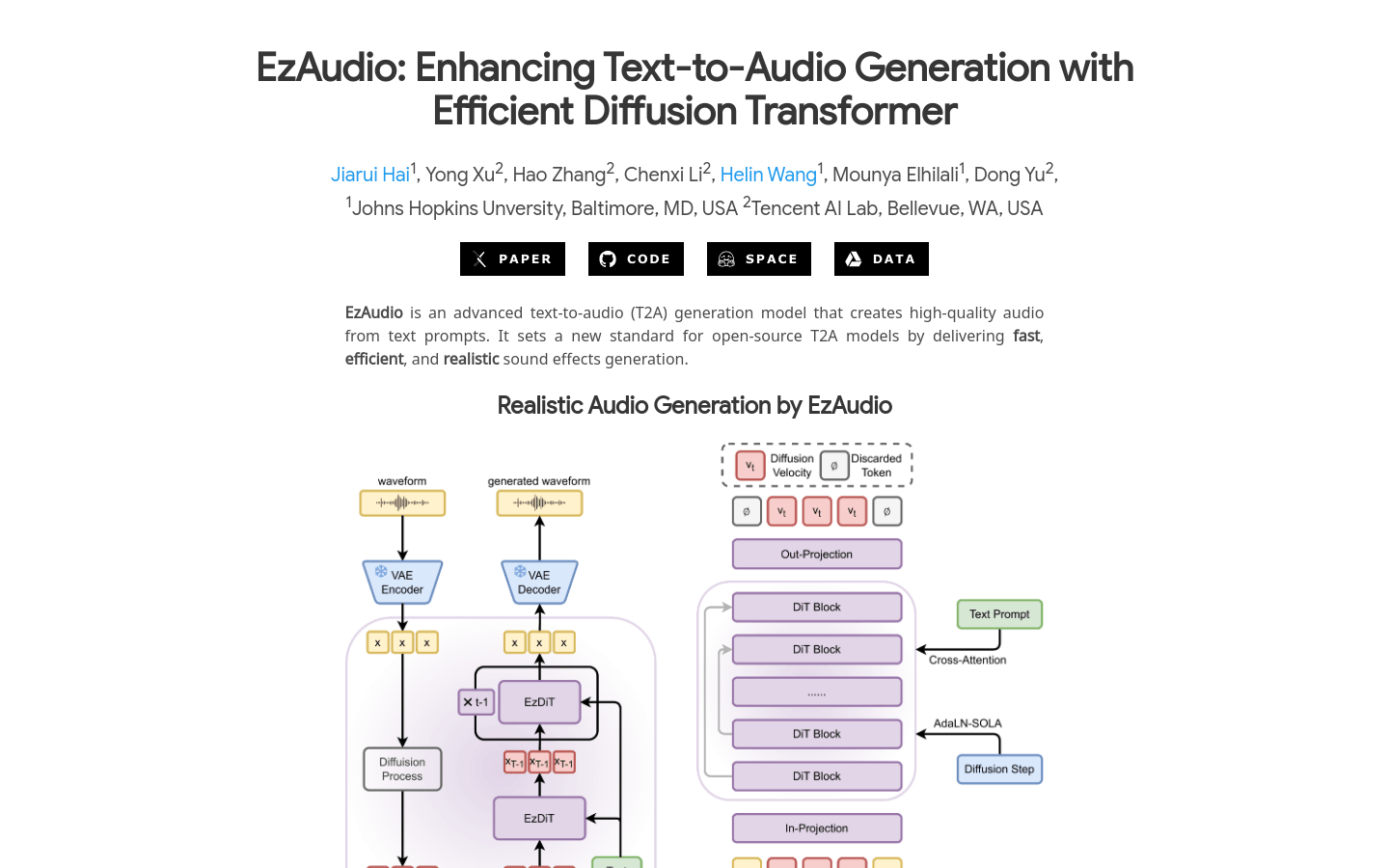 EzAudioEzAudio是一个先进的文本到音频(T2A)生成模型,它能够从文本提示中创建高质量的音频。它为开源T2A模型设定了新的标准,提供快速、高效和逼真的声...
EzAudioEzAudio是一个先进的文本到音频(T2A)生成模型,它能够从文本提示中创建高质量的音频。它为开源T2A模型设定了新的标准,提供快速、高效和逼真的声... -
 AudioLMAudioLM是由Google Research开发的一个框架,用于高质量音频生成,具有长期一致性。它将输入音频映射到离散标记序列,并将音频生成视为这...
AudioLMAudioLM是由Google Research开发的一个框架,用于高质量音频生成,具有长期一致性。它将输入音频映射到离散标记序列,并将音频生成视为这... -
 Universal-2Universal-2是AssemblyAI推出的最新语音识别模型,它在准确度和精确度上超越了前一代Universal-1,能够更好地捕捉人类语言的复...
Universal-2Universal-2是AssemblyAI推出的最新语音识别模型,它在准确度和精确度上超越了前一代Universal-1,能够更好地捕捉人类语言的复... -
 hertz-devhertz-dev是Standard Intelligence开源的全双工、仅音频的变换器基础模型,拥有85亿参数。该模型代表了可扩展的跨模态学习技术...
hertz-devhertz-dev是Standard Intelligence开源的全双工、仅音频的变换器基础模型,拥有85亿参数。该模型代表了可扩展的跨模态学习技术... -
 OuteTTS-0.1-350MOuteTTS-0.1-350M是一款基于纯语言模型的文本到语音合成技术,它不需要外部适配器或复杂架构,通过精心设计的提示和音频标记实现高质量的语音合...
