收集全球10,000⁺个好用的AI软件
-
 podscriptPodscript 是一个强大的音频转录工具,它利用语言模型和语音到文本(STT)API,为播客和其他音频内容生成高质量的转录文本。该工具支持多种流行...
podscriptPodscript 是一个强大的音频转录工具,它利用语言模型和语音到文本(STT)API,为播客和其他音频内容生成高质量的转录文本。该工具支持多种流行... -
 LiteAvatarLiteAvatar是一个音频驱动的实时2D头像生成模型,主要用于实时聊天场景。该模型通过高效的语音识别和嘴型参数预测技术,结合轻量级的2D人脸生成模...
LiteAvatarLiteAvatar是一个音频驱动的实时2D头像生成模型,主要用于实时聊天场景。该模型通过高效的语音识别和嘴型参数预测技术,结合轻量级的2D人脸生成模... -
 summymonkeySummyMonkey是一个智能的信息处理工具,它可以通过语音转文字、邮件汇总和聊天模式提供关键信息洞察,大幅提高工作效率。这个产品采用语音转文字技术...
summymonkeySummyMonkey是一个智能的信息处理工具,它可以通过语音转文字、邮件汇总和聊天模式提供关键信息洞察,大幅提高工作效率。这个产品采用语音转文字技术... -
 StyleTTS 2StyleTTS 2 是一款文本转语音(TTS)模型,使用大型语音语言模型(SLMs)进行风格扩散和对抗训练,实现了人级别的 TTS 合成。它通过扩散...
StyleTTS 2StyleTTS 2 是一款文本转语音(TTS)模型,使用大型语音语言模型(SLMs)进行风格扩散和对抗训练,实现了人级别的 TTS 合成。它通过扩散... -
 EarkindEarkind是一个通过结合语言模型和神经表达文本转语音技术,生成播客节目描述的平台。它使用新闻和研究论文列表来自动生成完整的播客剧集描述,同时提供有...
EarkindEarkind是一个通过结合语言模型和神经表达文本转语音技术,生成播客节目描述的平台。它使用新闻和研究论文列表来自动生成完整的播客剧集描述,同时提供有... -
 SpeechGPTSpeechGPT是一种多模态语言模型,具有内在的跨模态对话能力。它能够感知并生成多模态内容,遵循多模态人类指令。SpeechGPT-Gen是一种扩展...
SpeechGPTSpeechGPT是一种多模态语言模型,具有内在的跨模态对话能力。它能够感知并生成多模态内容,遵循多模态人类指令。SpeechGPT-Gen是一种扩展... -
 WhisperFusionWhisperFusion是一款基于WhisperLive和WhisperSpeech功能的产品,通过在实时语音转文字流程中集成Mistral大型语言...
WhisperFusionWhisperFusion是一款基于WhisperLive和WhisperSpeech功能的产品,通过在实时语音转文字流程中集成Mistral大型语言... -
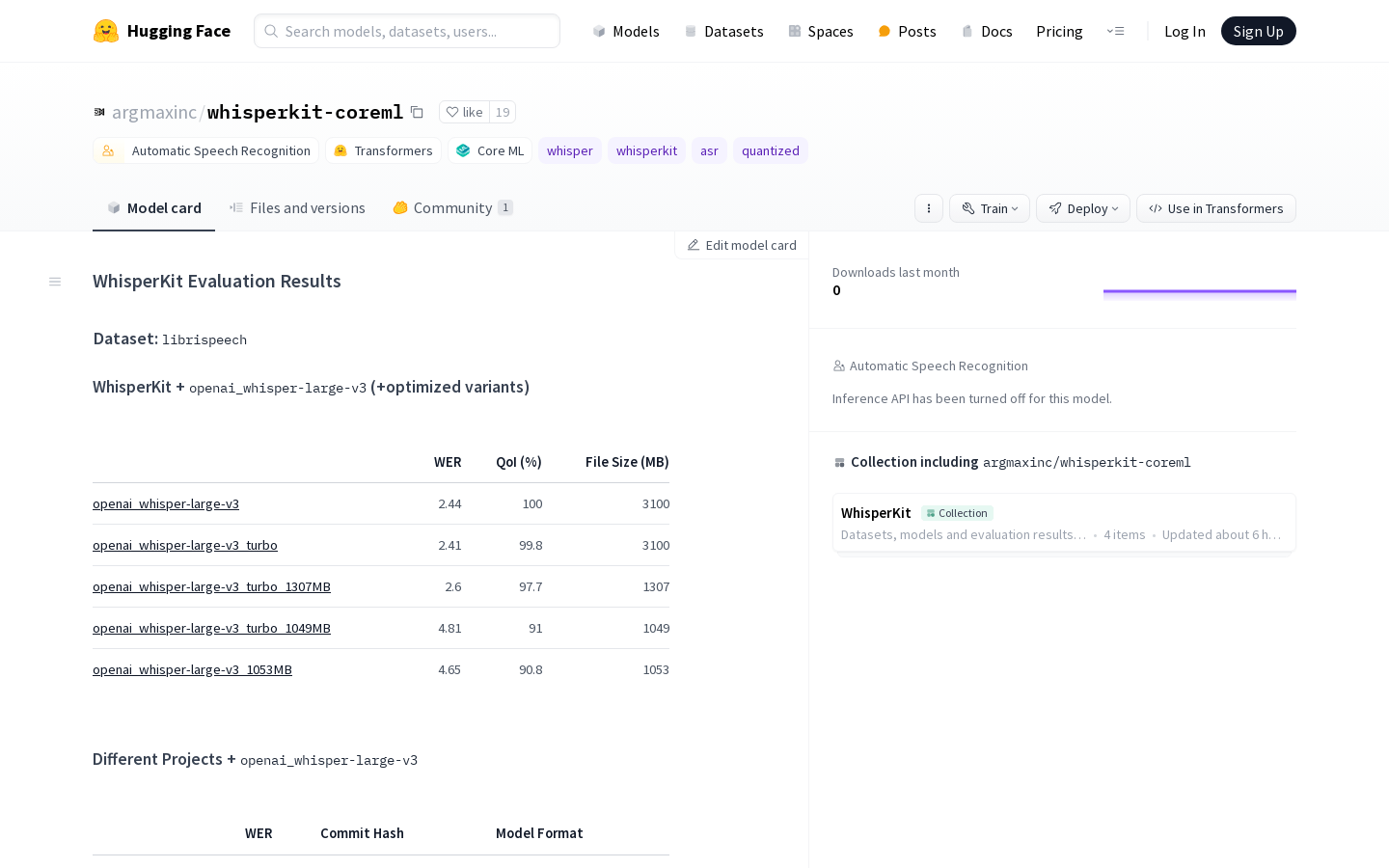 WhisperKitWhisperKit是一个用于自动语音识别模型压缩与优化的工具。它支持对模型进行压缩和优化,并提供了详细的性能评估数据。WhisperKit还提供了针...
WhisperKitWhisperKit是一个用于自动语音识别模型压缩与优化的工具。它支持对模型进行压缩和优化,并提供了详细的性能评估数据。WhisperKit还提供了针... -
 BASE TTSBASE TTS是亚马逊开发的大规模文本到语音合成模型,运用了10亿参数的自动回归转换器,可将文本转换成语音代码,再通过卷积解码器生成语音波形。该模型...
BASE TTSBASE TTS是亚马逊开发的大规模文本到语音合成模型,运用了10亿参数的自动回归转换器,可将文本转换成语音代码,再通过卷积解码器生成语音波形。该模型... -
 VSP-LLMVSP-LLM是一个结合视觉语音处理(Visual Speech Processing)与大型语言模型(LLMs)的框架,旨在通过LLMs的强大能力最...
VSP-LLMVSP-LLM是一个结合视觉语音处理(Visual Speech Processing)与大型语言模型(LLMs)的框架,旨在通过LLMs的强大能力最... -
 PolarisPolaris是由Hippocratic AI 开发的一款高度专注于安全、用于医疗保健的大语言模型(LLM)系统,通过星座架构和专业支持代理组合,能够...