OuteTTS-0.1-350MOuteTTS-0.1-350M是一款基于纯语言模型的文本到语音合成技术,它不需要外部适配器或复杂架构,通过精心设计的提示和音频标记实现高质量的语音合... -
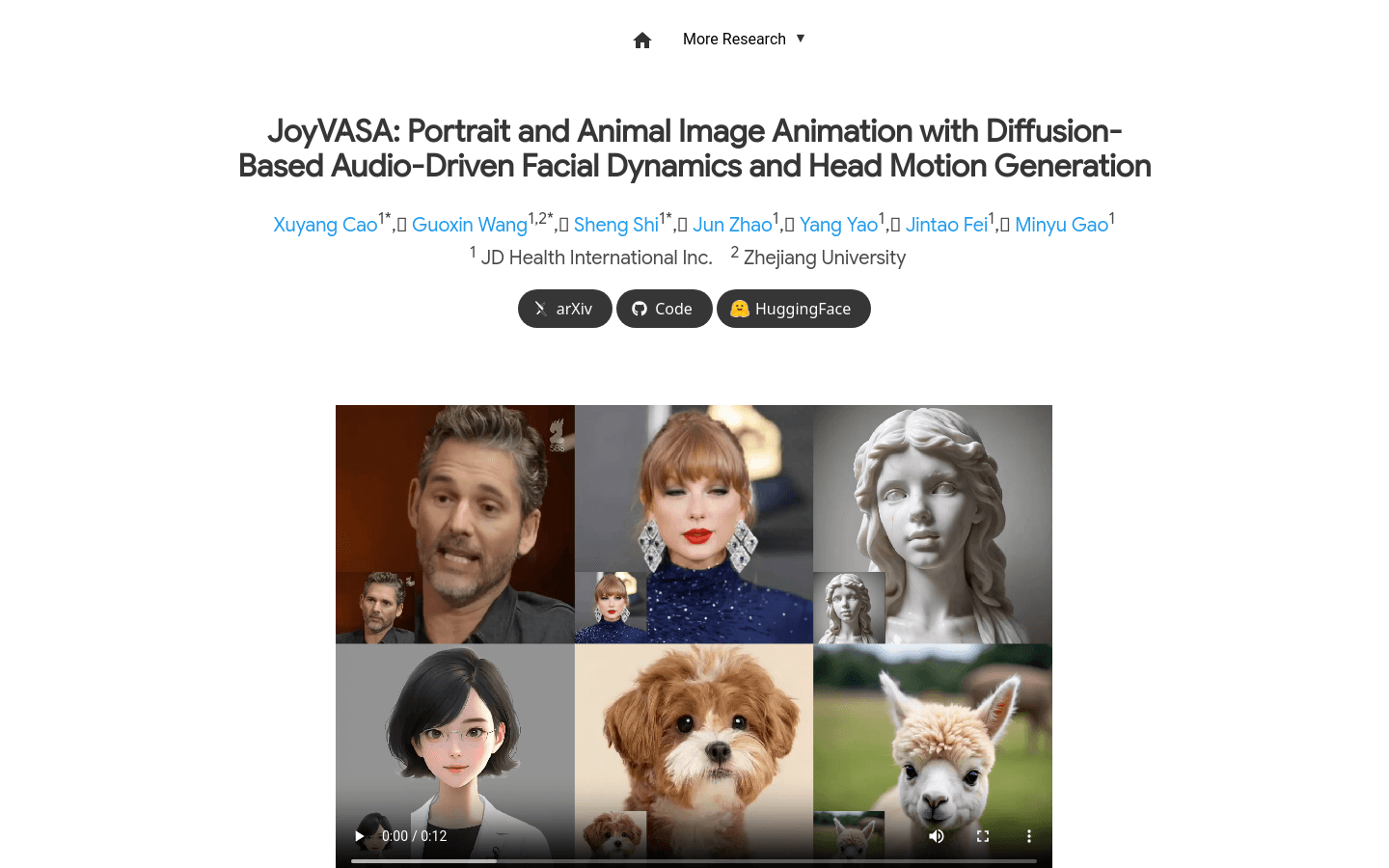 JoyVASAJoyVASA是一种基于扩散模型的音频驱动人像动画技术,它通过分离动态面部表情和静态3D面部表示来生成面部动态和头部运动。这项技术不仅能够提高视频质量...
JoyVASAJoyVASA是一种基于扩散模型的音频驱动人像动画技术,它通过分离动态面部表情和静态3D面部表示来生成面部动态和头部运动。这项技术不仅能够提高视频质量... -
 FugattoFugatto(全称Foundational Generative Audio Transformer Opus 1)是由NVIDIA推出的一款生成式...
FugattoFugatto(全称Foundational Generative Audio Transformer Opus 1)是由NVIDIA推出的一款生成式... -
 OmniAudio-2.6BOmniAudio-2.6B是一个2.6B参数的多模态模型,能够无缝处理文本和音频输入。该模型结合了Gemma-2B、Whisper turbo和一个...
OmniAudio-2.6BOmniAudio-2.6B是一个2.6B参数的多模态模型,能够无缝处理文本和音频输入。该模型结合了Gemma-2B、Whisper turbo和一个... -
 MILSMILS是一个由Facebook Research发布的开源项目,旨在展示大型语言模型(LLMs)在未经过任何训练的情况下,能够处理视觉和听觉任务的能...
MILSMILS是一个由Facebook Research发布的开源项目,旨在展示大型语言模型(LLMs)在未经过任何训练的情况下,能够处理视觉和听觉任务的能...
AI爱好者的一站式人工智能AI工具箱,累计收录全球10,000⁺好用的AI工具软件和网站,方便您更便捷的探索前沿的AI技术。本站持续更新好的AI应用,力争做全球排名前三的AI网址导航网站,欢迎您成为我们的一员。