PolarisPolaris是由Hippocratic AI 开发的一款高度专注于安全、用于医疗保健的大语言模型(LLM)系统,通过星座架构和专业支持代理组合,能够... -
 ApplioApplio是一个开源生态系统,主要提供先进的AI语音克隆技术。它的主要优点是创新性、开放源代码和先进的AI语音克隆技术。Applio的背景信息是作为...
ApplioApplio是一个开源生态系统,主要提供先进的AI语音克隆技术。它的主要优点是创新性、开放源代码和先进的AI语音克隆技术。Applio的背景信息是作为... -
 Azure 认知服务语音Azure 认知服务语音是微软推出的一款语音识别与合成服务,支持超过100种语言和方言的语音转文本和文本转语音功能。它通过创建可处理特定术语、背景噪音...
Azure 认知服务语音Azure 认知服务语音是微软推出的一款语音识别与合成服务,支持超过100种语言和方言的语音转文本和文本转语音功能。它通过创建可处理特定术语、背景噪音... -
 SpeechGPT2SpeechGPT2是由复旦大学计算机科学学院开发的端到端语音对话语言模型,能够感知并表达情感,并根据上下文和人类指令以多种风格提供合适的语音响应。该...
SpeechGPT2SpeechGPT2是由复旦大学计算机科学学院开发的端到端语音对话语言模型,能够感知并表达情感,并根据上下文和人类指令以多种风格提供合适的语音响应。该... -
 LlamaVoiceLlamaVoice是一个基于羊驼模型的大型语音生成模型,它通过直接预测连续特征,提供了一种与传统依赖于离散语音码预测的向量量化模型相比更为流畅和高效...
LlamaVoiceLlamaVoice是一个基于羊驼模型的大型语音生成模型,它通过直接预测连续特征,提供了一种与传统依赖于离散语音码预测的向量量化模型相比更为流畅和高效... -
 Seed-ASRSeed-ASR是由字节跳动公司开发的基于大型语言模型(Large Language Model, LLM)的语音识别模型。它通过将连续的语音表示和上...
Seed-ASRSeed-ASR是由字节跳动公司开发的基于大型语言模型(Large Language Model, LLM)的语音识别模型。它通过将连续的语音表示和上... -
 Easy Voice ToolkitEasy Voice Toolkit是一个基于开源语音项目的AI语音工具箱,提供包括语音模型训练在内的多种自动化音频工具。该工具箱能够无缝集成,形成完...
Easy Voice ToolkitEasy Voice Toolkit是一个基于开源语音项目的AI语音工具箱,提供包括语音模型训练在内的多种自动化音频工具。该工具箱能够无缝集成,形成完... -
 OptiSpeechOptiSpeech是一个高效、轻量级且快速的文本到语音模型,专为设备端文本到语音转换设计。它利用了先进的深度学习技术,能够将文本转换为自然听起来的语...
OptiSpeechOptiSpeech是一个高效、轻量级且快速的文本到语音模型,专为设备端文本到语音转换设计。它利用了先进的深度学习技术,能够将文本转换为自然听起来的语... -
 LLaMA-OmniLLaMA-Omni是一个基于Llama-3.1-8B-Instruct构建的低延迟、高质量的端到端语音交互模型,旨在实现GPT-4o级别的语音能力。...
LLaMA-OmniLLaMA-Omni是一个基于Llama-3.1-8B-Instruct构建的低延迟、高质量的端到端语音交互模型,旨在实现GPT-4o级别的语音能力。... -
 讯飞虚拟人讯飞虚拟人利用最新的AI虚拟形象技术,结合语音识别、语义理解、语音合成、NLP、星火大模型等AI核心技术,提供虚拟人形象资产构建、AI驱动、多模态交互...
讯飞虚拟人讯飞虚拟人利用最新的AI虚拟形象技术,结合语音识别、语义理解、语音合成、NLP、星火大模型等AI核心技术,提供虚拟人形象资产构建、AI驱动、多模态交互...
AI爱好者的一站式人工智能AI工具箱,累计收录全球10,000⁺好用的AI工具软件和网站,方便您更便捷的探索前沿的AI技术。本站持续更新好的AI应用,力争做全球排名前三的AI网址导航网站,欢迎您成为我们的一员。
